Разброс графиков в Pandas/Pyplot: Как построить график по категориям
Я пытаюсь создать простой график рассеяния в pyplot, используя объект Pandas DataFrame, но мне нужен эффективный способ построения двух переменных, но символы обозначаются третьим столбцом (ключ). Я пробовал различные способы использования df.groupby, но не успешно. Пример сценария df приведен ниже. Это окрашивает маркеры в соответствии с 'key1', но я хотел бы видеть легенду с категориями 'key1'. Я рядом? Благодарю.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(np.random.normal(10,1,30).reshape(10,3), index = pd.date_range('2010-01-01', freq = 'M', periods = 10), columns = ('one', 'two', 'three'))
df['key1'] = (4,4,4,6,6,6,8,8,8,8)
fig1 = plt.figure(1)
ax1 = fig1.add_subplot(111)
ax1.scatter(df['one'], df['two'], marker = 'o', c = df['key1'], alpha = 0.8)
plt.show()
6 ответов
Ты можешь использовать scatter для этого, но это требует наличия числовых значений для вашего key1и у вас не будет легенды, как вы заметили.
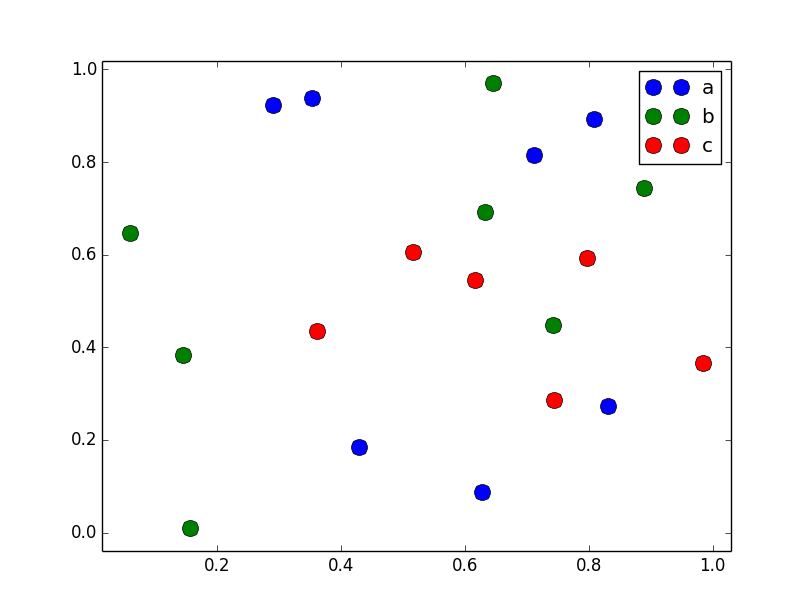
Лучше просто использовать plot для дискретных категорий, как это. Например:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
np.random.seed(1974)
# Generate Data
num = 20
x, y = np.random.random((2, num))
labels = np.random.choice(['a', 'b', 'c'], num)
df = pd.DataFrame(dict(x=x, y=y, label=labels))
groups = df.groupby('label')
# Plot
fig, ax = plt.subplots()
ax.margins(0.05) # Optional, just adds 5% padding to the autoscaling
for name, group in groups:
ax.plot(group.x, group.y, marker='o', linestyle='', ms=12, label=name)
ax.legend()
plt.show()
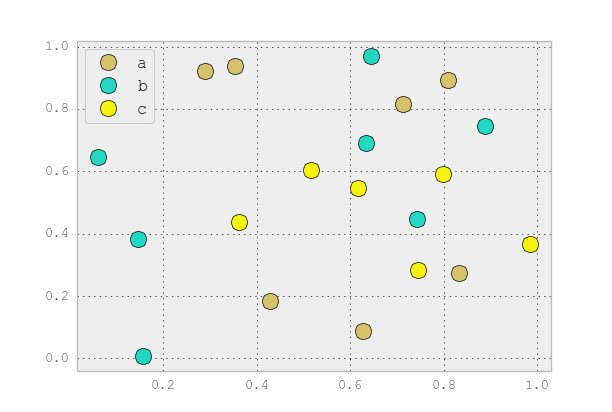
Если вы хотите, чтобы вещи выглядели по умолчанию pandas стиль, а затем просто обновить rcParams с таблицей стилей панд и использовать его генератор цветов. (Я тоже слегка подправляю легенду)
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
np.random.seed(1974)
# Generate Data
num = 20
x, y = np.random.random((2, num))
labels = np.random.choice(['a', 'b', 'c'], num)
df = pd.DataFrame(dict(x=x, y=y, label=labels))
groups = df.groupby('label')
# Plot
plt.rcParams.update(pd.tools.plotting.mpl_stylesheet)
colors = pd.tools.plotting._get_standard_colors(len(groups), color_type='random')
fig, ax = plt.subplots()
ax.set_color_cycle(colors)
ax.margins(0.05)
for name, group in groups:
