Р: Правила ассоциации (arules) не пишут никаких правил - мой набор данных слишком мал?
Я прочитал Stack и различную документацию онлайн, и я все еще не заставляю это работать.
У меня есть набор данных 5,368 транзакций. Они представляют собой лист Excel с несколькими различными столбцами - CustomerID, ItemID и OrderID (см. Ниже, данные поступают так, как показано в A1:C10).
У меня есть 3 вопроса:
В каком конкретно формате должны быть данные? Я попытался прочитать его, используя все 3 формата, показанные ниже. Я могу получить read.transaction для чтения данных в любом из этих форматов, но когда я запускаю apriori, он просто дает мне 1 правило (а иногда и нет). Даже для того, чтобы получить это единственное правило, я должен установить достоверность 0,01, а lhs всегда пусто.
При последней попытке я использовал формат, показанный в строке 21. Я даже вырезал все отдельные транзакции (строки 23 и 24). Затем я запустил этот синтаксис:
sb<-read.transactions(file = "~/Downloads/sbasket.csv",sep = ",")
Я думаю, что я даже пытался:
sb<-read.transactions(file = "~/Downloads/sbasket.csv", format="single",sep=",", cols=c(1,2))
- Насколько большим должен быть ваш набор данных? Мой набор данных состоит из 5 368 строк, из которых только 366 содержат несколько транзакций (поэтому большинство строк в данных аналогичны строке 6 ниже), поэтому примерно только 7% моих общих данных имеют несколько корзин элементов. Поэтому я не получаю никаких правил? Вот почему я пытался исключить все заказы из одной корзины, но даже это не помогло.
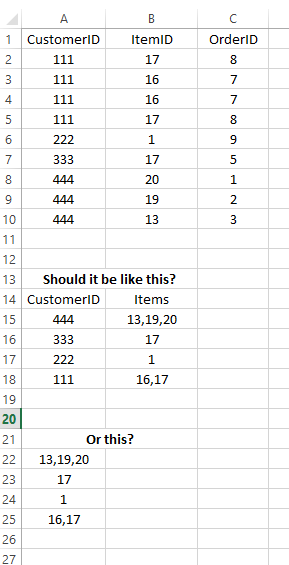
2 ответа
Я ничего не знаю о "arules", но возможно ли проблема в том, что он ожидает CSV, а вы загружаете таблицу Excel? Может быть, попробуйте использовать пакет 'openxlsx', чтобы сначала прочитать файл, а затем ввести его в read.transactions?
arules можно читать в формате 1 и 3. Используйте summary(sb) чтобы убедиться, что элементы читаются правильно. Вот пример для вашего формата 3:
trans_txt <- "13,19,20\n17\n1,\n16,17"
write(trans_txt, file = "trans.txt")
library("arules")
trans <- read.transactions("trans.txt", sep = ",")
summary(trans)
transactions as itemMatrix in sparse format with
4 rows (elements/itemsets/transactions) and
6 columns (items) and a density of 0.2916667
most frequent items:
17 1 13 16 19 (Other)
2 1 1 1 1 1
element (itemset/transaction) length distribution:
sizes
1 2 3
2 1 1
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 1.00 1.50 1.75 2.25 3.00
includes extended item information - examples:
labels
1 1
2 13
3 16
rules <- apriori(trans)
inspect(rules)
lhs rhs support confidence lift count
[1] {16} => {17} 0.25 1 2 1
[2] {19} => {20} 0.25 1 4 1
[3] {20} => {19} 0.25 1 4 1
[4] {19} => {13} 0.25 1 4 1
[5] {13} => {19} 0.25 1 4 1
[6] {20} => {13} 0.25 1 4 1
[7] {13} => {20} 0.25 1 4 1
[8] {19,20} => {13} 0.25 1 4 1
[9] {13,19} => {20} 0.25 1 4 1
[10] {13,20} => {19} 0.25 1 4 1