Импорт текстового файла с разделителями табуляции в openrefine
У меня есть.txt файл среднего размера с разделителями табуляции - около 40 тыс. Строк. Когда я импортирую в Openrefine, строка 406 помещает все остальное содержимое - целые 40000 строк в одну ячейку в столбце 13 этой строки.
Я пробовал grep-serching невидимых в двух разных текстовых редакторах (Sublime Text 2 и TextWrangler), и все выглядит так, как должно.
Я также пытался использовать Excel для преобразования в CSV, и это на самом деле работает, но:
- это неумелый обходной путь,
- у него проблемы с диакритическими знаками, и
- В любом случае я не хочу тратить больше времени на его решение в Excel
Я попытался исключить оскорбительную строку с 10 строками с каждой стороны, и это бросает ту же проблему.
Вот эти 21 строка, скопированные непосредственно из TextWrangler. (Я могу скопировать с терминала вывода, если это имеет какое-либо значение.)
Любая помощь, как всегда, очень ценится!
2 ответа
Понимаю. Проблема связана с кавычками. Попробуйте импортировать файл, сняв флажок "Кавычки используются для включения ячеек, содержащих разделители столбцов".
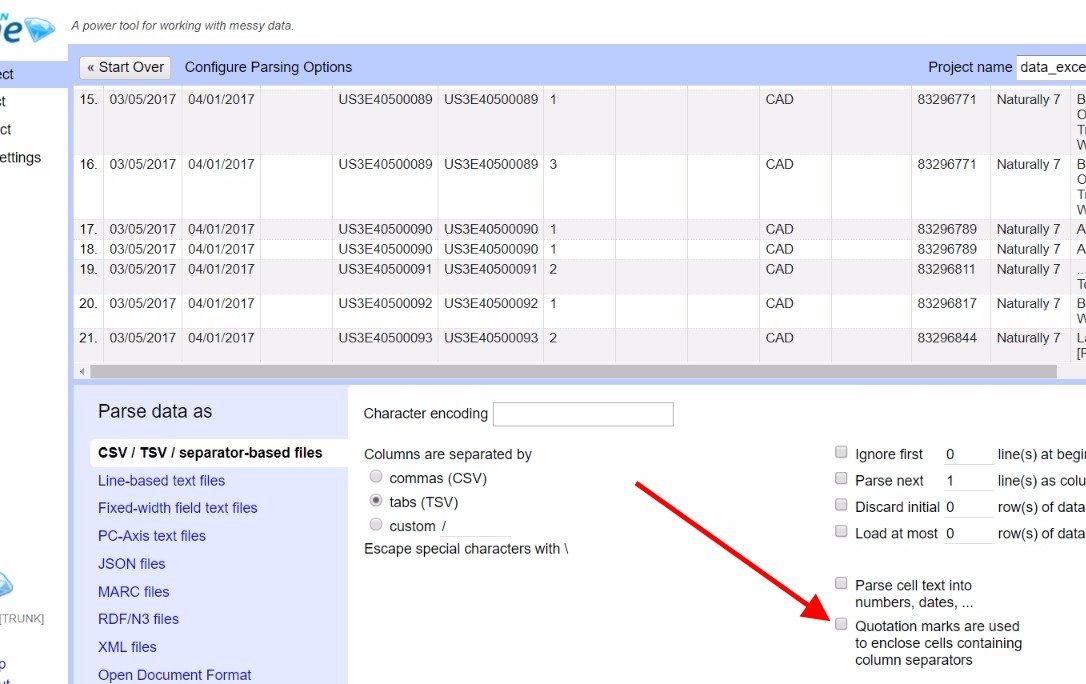
Пустые столбцы на моем скриншоте связаны с тем, что в вашем файле иногда есть две или три вкладки в качестве разделителя. Вы можете легко удалить их после импорта, используя "переупорядочить / удалить столбцы"
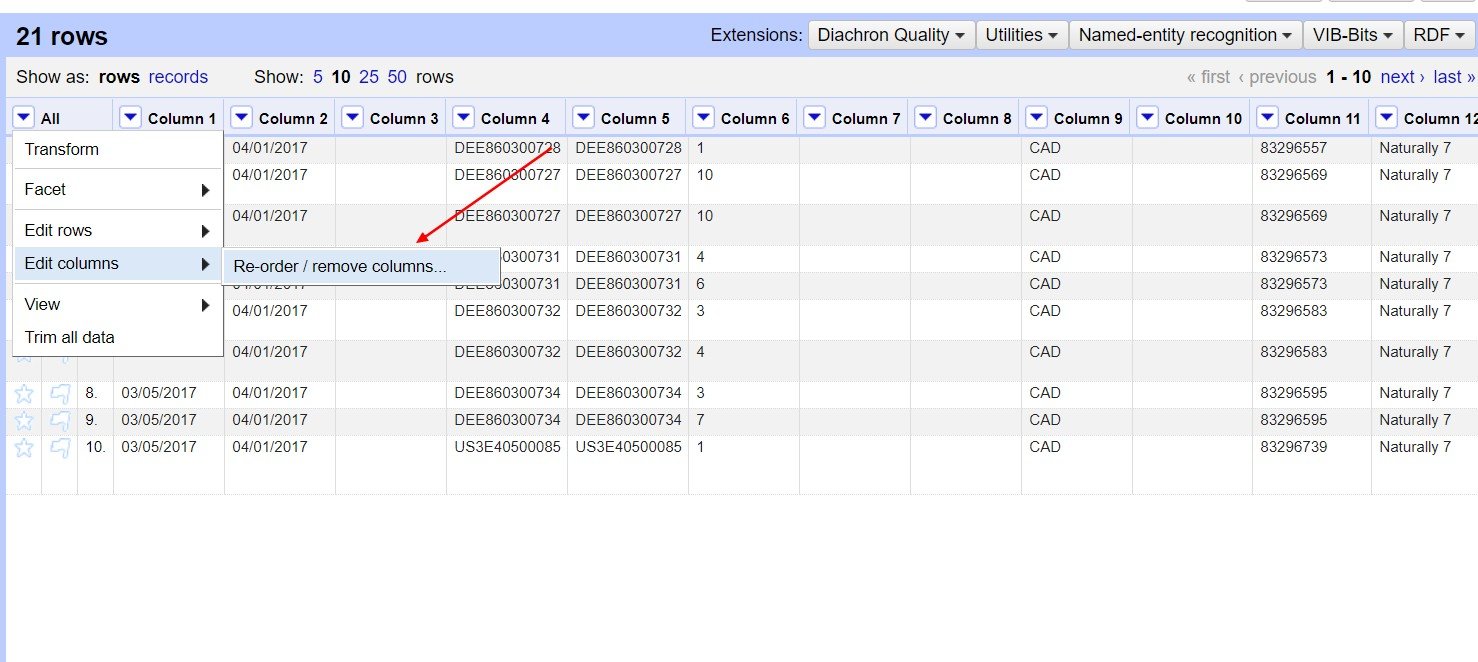
Решил это! Ну вроде как. Оказывается, что в столбце 13 был текст, который содержал двойные кавычки внутри самого текста (другими словами, вообще не имел отношения к разделителям).
Сейчас я просто собираюсь удалить эти кавычки во всем файле, и это работает - я проверял это. ** Я бы предпочел выяснить, как сохранить кавычки как часть текста. Пытался убежать от них с помощью /, но это не сработало.
Спасибо, Сообщество. Особенно @Ettore.