Кодировка метки в нескольких столбцах в scikit-learn
Я пытаюсь использовать Scikit-Learn's LabelEncoder кодировать панд DataFrame строковых меток. Поскольку в фрейме данных много (более 50) столбцов, я хочу избежать создания LabelEncoder объект для каждого столбца; Я бы предпочел просто один большой LabelEncoder объекты, которые работают во всех моих столбцах данных.
Бросать весь DataFrame в LabelEncoder создает приведенную ниже ошибку. Пожалуйста, имейте в виду, что я использую фиктивные данные здесь; на самом деле я имею в виду около 50 столбцов данных, помеченных строками, поэтому мне нужно решение, которое не ссылается ни на один столбец по имени.
import pandas
from sklearn import preprocessing
df = pandas.DataFrame({
'pets': ['cat', 'dog', 'cat', 'monkey', 'dog', 'dog'],
'owner': ['Champ', 'Ron', 'Brick', 'Champ', 'Veronica', 'Ron'],
'location': ['San_Diego', 'New_York', 'New_York', 'San_Diego', 'San_Diego',
'New_York']
})
le = preprocessing.LabelEncoder()
le.fit(df)
Traceback (последний вызов был последним): файл "", строка 1, в файле "/Users/bbalin/anaconda/lib/python2.7/site-packages/sklearn/preprocessing/label.py", строка 103, в соответствии y = column_or_1d(y, warn=True) Файл "/Users/bbalin/anaconda/lib/python2.7/site-packages/sklearn/utils/validation.py", строка 306, в column_or_1d повышает ValueError("неверная форма ввода {0}". Format(shape)) ValueError: неправильная форма ввода (6, 3)
Есть мысли о том, как обойти эту проблему?
25 ответов
Вы можете легко сделать это, хотя,
df.apply(LabelEncoder().fit_transform)
РЕДАКТИРОВАТЬ:
Так как этот ответ более года назад и вызвал много голосов (включая награду), я, вероятно, должен расширить это.
Для inverse_transform и transform вам придется немного взломать.
from collections import defaultdict
d = defaultdict(LabelEncoder)
При этом вы теперь сохраните все столбцы LabelEncoder как словарь.
# Encoding the variable
fit = df.apply(lambda x: d[x.name].fit_transform(x))
# Inverse the encoded
fit.apply(lambda x: d[x.name].inverse_transform(x))
# Using the dictionary to label future data
df.apply(lambda x: d[x.name].transform(x))
Как упомянуто larsmans, LabelEncoder () принимает только 1-й массив в качестве аргумента. Тем не менее, довольно легко свернуть свой собственный кодировщик меток, который работает с несколькими столбцами по вашему выбору и возвращает преобразованный фрейм данных. Мой код здесь частично основан на отличном сообщении Zac Stewart, найденном здесь.
Создание пользовательского кодировщика включает в себя просто создание класса, который отвечает на fit(), transform(), а также fit_transform() методы. В вашем случае хорошим началом может быть что-то вроде этого:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.pipeline import Pipeline
# Create some toy data in a Pandas dataframe
fruit_data = pd.DataFrame({
'fruit': ['apple','orange','pear','orange'],
'color': ['red','orange','green','green'],
'weight': [5,6,3,4]
})
class MultiColumnLabelEncoder:
def __init__(self,columns = None):
self.columns = columns # array of column names to encode
def fit(self,X,y=None):
return self # not relevant here
def transform(self,X):
'''
Transforms columns of X specified in self.columns using
LabelEncoder(). If no columns specified, transforms all
columns in X.
