Что такое _kmp_fork_barrier и как посмотреть, есть ли дисбаланс нагрузки?
Я использую Intel VTune Amplifier, чтобы увидеть, как масштабируется мое параллельное приложение.
Обратите внимание, я не использую какой-либо явный механизм блокировки
Он хорошо масштабируется на моем 4-ядерном ноутбуке (учитывая, что есть части алгоритма, которые нельзя распараллелить):
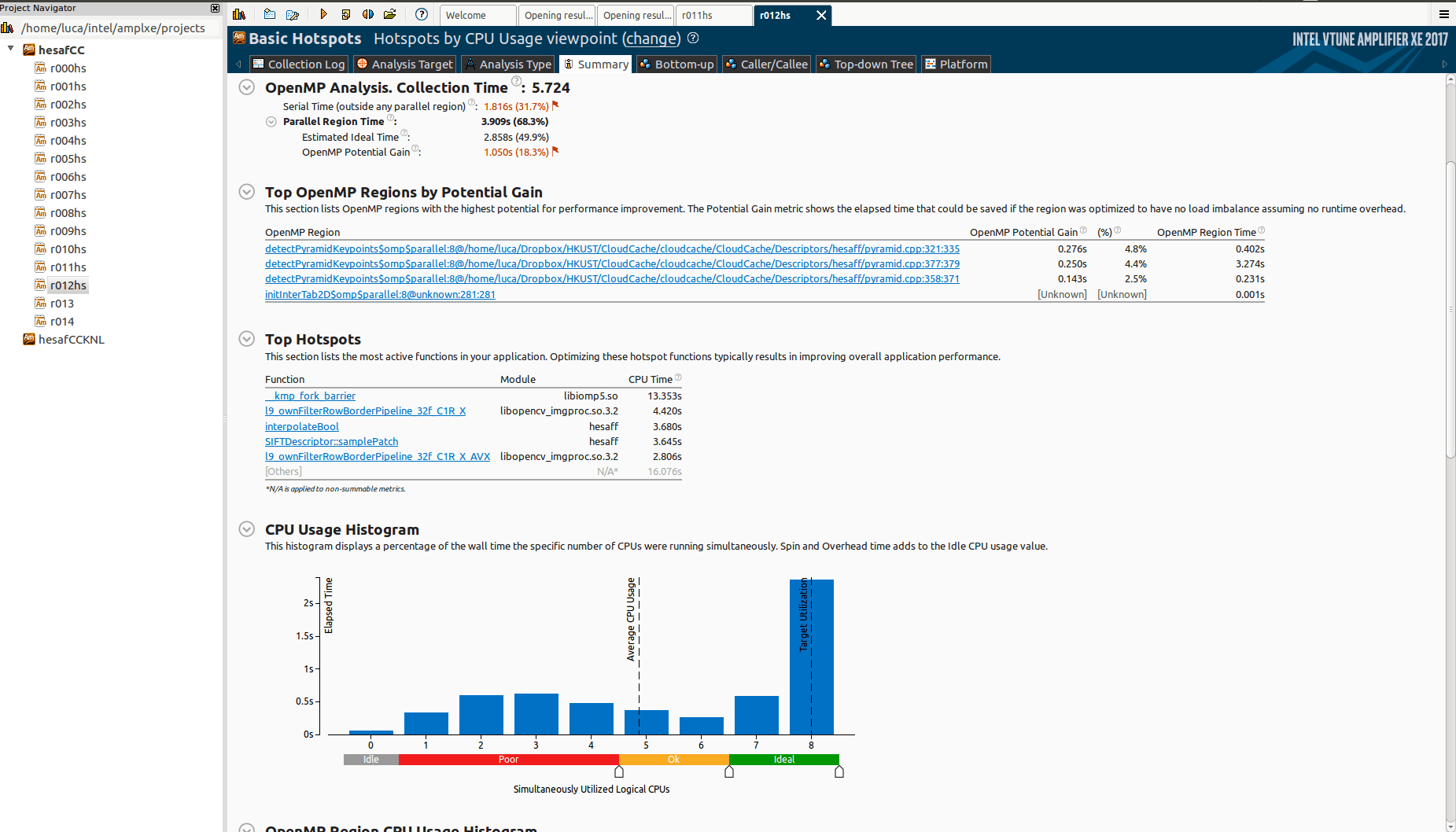
Тем не менее, когда я тестирую его на Knight Landing (KNL), он ужасно масштабируется:
