2D KD Tree и поиск ближайшего соседа
В настоящее время я реализую KD Tree и поиск ближайшего соседа, следуя алгоритму, описанному здесь: http://ldots.org/kdtree/
Я сталкивался с несколькими различными способами реализации дерева KD: один, в котором точки хранятся во внутренних узлах, и один, в котором они хранятся только в конечных узлах. Поскольку у меня есть очень простой вариант использования (все, что мне нужно сделать, - это построить дерево один раз, его не нужно изменять), я остановился на листовом подходе, который, казалось, был проще реализовать. Я успешно все реализовал, дерево всегда строится успешно, и в большинстве случаев поиск ближайшего соседа возвращает правильное значение. Однако у меня есть некоторые проблемы, связанные с тем, что с некоторыми наборами данных и точками поиска алгоритм возвращает неверное значение. Рассмотрим моменты:
[[6, 1], [5, 5], [9, 6], [3, 81], [4, 9], [4, 0], [7, 9], [2, 9], [6, 74]]
Который создает дерево, похожее на это (извините за мои плохие схемы):
Где узлы квадратного листа - это те, которые содержат точки, а круглые узлы содержат медианное значение для разделения списка на этой глубине. При вызове моего ближайшего соседа ищите по этому набору данных и ищите ближайшего соседа для [6, 74]алгоритм возвращает [7, 9], Хотя это правильно следует алгоритму, на самом деле это не самая близкая точка к [6, 74], Ближайшая точка на самом деле будет [3, 81] который находится на расстоянии 7,6, [7, 9] находится на расстоянии 65.
Вот точки, для наглядности представленные красной точкой, для которой я пытаюсь найти ближайшего соседа:
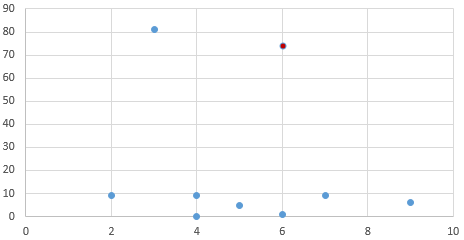
Если это поможет, мой метод поиска выглядит следующим образом:
private LeafNode search(int depth, Point point, KDNode node) {
if(node instanceof LeafNode)
return (LeafNode)node;
else {
MedianNode medianNode = (MedianNode) node;
double meanValue = medianNode.getValue();
double comparisonValue = 0;
if(valueEven(depth)) {
comparisonValue = point.getX();
}
else {
comparisonValue = point.getY();
}
KDNode nextNode;
if(comparisonValue < meanValue) {
if (node.getLeft() != null)
nextNode = node.getLeft();
else
nextNode = node.getRight();
}
else {
if (node.getRight() != null)
nextNode = node.getRight();
else
nextNode = node.getLeft();
}
return search(depth + 1, point, nextNode);
}
}
Итак, мои вопросы:
Это то, что ожидать от поиска ближайшего соседа в дереве KD, или я должен получить самую близкую точку к точке, которую я ищу (так как это моя единственная причина для использования дерева)?
Это проблема только с этой формой KD Tree, я должен изменить это, чтобы сохранить точки во внутренних узлах, чтобы решить это?
2 ответа
Корректная реализация KD-дерева всегда находит ближайшую точку (не имеет значения, хранятся ли точки только в листьях или нет). Ваш метод поиска не является правильным, хотя. Вот как это должно выглядеть:
bestDistance = INF
def getClosest(node, point)
if node is null
return
// I will assume that this node splits points
// by their x coordinate for the sake of brevity.
if node is a leaf
// updateAnswer updates bestDistance value
// and keeps track of the closest point to the given one.
updateAnswer(node.point, point)
else
middleX = node.median
if point.x < middleX
getClosest(node.left, point)
if node.right.minX - point.x < bestDistance
getClosest(node.right, point)
else
getClosest(node.right, point)
if point.x - node.left.maxX < bestDistance
getClosest(node.left, point)
Объяснение, данное на ldots.org, просто неверно (наряду со многими другими лучшими результатами Google по поиску KD Trees).
См. /questions/31182200/blizhajshij-sosed-derevo-kd-dokazatelstvo-vikipedii/31182210#31182210 для правильной реализации.
Не уверен, что этот ответ по-прежнему актуален, но в любом случае осмелюсь предложить следующую реализацию kd-tree: https://github.com/stanislav-antonov/kdtree
Реализация достаточно проста и может быть полезна в том случае, если кто-то решил разобраться, как все работает на практике.
Что касается способа построения дерева, используется итеративный подход, поэтому его размер ограничен объемом памяти, а не размером стека.