'''
output = X.copy()
if self.columns is not None:
for col in self.columns:
output[col] = LabelEncoder().fit_transform(output[col])
else:
for colname,col in output.iteritems():
output[colname] = LabelEncoder().fit_transform(col)
return output
def fit_transform(self,X,y=None):
return self.fit(X,y).transform(X)
Предположим, мы хотим закодировать два наших категориальных атрибута (fruit а также color), оставляя числовой атрибут weight в одиночестве. Мы могли бы сделать это следующим образом:
MultiColumnLabelEncoder(columns = ['fruit','color']).fit_transform(fruit_data)
Что превращает наш fruit_data набор данных из
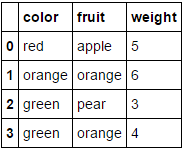 в
в
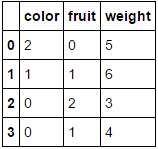
Передав ему фрейм данных, состоящий целиком из категориальных переменных и опускающий columns Параметр приведет к тому, что каждый столбец будет закодирован (что, я считаю, именно то, что вы изначально искали)
MultiColumnLabelEncoder().fit_transform(fruit_data.drop('weight',axis=1))
Это превращает
 в
в
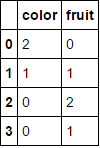 ,
,
Обратите внимание, что он, вероятно, захлебнется, когда попытается закодировать уже числовые атрибуты (добавьте некоторый код для обработки этого, если хотите).
Еще одна приятная особенность в том, что мы можем использовать этот специальный преобразователь в конвейере:
encoding_pipeline = Pipeline([
('encoding',MultiColumnLabelEncoder(columns=['fruit','color']))
# add more pipeline steps as needed
])
encoding_pipeline.fit_transform(fruit_data)
Так как Scikit-Learn 0,20 вы можете использовать sklearn.compose.ColumnTransformer а также sklearn.preprocessing.OneHotEncoder:
Если у вас есть только категориальные переменные, OneHotEncoder непосредственно:
from sklearn.preprocessing import OneHotEncoder
OneHotEncoder(handle_unknown='ignore').fit_transform(df)
Если у вас есть гетерогенно типизированные функции:
from sklearn.compose import make_column_transformer
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import OneHotEncoder
categorical_columns = ['pets', 'owner', 'location']
numerical_columns = ['age', 'weigth', 'height']
column_trans = make_column_transformer(
(categorical_columns, OneHotEncoder(handle_unknown='ignore'),
(numerical_columns, RobustScaler())
column_trans.fit_transform(df)
Дополнительные параметры в документации: http://scikit-learn.org/stable/modules/compose.html
Нам не нужен LabelEncoder.
Вы можете преобразовать столбцы в категории и затем получить их коды. Я использовал понимание словаря ниже, чтобы применить этот процесс к каждому столбцу и обернуть результат обратно в кадр данных той же формы с идентичными индексами и именами столбцов.
>>> pd.DataFrame({col: df[col].astype('category').cat.codes for col in df}, index=df.index)
location owner pets
0 1 1 0
1 0 2 1
2 0 0 0
3 1 1 2
4 1 3 1
5 0 2 1
Чтобы создать словарь сопоставления, вы можете просто перечислить категории, используя словарь:
>>> {col: {n: cat for n, cat in enumerate(df[col].astype('category').cat.categories)}
for col in df}
{'location': {0: 'New_York', 1: 'San_Diego'},
'owner': {0: 'Brick', 1: 'Champ', 2: 'Ron', 3: 'Veronica'},
'pets': {0: 'cat', 1: 'dog', 2: 'monkey'}}
Это через полтора года после свершившегося факта, но мне тоже нужно было уметь .transform() несколько столбцов панд данных в кадре одновременно (и иметь возможность .inverse_transform() их тоже). Это распространяется на превосходное предложение @PriceHardman выше:
class MultiColumnLabelEncoder(LabelEncoder):
"""
Wraps sklearn LabelEncoder functionality for use on multiple columns of a
pandas dataframe.
"""
def __init__(self, columns=None):
self.columns = columns
def fit(self, dframe):
"""
Fit label encoder to pandas columns.