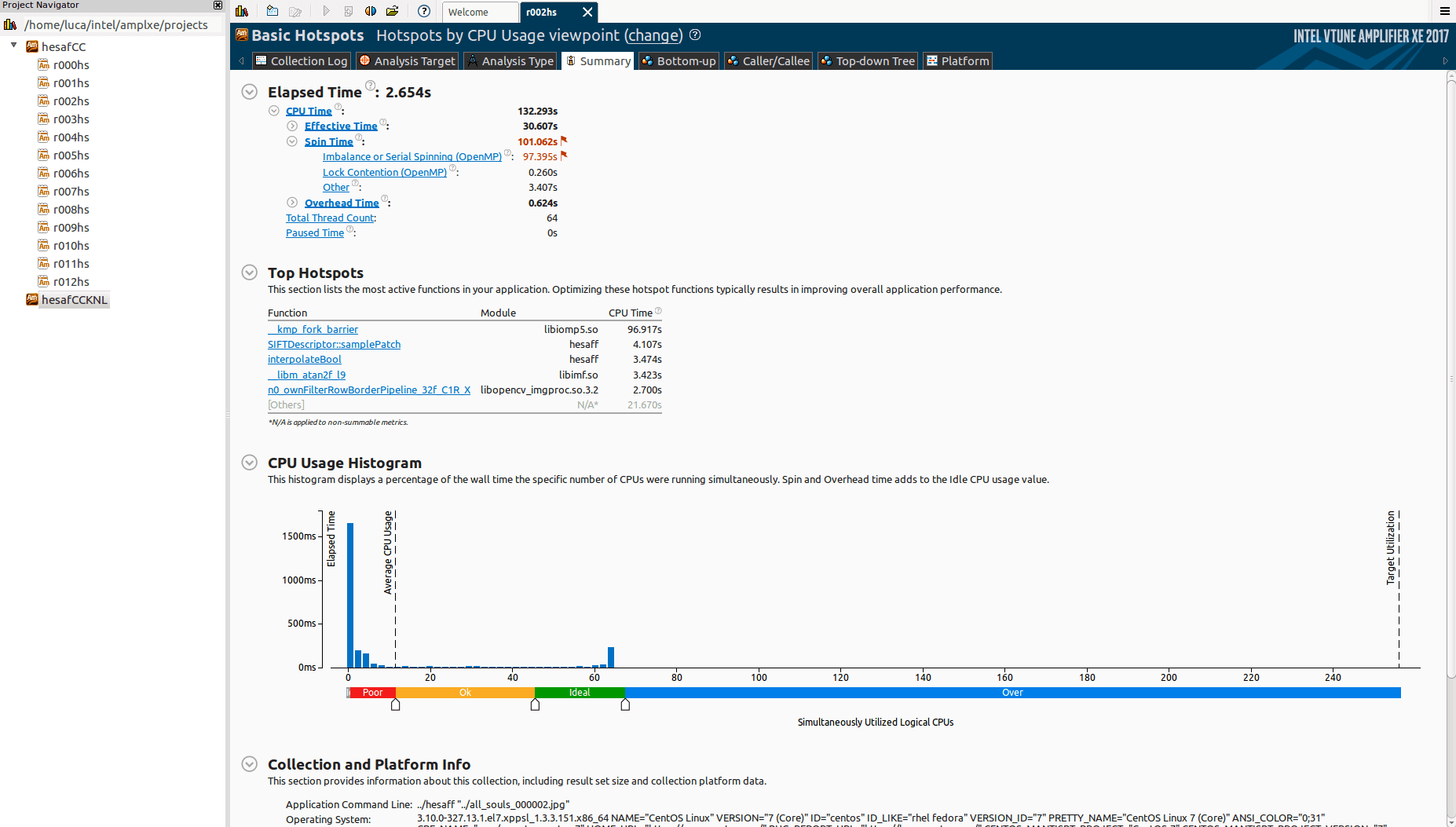
Обратите внимание, что я специально использую только 64 ядра (если говорить о том, что, если вас интересует сходство потоков, я открыл еще один вопрос по этой теме).
Почему так много простоя? И что _kmp_fork_barrier? Читая о дисбалансе или последовательном вращении (OpenMP), кажется, что речь идет о дисбалансе нагрузки, но я уже использую schedule(dynamic,1) в целом omp регионы.
Как я могу увидеть, действительно ли это дисбаланс нагрузки? Иначе, что может быть возможной причиной?
