Calling Java/Scala function from a task
Фон
My original question here was Why using DecisionTreeModel.predict inside map function raises an exception? and is related to How to generate tuples of (original lable, predicted label) on Spark with MLlib?
When we use Scala API a recommended way of getting predictions for RDD[LabeledPoint]с помощьюDecisionTreeModelis to simply map overRDD:
val labelAndPreds = testData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
Unfortunately similar approach in PySpark doesn't work so well:
labelsAndPredictions = testData.map(
lambda lp: (lp.label, model.predict(lp.features))
labelsAndPredictions.first()
Exception: It appears that you are attempting to reference SparkContext from a broadcast variable, action, or transforamtion. SparkContext может использоваться только в драйвере, а не в коде, который он запускает на рабочих. For more information, see SPARK-5063.
Instead of that official documentation recommends something like this:
predictions = model.predict(testData.map(lambda x: x.features))
labelsAndPredictions = testData.map(lambda lp: lp.label).zip(predictions)
и так, что здесь происходит? There is no broadcast variable here and Scala API definespredictследующее:
/**
* Predict values for a single data point using the model trained.
*
* @param features array representing a single data point
* @return Double prediction from the trained model
*/
def predict(features: Vector): Double = {
topNode.predict(features)
}
/**
* Predict values for the given data set using the model trained.
*
* @param features RDD representing data points to be predicted
* @return RDD of predictions for each of the given data points
*/
def predict(features: RDD[Vector]): RDD[Double] = {
features.map(x => predict(x))
}
so at least at the first glance calling from action or transformation is not a problem since prediction seems to be a local operation.
объяснение
After some digging I figured out that the source of the problem is aJavaModelWrapper.call method invoked from DecisionTreeModel.predict. It access SparkContext which is required to call Java function:
callJavaFunc(self._sc, getattr(self._java_model, name), *a)
Вопрос
В случае DecisionTreeModel.predict there is a recommended workaround and all the required code is already a part of the Scala API but is there any elegant way to handle problem like this in general?
Only solutions I can think of right now are rather heavyweight:
- pushing everything down to JVM either by extending Spark classes through Implicit Conversions or adding some kind of wrappers
- using Py4j gateway directly
1 ответ
Связь с использованием шлюза Py4J по умолчанию просто невозможна. Чтобы понять, почему мы должны взглянуть на следующую диаграмму из документа PySpark Internals [1]:
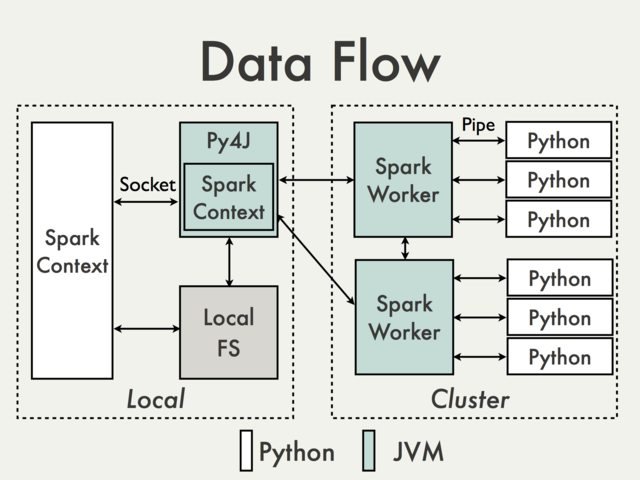
Поскольку шлюз Py4J работает на драйвере, он не доступен для интерпретаторов Python, которые взаимодействуют с работниками JVM через сокеты (см., Например, PythonRDD / rdd.py).
Теоретически возможно создать отдельный шлюз Py4J для каждого работника, но на практике это вряд ли будет полезно. Игнорирование таких вопросов, как надежность Py4J просто не предназначен для выполнения задач, требующих больших объемов данных.
Есть ли обходные пути?
Использование API-интерфейса Spark SQL Sources для переноса кода JVM.
Плюсы: поддерживается, высокий уровень, не требует доступа к внутреннему API PySpark
Минусы: относительно подробный и не очень хорошо задокументированный, ограниченный в основном входными данными
Работа на DataFrames с использованием Scala UDF.
Плюсы: Простота реализации (см. Spark: Как сопоставить Python с пользовательскими функциями Scala или Java?), Нет преобразования данных между Python и Scala, если данные уже хранятся в DataFrame, минимальный доступ к Py4J
Минусы: требуется доступ к шлюзу Py4J и внутренним методам, ограничивается Spark SQL, трудно отлаживать, не поддерживается
Создание высокоуровневого интерфейса Scala аналогично тому, как это делается в MLlib.
Плюсы: гибкость, возможность выполнения произвольного сложного кода. Его можно надевать либо непосредственно на RDD (см., Например, обертки модели MLlib), либо с
DataFrames(см. Как использовать класс Scala внутри Pyspark). Последнее решение кажется гораздо более дружественным, поскольку все детали ser-de уже обрабатываются существующим API.Минусы: низкий уровень, требуется преобразование данных, так же, как UDF требует доступа к Py4J и внутреннему API, не поддерживается
Некоторые основные примеры можно найти в Transforming PySpark RDD с Scala
Использование инструмента управления внешним рабочим процессом для переключения между заданиями Python и Scala / Java и передачи данных в DFS.
Плюсы: простота реализации, минимальные изменения в самом коде
Минусы: стоимость чтения / записи данных ( Alluxio?)
Использование общих
SQLContext(см., например, Apache Zeppelin или Livy) для передачи данных между гостевыми языками с использованием зарегистрированных временных таблиц.Плюсы: хорошо подходит для интерактивного анализа
Минусы: Не так много для пакетных заданий (Zeppelin) или может потребоваться дополнительная оркестровка (Livy)
- Джошуа Розен (2014, 04 августа) PySpark Internals. Получено с https://cwiki.apache.org/confluence/display/SPARK/PySpark+Internals