Access individual column classes via indexig `self.all_classes_`
Access individual column encoders via indexing
`self.all_encoders_`
"""
# if columns are provided, iterate through and get `classes_`
if self.columns is not None:
# ndarray to hold LabelEncoder().classes_ for each
# column; should match the shape of specified `columns`
self.all_classes_ = np.ndarray(shape=self.columns.shape,
dtype=object)
self.all_encoders_ = np.ndarray(shape=self.columns.shape,
dtype=object)
for idx, column in enumerate(self.columns):
# fit LabelEncoder to get `classes_` for the column
le = LabelEncoder()
le.fit(dframe.loc[:, column].values)
# append the `classes_` to our ndarray container
self.all_classes_[idx] = (column,
np.array(le.classes_.tolist(),
dtype=object))
# append this column's encoder
self.all_encoders_[idx] = le
else:
# no columns specified; assume all are to be encoded
self.columns = dframe.iloc[:, :].columns
self.all_classes_ = np.ndarray(shape=self.columns.shape,
dtype=object)
for idx, column in enumerate(self.columns):
le = LabelEncoder()
le.fit(dframe.loc[:, column].values)
self.all_classes_[idx] = (column,
np.array(le.classes_.tolist(),
dtype=object))
self.all_encoders_[idx] = le
return self
def fit_transform(self, dframe):
"""
Fit label encoder and return encoded labels.
Access individual column classes via indexing
`self.all_classes_`
Access individual column encoders via indexing
`self.all_encoders_`
Access individual column encoded labels via indexing
`self.all_labels_`
"""
# if columns are provided, iterate through and get `classes_`
if self.columns is not None:
# ndarray to hold LabelEncoder().classes_ for each
# column; should match the shape of specified `columns`
self.all_classes_ = np.ndarray(shape=self.columns.shape,
dtype=object)
self.all_encoders_ = np.ndarray(shape=self.columns.shape,
dtype=object)
self.all_labels_ = np.ndarray(shape=self.columns.shape,
dtype=object)
for idx, column in enumerate(self.columns):
# instantiate LabelEncoder
le = LabelEncoder()
# fit and transform labels in the column
dframe.loc[:, column] =\
le.fit_transform(dframe.loc[:, column].values)
# append the `classes_` to our ndarray container
self.all_classes_[idx] = (column,
np.array(le.classes_.tolist(),
dtype=object))
self.all_encoders_[idx] = le
self.all_labels_[idx] = le
else:
# no columns specified; assume all are to be encoded
self.columns = dframe.iloc[:, :].columns
self.all_classes_ = np.ndarray(shape=self.columns.shape,
dtype=object)
for idx, column in enumerate(self.columns):
le = LabelEncoder()
dframe.loc[:, column] = le.fit_transform(
dframe.loc[:, column].values)
self.all_classes_[idx] = (column,
np.array(le.classes_.tolist(),
dtype=object))
self.all_encoders_[idx] = le
return dframe
def transform(self, dframe):
"""
Transform labels to normalized encoding.
"""
if self.columns is not None:
for idx, column in enumerate(self.columns):
dframe.loc[:, column] = self.all_encoders_[
idx].transform(dframe.loc[:, column].values)
else:
self.columns = dframe.iloc[:, :].columns
for idx, column in enumerate(self.columns):
dframe.loc[:, column] = self.all_encoders_[idx]\
.transform(dframe.loc[:, column].values)
return dframe.loc[:, self.columns].values
def inverse_transform(self, dframe):
"""
Transform labels back to original encoding.