Обратите внимание, у меня есть 3 параллельных omp параллельных региона:
#pragma omp parallel for collapse(2) schedule(dynamic,1)
#pragma omp declare reduction(mergeFindAffineShapeArgs : std::vector<FindAffineShapeArgs> : omp_out.insert(omp_out.end(), omp_in.begin(), omp_in.end()))
#pragma omp parallel for collapse(2) schedule(dynamic,1) reduction(mergeFindAffineShapeArgs : findAffineShapeArgs)
#pragma omp declare reduction(mergeFindAffineShapeArgs : std::vector<FindAffineShapeArgs> : omp_out.insert(omp_out.end(), omp_in.begin(), omp_in.end()))
#pragma omp parallel for collapse(2) schedule(dynamic,1) reduction(mergeFindAffineShapeArgs : findAffineShapeArgs)
Это нижний раздел:
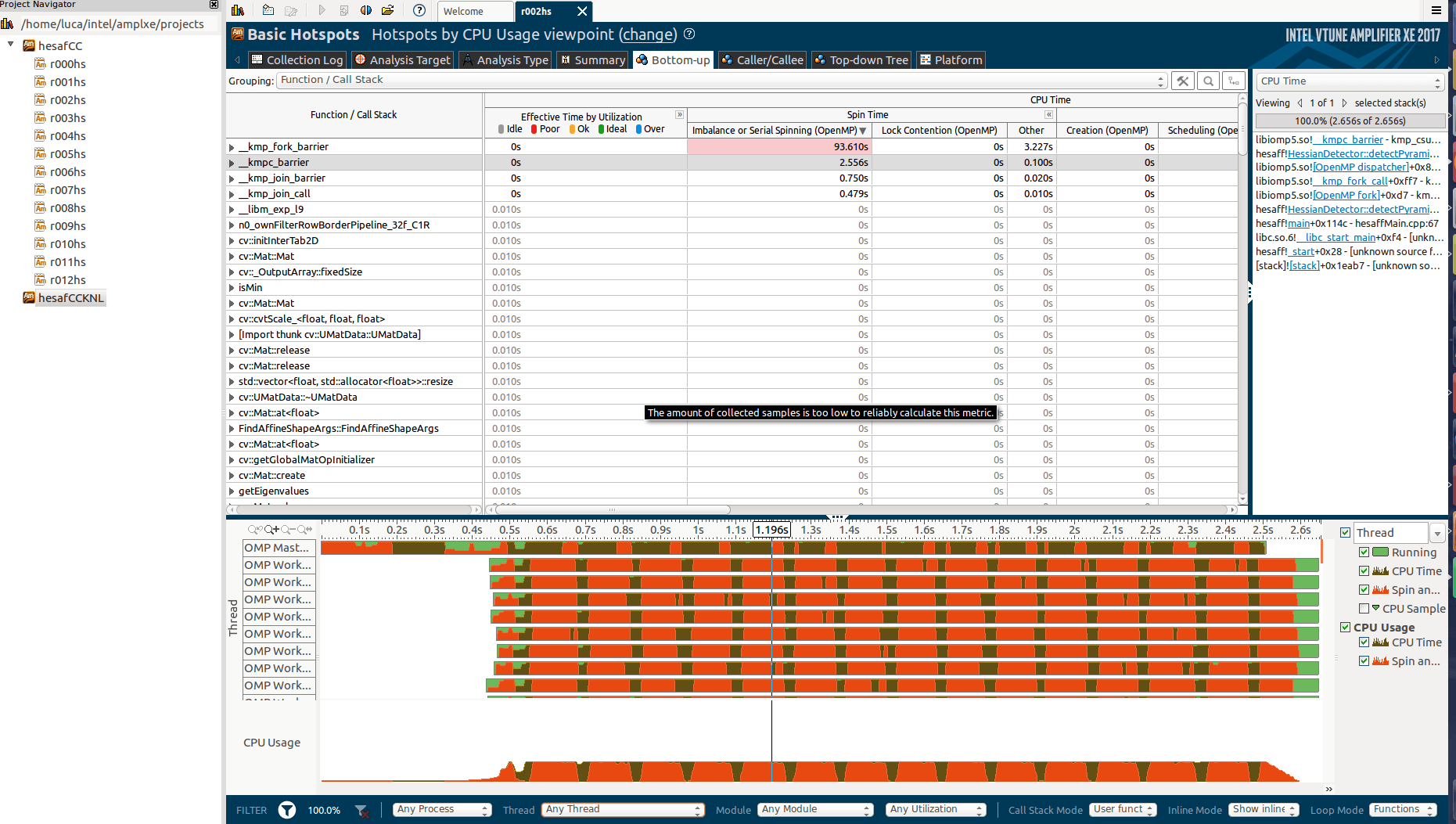
Возможно ли, что это из-за reduction? Я знал, что это было довольно эффективно (используя подход слияния и разделения).