ax.plot(group.x, group.y, marker='o', linestyle='', ms=12, label=name)
ax.legend(numpoints=1, loc='upper left')
plt.show()
Это просто сделать с Seaborn (pip install seaborn) как вкладчик
sns.pairplot(x_vars=["one"], y_vars=["two"], data=df, hue="key1", size=5):
import seaborn as sns
import pandas as pd
import numpy as np
np.random.seed(1974)
df = pd.DataFrame(
np.random.normal(10, 1, 30).reshape(10, 3),
index=pd.date_range('2010-01-01', freq='M', periods=10),
columns=('one', 'two', 'three'))
df['key1'] = (4, 4, 4, 6, 6, 6, 8, 8, 8, 8)
sns.pairplot(x_vars=["one"], y_vars=["two"], data=df, hue="key1", size=5)

Вот данные для справки:

Поскольку в ваших данных есть три переменных столбца, вы можете построить все попарные измерения с помощью:
sns.pairplot(vars=["one","two","three"], data=df, hue="key1", size=5)

https://rasbt.github.io/mlxtend/user_guide/plotting/category_scatter/ - еще один вариант.
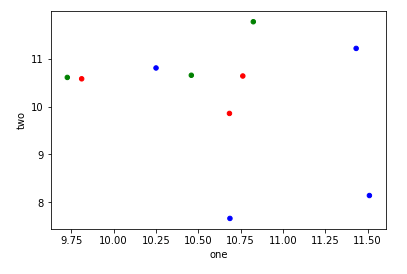
С plt.scatterЯ могу думать только об одном: использовать прокси-художника:
df = pd.DataFrame(np.random.normal(10,1,30).reshape(10,3), index = pd.date_range('2010-01-01', freq = 'M', periods = 10), columns = ('one', 'two', 'three'))
df['key1'] = (4,4,4,6,6,6,8,8,8,8)
fig1 = plt.figure(1)
ax1 = fig1.add_subplot(111)
x=ax1.scatter(df['one'], df['two'], marker = 'o', c = df['key1'], alpha = 0.8)
ccm=x.get_cmap()
circles=[Line2D(range(1), range(1), color='w', marker='o', markersize=10, markerfacecolor=item) for item in ccm((array([4,6,8])-4.0)/4)]
leg = plt.legend(circles, ['4','6','8'], loc = "center left", bbox_to_anchor = (1, 0.5), numpoints = 1)
И результат:

Вы можете использовать df.plot.scatter и передать массив аргументу c=, определяющему цвет каждой точки:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(np.random.normal(10,1,30).reshape(10,3), index = pd.date_range('2010-01-01', freq = 'M', periods = 10), columns = ('one', 'two', 'three'))
df['key1'] = (4,4,4,6,6,6,8,8,8,8)
colors = np.where(df["key1"]==4,'r','-')
colors[df["key1"]==6] = 'g'
colors[df["key1"]==8] = 'b'
print(colors)
df.plot.scatter(x="one",y="two",c=colors)
plt.show()
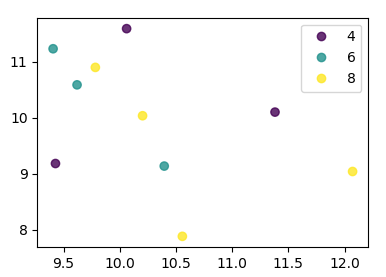
Начиная с matplotlib 3.1 и далее, вы можете использовать .legend_elements(). Пример показан в разделе Автоматическое создание легенды. Преимущество состоит в том, что можно использовать одиночный вызов scatter.