"""
if self.columns is not None:
for idx, column in enumerate(self.columns):
dframe.loc[:, column] = self.all_encoders_[idx]\
.inverse_transform(dframe.loc[:, column].values)
else:
self.columns = dframe.iloc[:, :].columns
for idx, column in enumerate(self.columns):
dframe.loc[:, column] = self.all_encoders_[idx]\
.inverse_transform(dframe.loc[:, column].values)
return dframe
Пример:
Если df а также df_copy() смешанного типа pandas данные кадры, вы можете применить MultiColumnLabelEncoder() к dtype=object столбцы следующим образом:
# get `object` columns
df_object_columns = df.iloc[:, :].select_dtypes(include=['object']).columns
df_copy_object_columns = df_copy.iloc[:, :].select_dtypes(include=['object'].columns
# instantiate `MultiColumnLabelEncoder`
mcle = MultiColumnLabelEncoder(columns=object_columns)
# fit to `df` data
mcle.fit(df)
# transform the `df` data
mcle.transform(df)
# returns output like below
array([[1, 0, 0, ..., 1, 1, 0],
[0, 5, 1, ..., 1, 1, 2],
[1, 1, 1, ..., 1, 1, 2],
...,
[3, 5, 1, ..., 1, 1, 2],
# transform `df_copy` data
mcle.transform(df_copy)
# returns output like below (assuming the respective columns
# of `df_copy` contain the same unique values as that particular
# column in `df`
array([[1, 0, 0, ..., 1, 1, 0],
[0, 5, 1, ..., 1, 1, 2],
[1, 1, 1, ..., 1, 1, 2],
...,
[3, 5, 1, ..., 1, 1, 2],
# inverse `df` data
mcle.inverse_transform(df)
# outputs data like below
array([['August', 'Friday', '2013', ..., 'N', 'N', 'CA'],
['April', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['August', 'Monday', '2014', ..., 'N', 'N', 'NJ'],
...,
['February', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['April', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['March', 'Tuesday', '2013', ..., 'N', 'N', 'NJ']], dtype=object)
# inverse `df_copy` data
mcle.inverse_transform(df_copy)
# outputs data like below
array([['August', 'Friday', '2013', ..., 'N', 'N', 'CA'],
['April', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['August', 'Monday', '2014', ..., 'N', 'N', 'NJ'],
...,
['February', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['April', 'Tuesday', '2014', ..., 'N', 'N', 'NJ'],
['March', 'Tuesday', '2013', ..., 'N', 'N', 'NJ']], dtype=object)
Вы можете получить доступ к отдельным классам столбцов, меткам столбцов и кодировщикам столбцов, используемым для подгонки каждого столбца, с помощью индексации:
mcle.all_classes_mcle.all_encoders_mcle.all_labels_
Это не дает прямого ответа на ваш вопрос (на что у Напутипулу Джона и ПрайсХардмана фантастические ответы)
Тем не менее, для целей нескольких задач классификации и т. Д. Вы можете использовать
pandas.get_dummies(input_df)
это может вводить фрейм данных с категориальными данными и возвращать фрейм данных с двоичными значениями. значения переменных кодируются в имена столбцов в результирующем кадре данных. Больше
Все это можно сделать непосредственно в пандах и хорошо подходит для уникальной способности replace метод.
Во-первых, давайте создадим словарь словарей, отображающих столбцы и их значения в новые замещающие значения.
transform_dict = {}
for col in df.columns:
cats = pd.Categorical(df[col]).categories
d = {}
for i, cat in enumerate(cats):
d[cat] = i
transform_dict[col] = d
transform_dict
{'location': {'New_York': 0, 'San_Diego': 1},
'owner': {'Brick': 0, 'Champ': 1, 'Ron': 2, 'Veronica': 3},
'pets': {'cat': 0, 'dog': 1, 'monkey': 2}}
Поскольку это всегда будет сопоставление один к одному, мы можем инвертировать внутренний словарь, чтобы получить сопоставление новых значений обратно оригиналу.
inverse_transform_dict = {}
for col, d in transform_dict.items():
inverse_transform_dict[col] = {v:k for k, v in d.items()}
inverse_transform_dict
{'location': {0: 'New_York', 1: 'San_Diego'},
'owner': {0: 'Brick', 1: 'Champ', 2: 'Ron', 3: 'Veronica'},
'pets': {0: 'cat', 1: 'dog', 2: 'monkey'}}
Теперь мы можем использовать уникальную способность replace метод, чтобы взять вложенный список словарей и использовать внешние ключи в качестве столбцов, а внутренние ключи в качестве значений, которые мы хотели бы заменить.
