Извлечь данные из PDF
Пожалуйста, не отмечайте как дубликат. Я уже перебрал множество ссылок на Stackru, но они не решили мою проблему.
Что я пытаюсь сделать: мне нужно извлечь данные из примерно 1,50000 PDF-файлов.
Пример pdf: все эти pdf идентичны по структуре и содержат данные в табличном формате (без изображения). Снимок PDF выглядит следующим образом.

Что я сделал: я использовал pdf2htmlEX терминальная команда с Nodejs преобразовать PDF-файл в HTML.
var child_process = require('child_process');
var request = require('request');
var spawn = child_process.spawn;
var url = 'http://url_to_extract_data_from_pdf?Id=' + id; //id ranges from 1 to 1,50,000
var pdfFileStream = fs.createWriteStream(id + '.pdf');
request(url).pipe(pdfFileStream);
pdfFileStream.on('finish', function () {
console.log('Pdf file downloaded');
var pdfToHtml = spawn('pdf2htmlEX', [id + '.pdf']);
pdfToHtml.on('close', function () {
console.log('Pdf file converted to html');
jsdom.env({
url: "http://localhost:1000/" + id + ".html", //hard coded url for server -> current server running on localhost:1000
scripts: ["http://code.jquery.com/jquery.js"],
done: function (err, window) {
if(err)
console.log(err);
else {
var $ = window.$;
//jquery selectors to extract data
console.log($(".x14.y30").text().trim());
console.log($(".x15.y31").text().trim());
console.log($(".x16.y32").text().trim());
}
}
});
});
});
Преобразованный html-файл выглядит следующим образом: комбинация имени класса x с последующим символом и y с последующим символом была уникальной для определенного div. Например, был только один div с xf а также y10 учебный класс.
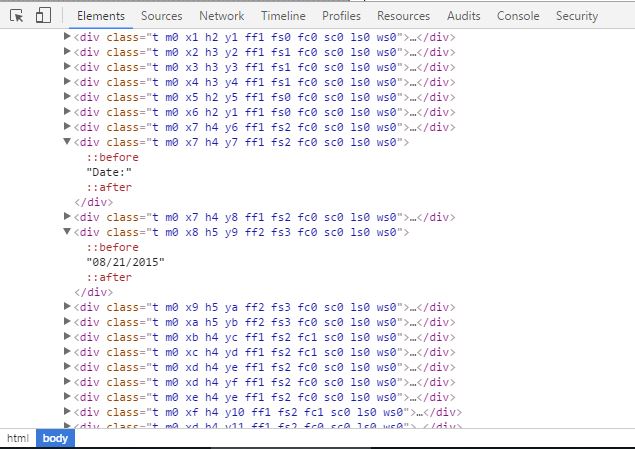
Где я застрял: хотя все PDF-файлы идентичны по формату и структуре, созданный HTML-файл не является. Так скажем $(".x14.y30").text() может быть, что-то мне дает в pdf - 1, это будет что-то другое в pdf - 2. Я также искал способ, которым я мог бы изменить способ назначения классов во время преобразования файла pdf в html. Но все напрасно. Извлеченные данные должны быть сохранены в формате табуляции.
Использование этого подхода не является обязательным. Любое лучшее предложение можно только приветствовать.