Посмотрите здесь, как самые дорогие функции хорошо распараллелены (большинство из них):
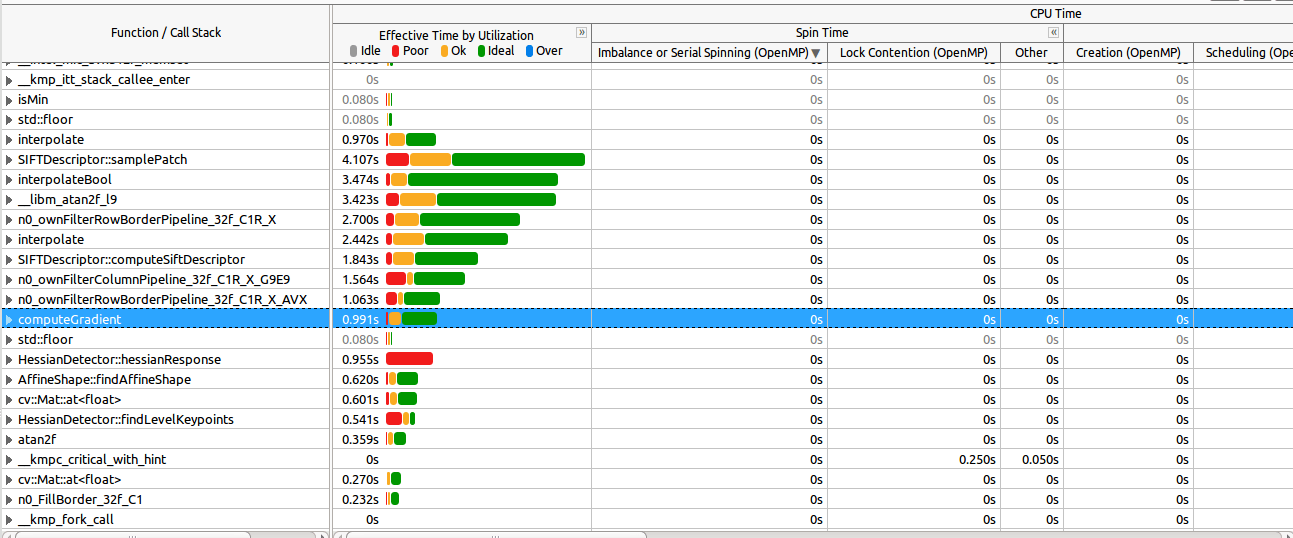
Масштабирование в спиннинг-секции (по запросу commend) 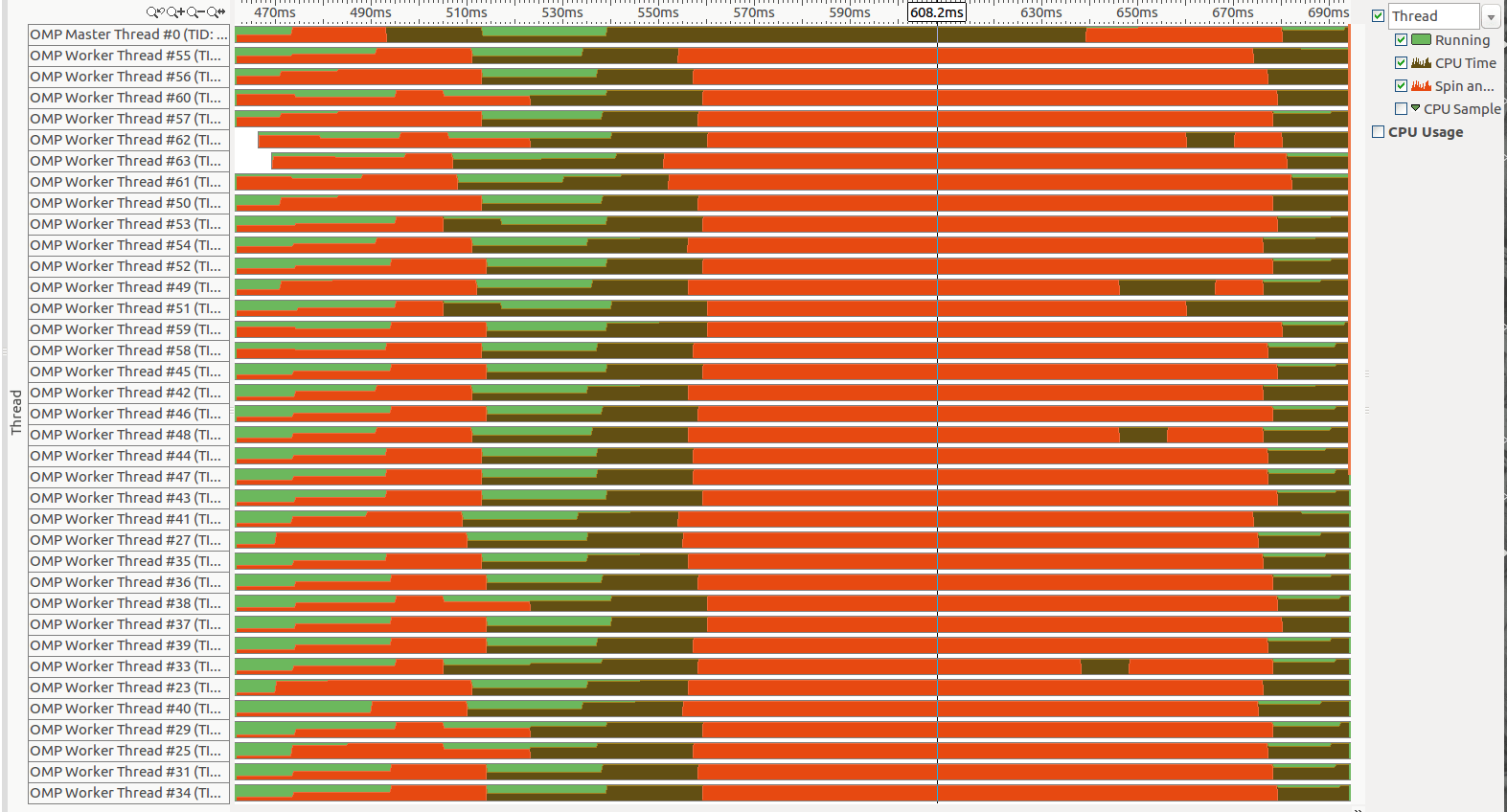 :
:
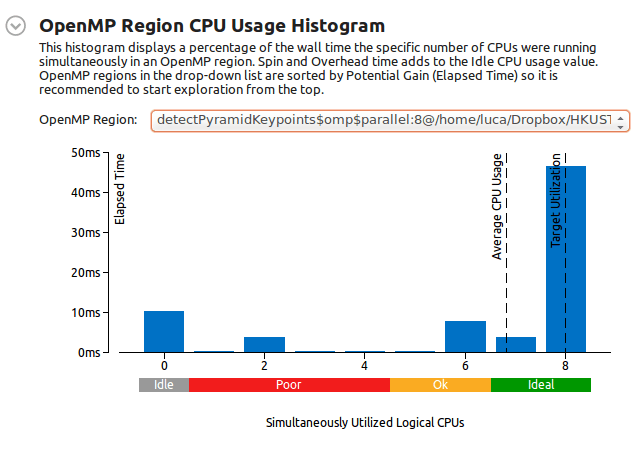
Гистограммы OpenMP в соответствии с просьбой в комментариях:
Регион редукции:
Неизвестный регион о initInterTab2d:
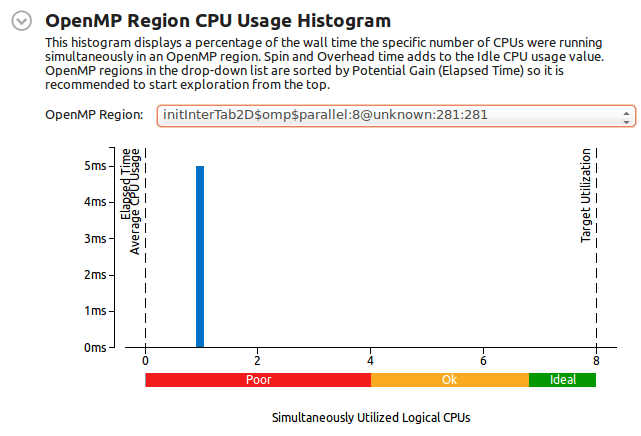
ОБНОВИТЬ:
Сборка OpenCV с отключенным TBB и OpenMP удалила этот странный параллельный регион iniInterTab2D, Так что это наверняка связано с OpenCV, но я не знаю, как.
1 ответ
Вам нужно научиться лучше использовать VTune. Он имеет специфический анализ OpenMP, который позволяет вам не спрашивать о внутренностях среды выполнения OpenMP. Просмотрите https://software.intel.com/en-us/node/544172 и https://software.intel.com/en-us/openmp-analysis-lin для ознакомления.
PS Использование schedule(dynamic,1) везде наверное плохая идея.
pps Перед тем, как строить результаты масштабирования, прочитайте мой блог о том, как это сделать.
Полное раскрытие: я работаю на Intel, иногда на OpenMP.