df.replace(transform_dict)
location owner pets
0 1 1 0
1 0 2 1
2 0 0 0
3 1 1 2
4 1 3 1
5 0 2 1
Мы можем легко вернуться к оригиналу, снова цепочки replace метод
df.replace(transform_dict).replace(inverse_transform_dict)
location owner pets
0 San_Diego Champ cat
1 New_York Ron dog
2 New_York Brick cat
3 San_Diego Champ monkey
4 San_Diego Veronica dog
5 New_York Ron dog
Предполагая, что вы просто пытаетесь получить sklearn.preprocessing.LabelEncoder() объект, который можно использовать для представления ваших столбцов, все что вам нужно сделать, это:
le.fit(df.columns)
В приведенном выше коде у вас будет уникальный номер, соответствующий каждому столбцу. Точнее, у вас будет 1:1 отображение df.columns в le.transform(df.columns.get_values()), Чтобы получить кодировку столбца, просто передайте его le.transform(...), Например, следующий код получит кодировку для каждого столбца:
le.transform(df.columns.get_values())
Предполагая, что вы хотите создать sklearn.preprocessing.LabelEncoder() Объект для всех ваших меток строк вы можете сделать следующее:
le.fit([y for x in df.get_values() for y in x])
В этом случае, скорее всего, у вас есть неуникальные метки строк (как показано в вашем вопросе). Чтобы увидеть, какие классы создал кодер, вы можете сделать le.classes_, Вы заметите, что это должно иметь те же элементы, что и в set(y for x in df.get_values() for y in x), Еще раз для преобразования метки строки в закодированную метку используйте le.transform(...), Например, если вы хотите получить метку для первого столбца в df.columns массив и первый ряд, вы можете сделать это:
le.transform([df.get_value(0, df.columns[0])])
Вопрос, который вы задали в своем комментарии, немного сложнее, но все еще может быть решен:
le.fit([str(z) for z in set((x[0], y) for x in df.iteritems() for y in x[1])])
Приведенный выше код выполняет следующие действия:
- Составьте уникальную комбинацию всех пар (столбец, строка)
- Представлять каждую пару как строковую версию кортежа. Это обходной путь для преодоления
LabelEncoderкласс не поддерживает кортежи в качестве имени класса. - Подходит новинки к
LabelEncoder,
Теперь использовать эту новую модель немного сложнее. Предполагая, что мы хотим извлечь представление для того же элемента, который мы искали в предыдущем примере (первый столбец в df.columns и первая строка), мы можем сделать это:
le.transform([str((df.columns[0], df.get_value(0, df.columns[0])))])
Помните, что каждый поиск теперь является строковым представлением кортежа, который содержит (столбец, строку).
Нет, LabelEncoder не делает этого Он принимает 1-й массив меток класса и создает 1-й массив. Он предназначен для обработки меток классов в задачах классификации, а не произвольных данных, и любая попытка использовать его в других целях потребует кода для преобразования фактической проблемы в проблему, которую она решает (и решение обратно в исходное пространство).
Вот сценарий
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
col_list = df.select_dtypes(include = "object").columns
for colsn in col_list:
df[colsn] = le.fit_transform(df[colsn].astype(str))
Я проверил исходный код ( https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/preprocessing/label.py) LabelEncoder. Он был основан на наборе преобразований numpy, одним из которых является np.unique(). И эта функция принимает только 1-й массив ввода. (поправьте меня, если я ошибаюсь).
Очень грубые идеи... сначала определите, для каких столбцов нужен LabelEncoder, а затем переберите каждый столбец.
def cat_var(df):
"""Identify categorical features.
Parameters
----------
df: original df after missing operations
Returns
-------
cat_var_df: summary df with col index and col name for all categorical vars
"""
col_type = df.dtypes
col_names = list(df)
cat_var_index = [i for i, x in enumerate(col_type) if x=='object']
cat_var_name = [x for i, x in enumerate(col_names) if i in cat_var_index]
cat_var_df = pd.DataFrame({'cat_ind': cat_var_index,
'cat_name': cat_var_name})
return cat_var_df
from sklearn.preprocessing import LabelEncoder
def column_encoder(df, cat_var_list):
"""Encoding categorical feature in the dataframe
Parameters
----------
df: input dataframe
cat_var_list: categorical feature index and name, from cat_var function
Return
------
df: new dataframe where categorical features are encoded
label_list: classes_ attribute for all encoded features
"""
label_list = []
cat_var_df = cat_var(df)
cat_list = cat_var_df.loc[:, 'cat_name']
for index, cat_feature in enumerate(cat_list):
le = LabelEncoder()
le.fit(df.loc[:, cat_feature])
label_list.append(list(le.classes_))
df.loc[:, cat_feature] = le.transform(df.loc[:, cat_feature])
return df, label_list
Возвращенный df будет после кодировки, и label_list покажет вам, что все эти значения означают в соответствующем столбце. Это фрагмент из сценария обработки данных, который я написал для работы. Дайте мне знать, если вы думаете, что может быть дальнейшее улучшение.
