Отчет perf показывает, что эта функция "__memset_avx2_unaligned_erms" имеет дополнительные издержки. это значит, что память не выровнена?
Я пытаюсь профилировать мой код C++ с помощью инструмента Perf. Реализация содержит код с инструкциями SSE/AVX/AVX2. В дополнение к этому код скомпилирован с -O3 -mavx2 -march=native флаги. я верю __memset_avx2_unaligned_erms функция является реализацией libc memset, perf показывает, что эта функция имеет значительные накладные расходы. Имя функции указывает, что память не выровнена, однако в коде я явно выравниваю память, используя встроенный макрос GCC __attribute__((aligned (x))) Что может быть причиной того, что эта функция имеет значительные накладные расходы, а также почему вызывается невыровненная версия, хотя память выровнена явно?
Я приложил образец отчета как изображение. 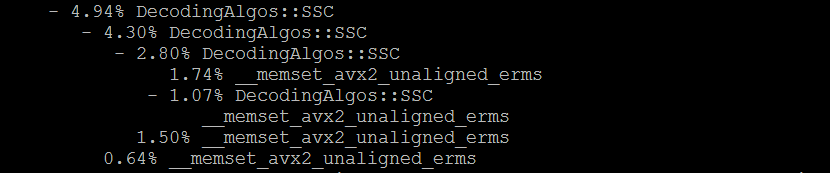
1 ответ
Нет, это не так. Это означает, что стратегия memset, выбранная glibc на этом оборудовании, - это стратегия, которая не пытается полностью избежать совмещенного доступа, в случаях небольшого размера. (glibc выбирает реализацию memset во время динамического разрешения символов компоновщика, поэтому он получает диспетчеризацию во время выполнения без дополнительных затрат после первого вызова.)
Если ваш буфер на самом деле выровнен, а размер кратен ширине вектора, все обращения будут выровнены, и никаких накладных расходов практически не будет. (С помощью vmovdqu с указателем, который оказывается выровненным во время выполнения, точно эквивалентно vmovdqa на всех процессорах, которые поддерживают AVX.)
Для больших буферов он все еще выравнивает указатель перед основным циклом, если он не выровнен, за счет пары дополнительных инструкций по сравнению с реализацией, которая работала только для 32-байтовых выровненных указателей. (Но похоже, что он использует rep stosb без выравнивания указателя, если он собирается rep stosb совсем.)
gcc + glibc не имеет специальной версии memset, которая вызывается только с выровненными указателями. (Или несколько специальных версий для разных гарантий выравнивания). Реализация GLIBC без выравнивания AVX2 прекрасно работает как для выровненных, так и для невыровненных входов.
Это определено в glibc/sysdeps/x86_64/multiarch/memset-avx2-unaligned-erms.S, который определяет пару макросов (например, определение размера вектора как 32), а затем #include "memset-vec-unaligned-erms.S",
Комментарий в исходном коде говорит:
/* memset is implemented as:
1. Use overlapping store to avoid branch.
2. If size is less than VEC, use integer register stores.
3. If size is from VEC_SIZE to 2 * VEC_SIZE, use 2 VEC stores.
4. If size is from 2 * VEC_SIZE to 4 * VEC_SIZE, use 4 VEC stores.
5. If size is more to 4 * VEC_SIZE, align to 4 * VEC_SIZE with
4 VEC stores and store 4 * VEC at a time until done. */
Фактическое выравнивание до основного цикла выполняется после некоторого vmovdqu хранилища векторов (без штрафа, если они используются для данных, которые фактически выровнены: https://agner.org/optimize/):
L(loop_start):
leaq (VEC_SIZE * 4)(%rdi), %rcx # rcx = input pointer + 4*VEC_SIZE
VMOVU %VEC(0), (%rdi) # store the first vector
andq $-(VEC_SIZE * 4), %rcx # align the pointer
... some more vector stores
... and stuff, including storing the last few vectors I think
addq %rdi, %rdx # size += start, giving an end-pointer
andq $-(VEC_SIZE * 4), %rdx # align the end-pointer
L(loop): # THE MAIN LOOP
VMOVA %VEC(0), (%rcx) # vmovdqa = alignment required
VMOVA %VEC(0), VEC_SIZE(%rcx)
VMOVA %VEC(0), (VEC_SIZE * 2)(%rcx)
VMOVA %VEC(0), (VEC_SIZE * 3)(%rcx)
addq $(VEC_SIZE * 4), %rcx
cmpq %rcx, %rdx
jne L(loop)
Таким образом, при VEC_SIZE = 32 он выравнивает указатель на 128. Это излишне; Строки кэша занимают 64 байта, и на самом деле просто выравнивание по ширине вектора должно подойти
Он также имеет порог для использования rep stos если включено и размер буфера> 2 кБ, на процессорах с ERMSB. ( Улучшен REP MOVSB для memcpy).