В этом случае:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(np.random.normal(10,1,30).reshape(10,3),
index = pd.date_range('2010-01-01', freq = 'M', periods = 10),
columns = ('one', 'two', 'three'))
df['key1'] = (4,4,4,6,6,6,8,8,8,8)
fig, ax = plt.subplots()
sc = ax.scatter(df['one'], df['two'], marker = 'o', c = df['key1'], alpha = 0.8)
ax.legend(*sc.legend_elements())
plt.show()
Если бы ключи не были указаны напрямую как числа, это выглядело бы как
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(np.random.normal(10,1,30).reshape(10,3),
index = pd.date_range('2010-01-01', freq = 'M', periods = 10),
columns = ('one', 'two', 'three'))
df['key1'] = list("AAABBBCCCC")
labels, index = np.unique(df["key1"], return_inverse=True)
fig, ax = plt.subplots()
sc = ax.scatter(df['one'], df['two'], marker = 'o', c = index, alpha = 0.8)
ax.legend(sc.legend_elements()[0], labels)
plt.show()
Вы также можете попробовать Altair или ggpot, которые ориентированы на декларативную визуализацию.
import numpy as np
import pandas as pd
np.random.seed(1974)
# Generate Data
num = 20
x, y = np.random.random((2, num))
labels = np.random.choice(['a', 'b', 'c'], num)
df = pd.DataFrame(dict(x=x, y=y, label=labels))
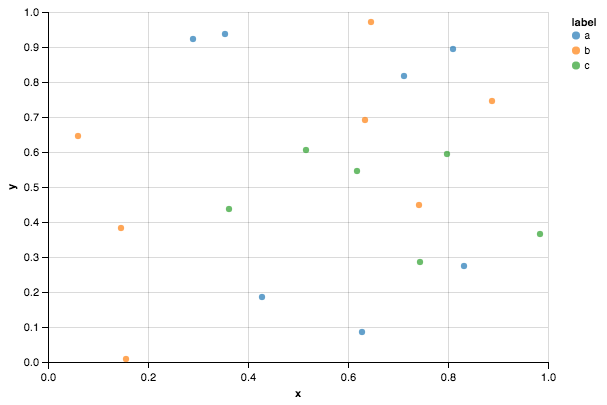
Альтаир код
from altair import Chart
c = Chart(df)
c.mark_circle().encode(x='x', y='y', color='label')
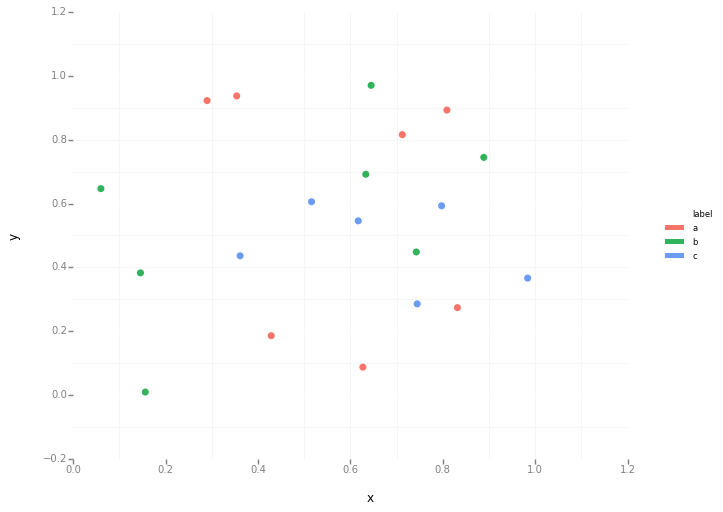
код ggplot
from ggplot import *
ggplot(aes(x='x', y='y', color='label'), data=df) +\
geom_point(size=50) +\
theme_bw()
Это довольно странно, но вы могли бы использовать one1 как Float64Index сделать все за один раз:
df.set_index('one').sort_index().groupby('key1')['two'].plot(style='--o', legend=True)
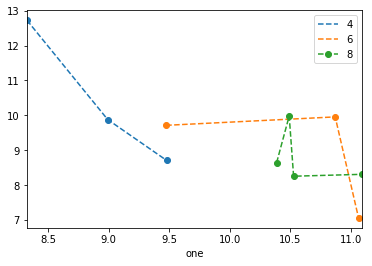
Обратите внимание, что с 0.20.3 сортировка индекса необходима, и легенда немного шаткая.
Seaborn имеет функцию обертки
scatterplot это делает это более эффективно.
sns.scatterplot(data = df, x = 'one', y = 'two', data = 'key1'])