РЕДАКТИРОВАТЬ: Просто хочу упомянуть здесь, что методы выше работают с фреймом данных, не пропуская лучшее. Не уверен, как он работает, чтобы фрейм данных содержал недостающие данные. (Я имел дело с отсутствующей процедурой перед выполнением вышеуказанных методов)
Если у вас есть числовые и категориальные данные обоих типов в фрейме данных, вы можете использовать: здесь X - мой фрейм данных, имеющий категориальные и числовые обе переменные
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
for i in range(0,X.shape[1]):
if X.dtypes[i]=='object':
X[X.columns[i]] = le.fit_transform(X[X.columns[i]])
Примечание: этот метод хорош, если вы не заинтересованы в конвертации их обратно.
После долгих поисков и экспериментов с некоторыми ответами здесь и в других местах, я думаю, что ваш ответ здесь:
pd.DataFrame (columns = df.columns, data = LabelEncoder (). fit_transform (df.values.flatten ()). reshape (df.shape))
Это сохранит имена категорий в столбцах:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame([['A','B','C','D','E','F','G','I','K','H'],
['A','E','H','F','G','I','K','','',''],
['A','C','I','F','H','G','','','','']],
columns=['A1', 'A2', 'A3','A4', 'A5', 'A6', 'A7', 'A8', 'A9', 'A10'])
pd.DataFrame(columns=df.columns, data=LabelEncoder().fit_transform(df.values.flatten()).reshape(df.shape))
A1 A2 A3 A4 A5 A6 A7 A8 A9 A10
0 1 2 3 4 5 6 7 9 10 8
1 1 5 8 6 7 9 10 0 0 0
2 1 3 9 6 8 7 0 0 0 0
Короткий путь к LabelEncoder() несколько столбцов с dict():
from sklearn.preprocessing import LabelEncoder
le_dict = {col: LabelEncoder() for col in columns }
for col in columns:
le_dict[col].fit_transform(df[col])
и вы можете использовать это le_dict для маркировки закодировать любой другой столбец:
le_dict[col].transform(df_another[col])
Вместо
LabelEncoder мы можем использовать
OrdinalEncoder из scikit learn, который позволяет кодировать несколько столбцов.
Кодируйте категориальные признаки как целочисленный массив. Вход в этот преобразователь должен быть массивом целых чисел или строк, обозначающих значения, принимаемые категориальными (дискретными) функциями. Функции преобразуются в порядковые целые числа. В результате получается один столбец целых чисел (от 0 до n_categories - 1) для каждой функции.
>>> from sklearn.preprocessing import OrdinalEncoder
>>> enc = OrdinalEncoder()
>>> X = [['Male', 1], ['Female', 3], ['Female', 2]]
>>> enc.fit(X)
OrdinalEncoder()
>>> enc.categories_
[array(['Female', 'Male'], dtype=object), array([1, 2, 3], dtype=object)]
>>> enc.transform([['Female', 3], ['Male', 1]])
array([[0., 2.],
[1., 0.]])
И описание, и пример были скопированы со страницы документации, которую вы можете найти здесь:
Использование Neuraxle
TL; DR; Здесь вы можете использовать класс- оболочку FlattenForEach, чтобы просто преобразовать ваш df, например:
FlattenForEach(LabelEncoder(), then_unflatten=True).fit_transform(df).
С помощью этого метода кодировщик этикеток сможет соответствовать и преобразовывать в рамках обычного конвейера scikit-learn. Давайте просто импортируем:
from sklearn.preprocessing import LabelEncoder
from neuraxle.steps.column_transformer import ColumnTransformer
from neuraxle.steps.loop import FlattenForEach
Тот же общий кодировщик для столбцов:
Вот как один общий LabelEncoder будет применяться ко всем данным для их кодирования:
p = FlattenForEach(LabelEncoder(), then_unflatten=True)
Результат:
p, predicted_output = p.fit_transform(df.values)
expected_output = np.array([
[6, 7, 6, 8, 7, 7],
[1, 3, 0, 1, 5, 3],
[4, 2, 2, 4, 4, 2]
]).transpose()
assert np.array_equal(predicted_output, expected_output)
Разные кодировщики на столбец:
И вот как первый автономный LabelEncoder будет применяться к домашним животным, а второй будет использоваться владельцем столбца и его местоположением. Итак, чтобы быть точным, у нас здесь есть сочетание разных кодировщиков общих меток:
p = ColumnTransformer([
# A different encoder will be used for column 0 with name "pets":
(0, FlattenForEach(LabelEncoder(), then_unflatten=True)),
# A shared encoder will be used for column 1 and 2, "owner" and "location":
([1, 2], FlattenForEach(LabelEncoder(), then_unflatten=True)),
], n_dimension=2)
Результат:
p, predicted_output = p.fit_transform(df.values)
expected_output = np.array([
[0, 1, 0, 2, 1, 1],
[1, 3, 0, 1, 5, 3],
[4, 2, 2, 4, 4, 2]
]).transpose()
assert np.array_equal(predicted_output, expected_output)
Следуя комментариям по поводу решения @PriceHardman, я бы предложил следующую версию класса:
class LabelEncodingColoumns(BaseEstimator, TransformerMixin):
def __init__(self, cols=None):
pdu._is_cols_input_valid(cols)
self.cols = cols
self.les = {col: LabelEncoder() for col in cols}
self._is_fitted = False
def transform(self, df, **transform_params):
"""
Scaling ``cols`` of ``df`` using the fitting
Parameters
----------
df : DataFrame
DataFrame to be preprocessed
"""
if not self._is_fitted:
raise NotFittedError("Fitting was not preformed")
pdu._is_cols_subset_of_df_cols(self.cols, df)
df = df.copy()
label_enc_dict = {}
for col in self.cols:
label_enc_dict[col] = self.les[col].transform(df[col])
labelenc_cols = pd.DataFrame(label_enc_dict,
# The index of the resulting DataFrame should be assigned and
# equal to the one of the original DataFrame. Otherwise, upon
# concatenation NaNs will be introduced.
index=df.index
)
for col in self.cols:
df[col] = labelenc_cols[col]
return df
def fit(self, df, y=None, **fit_params):
"""
Fitting the preprocessing
Parameters
----------
df : DataFrame
Data to use for fitting.
In many cases, should be ``X_train``.
"""
pdu._is_cols_subset_of_df_cols(self.cols, df)
for col in self.cols:
self.les[col].fit(df[col])
self._is_fitted = True
return self
Этот класс подходит для энкодера на тренировочном наборе и использует адаптированную версию при трансформации. Первоначальную версию кода можно найти здесь.
В основном использовал ответ @Alexander, но пришлось внести некоторые изменения -
cols_need_mapped = ['col1', 'col2']
mapper = {col: {cat: n for n, cat in enumerate(df[col].astype('category').cat.categories)}
for col in df[cols_need_mapped]}
for c in cols_need_mapped :
df[c] = df[c].map(mapper[c])
Затем для повторного использования в будущем вы можете просто сохранить вывод в документ json, а когда вам это нужно, вы прочитаете его и используете .map() функционировать, как я делал выше.
Если у нас есть один столбец для кодирования меток и его обратного преобразования, то легко сделать это, когда в Python есть несколько столбцов
def stringtocategory(dataset):
'''
@author puja.sharma
@see The function label encodes the object type columns and gives label encoded and inverse tranform of the label encoded data
@param dataset dataframe on whoes column the label encoding has to be done
@return label encoded and inverse tranform of the label encoded data.
'''
data_original = dataset[:]
data_tranformed = dataset[:]
for y in dataset.columns:
#check the dtype of the column object type contains strings or chars
if (dataset[y].dtype == object):
print("The string type features are : " + y)
le = preprocessing.LabelEncoder()
le.fit(dataset[y].unique())
#label encoded data
data_tranformed[y] = le.transform(dataset[y])
#inverse label transform data
data_original[y] = le.inverse_transform(data_tranformed[y])
return data_tranformed,data_original
import pandas as pd
from sklearn.preprocessing import LabelEncoder
train=pd.read_csv('.../train.csv')
#X=train.loc[:,['waterpoint_type_group','status','waterpoint_type','source_class']].values
# Create a label encoder object
def MultiLabelEncoder(columnlist,dataframe):
for i in columnlist:
labelencoder_X=LabelEncoder()
dataframe[i]=labelencoder_X.fit_transform(dataframe[i])
columnlist=['waterpoint_type_group','status','waterpoint_type','source_class','source_type']
MultiLabelEncoder(columnlist,train)
Здесь я читаю CSV из местоположения, и в функции я передаю список столбцов, которые я хочу пометить, и фрейм данных, который я хочу применить.
Если у вас есть все функции объекта типа, тогда первый ответ, написанный выше, хорошо работает /questions/28655047/kodirovka-metki-v-neskolkih-stolbtsah-v-scikit-learn/28655064#28655064.
Но предположим, что у нас есть столбцы смешанного типа. Затем мы можем программно получить список имен функций типа объектный тип, а затем Label Encode.
#Fetch features of type Object
objFeatures = dataframe.select_dtypes(include="object").columns
#Iterate a loop for features of type object
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
for feat in objFeatures:
dataframe[feat] = le.fit_transform(dataframe[feat].astype(str))
dataframe.info()
Вот мое решение вашей проблемы. Чтобы преобразовать столбец фрейма данных, содержащий текст, в закодированные значения, просто используйте мою функцию text_to_numbers, она возвращает словарь LE. Ключ — это имя столбца, значением которого является столбец LabelEncoder() .
def text_to_numbers(df):
le_dict = dict()
for i in df.columns:
if df[i].dtype not in ["float64", "bool", "int64"]:
le_dict[i] = preprocessing.LabelEncoder()
df[i] = le_dict[i].fit_transform(df[i])
return df, le_dict
Приведенная ниже функция позволит сохранить исходный незакодированный кадр данных.
def numbers_to_text(df, le_dict):
for i in le_dict.keys():
df[i] = le_dict[i].inverse_transform(df[i])
return df
Вот мое решение для преобразования нескольких столбцов за один раз вместе с точным inverse_transformation
from sklearn import preprocessing
columns = ['buying','maint','lug_boot','safety','cls'] # columns names where transform is required
for X in columns:
exec(f'le_{X} = preprocessing.LabelEncoder()') #create label encoder with name "le_X", where X is column name
exec(f'df.{X} = le_{X}.fit_transform(df.{X})') #execute fit transform for column X with respective lable encoder "le_X", where X is column name
df.head() # to display transformed results
for X in columns:
exec(f'df.{X} = le_{X}.inverse_transform(df.{X})') #execute inverse_transform for column X with respective lable encoder "le_X", where X is column name
df.head() # to display Inverse transformed results of df
Проблема заключается в форме данных (pd dataframe), которые вы передаете в функцию подгонки. Вы должны пройти 1-й список.
Как насчет этого?
def MultiColumnLabelEncode(choice, columns, X):
LabelEncoders = []
if choice == 'encode':
for i in enumerate(columns):
LabelEncoders.append(LabelEncoder())
i=0
for cols in columns:
X[:, cols] = LabelEncoders[i].fit_transform(X[:, cols])
i += 1
elif choice == 'decode':
for cols in columns:
X[:, cols] = LabelEncoders[i].inverse_transform(X[:, cols])
i += 1
else:
print('Please select correct parameter "choice". Available parameters: encode/decode')
Он не самый эффективный, но работает и очень прост.