Добавление множества линий для построения графика с помощью функции htmlWidgets onRender()
Я пытаюсь взять пустой график, передать его в onRender() из htmlWidgets и добавить много строк внутри функции onRender(). В приведенном ниже коде я использую набор данных со 100 строками (100 строками), и когда я запускаю приложение, 100 линий рисуются внутри onRender() примерно за одну секунду. Однако, когда я изменяю набор данных, скажем, на 2000 линий, потребуется всего десять секунд, чтобы нарисовать их все.
Я пытаюсь достичь этого для наборов данных порядка от 50 000 до 100 000 строк. Это очевидно проблематично из-за медлительности кода в настоящее время!
Способ, которым я в настоящее время достигаю функциональности:
- Создание фрейма данных в R называется pcpDat. Он имеет 100 строк и 6 столбцов числовых данных.
- Создание пустого графика в R с именем p
- Подача фрейма данных pcpDat и отображение p в onRender()
- В onRender(): у меня есть объект xArr, который просто содержит значения 0,1,2,3,4,5. Для каждой строки фрейма данных я восстанавливаю его 6 значений в числовой вектор с именем yArr. Затем для каждой строки данных я создаю объект трассировки Plotly, который содержит xArr и yArr для построения графиков для значений 6 x и 6 y. Этот объект трассировки Plotly создает одну оранжевую линию для каждой строки исходного фрейма данных.
Может показаться глупым иметь столько линий! Я рассуждаю так: я пытаюсь в конечном итоге добавить функциональность, чтобы пользователь мог использовать Plotly, чтобы выбрать область на графике и просмотреть только линии, которые пересекают эту область (остальные линии будут удалены). Вот почему я хочу, чтобы линии были "интерактивными".
Все это заставило меня задуматься над несколькими вопросами:
- У меня нет опыта работы с JavaScript (суть функции onRender()). Я задаюсь вопросом, возможно ли вообще ожидать, что от 50 000 до 100 000 линий будут построены быстро (в течение, скажем, 5 секунд)?
- Если ответ на вопрос (1) состоит в том, что это возможно, я ищу совет о том, как я могу "ускорить" мой фрагмент кода ниже. Без особых навыков JavaScript мне трудно определить, что стоит больше всего времени. Я мог бы реконструировать эти данные неэффективно.
Я очень хочу услышать любой совет или мнение по этой теме. Спасибо!
library(plotly)
library(ggplot2)
library(shiny)
library(htmlwidgets)
library(utils)
ui <- basicPage(
plotlyOutput("plot1")
)
server <- function(input, output) {
set.seed(3)
f = function(){1.3*rnorm(100)}
pcpDat = data.frame(ID = paste0("ID", 1:100), A=f(), B=f(), C=f(), D=f(), E=f(), F=f())
pcpDat$ID = as.character(pcpDat$ID)
plotPCP(pcpDat = pcpDat)
colNms <- colnames(pcpDat[, c(2:(ncol(pcpDat)))])
nVar <- length(colNms)
p <- ggplot(mtcars, aes(x = wt, y = mpg)) + geom_point(alpha=0) + xlim(0,(nVar-1)) +ylim(min(pcpDat[,2:(nVar+1)]),max(pcpDat[,2:(nVar+1)])) + xlab("Sample") + ylab("Count")
gp <- ggplotly(p)
output$plot1 <- renderPlotly({
gp %>% onRender("
function(el, x, data) {
var origPcpDat = data.pcpDat
var pcpDat = data.pcpDat
var Traces = [];
var dLength = pcpDat.length
var vLength = data.nVar
var cNames = data.colNms
xArr = [];
for (b=0; b<vLength; b++){
xArr.push(b)
}
for (a=0; a<dLength; a++){
yArr = [];
for (b=0; b<vLength; b++){
yArr.push(pcpDat[a][cNames[b]]);
}
var pcpLine = {
x: xArr,
y: yArr,
mode: 'lines',
line: {
color: 'orange',
width: 1
},
opacity: 0.9,
}
Traces.push(pcpLine);
}
Plotly.addTraces(el.id, Traces);
}", data = list(pcpDat = pcpDat, nVar = nVar, colNms = colNms))})
}
shinyApp(ui, server)
РЕДАКТИРОВАТЬ: Чтобы продемонстрировать, что я пытаюсь сделать, я включаю 3 изображения. Они показывают пример, где в данных 10 строк (строк). Первое изображение - это то, что пользователь увидит вначале (присутствуют все 10 строк). Затем пользователь может использовать инструмент "Выбор ящика" и создать прямоугольник (серый). Любые строки, которые остаются внутри прямоугольника для всех значений x, которые он содержит, остаются. На втором изображении для этого примера осталось 5 строк. После этого пользователь может, скажем, создать еще один прямоугольник (серый). Опять же, все строки, которые остаются внутри прямоугольника для всех значений x, которые он содержит, остаются. На третьем изображении для этого примера осталась только 1 строка. Эти 3 скриншота из моего действующего кода. Итак, у меня есть опытный образец. Однако, когда я добавляю тысячи строк, это слишком медленно.
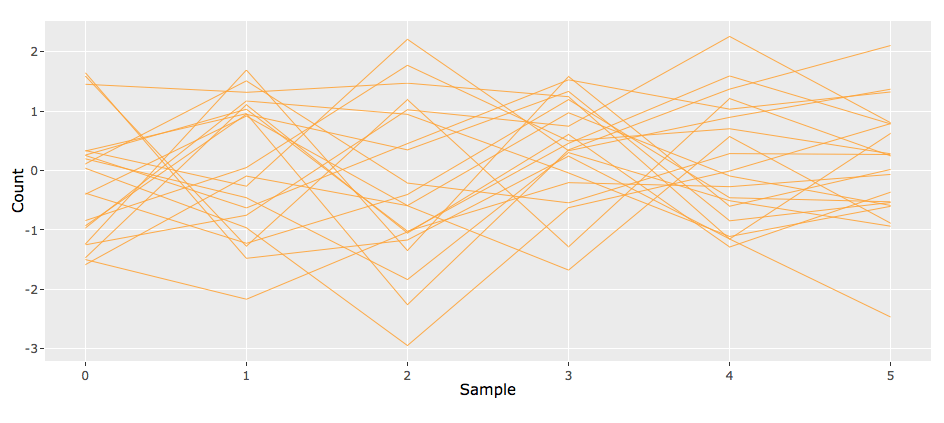

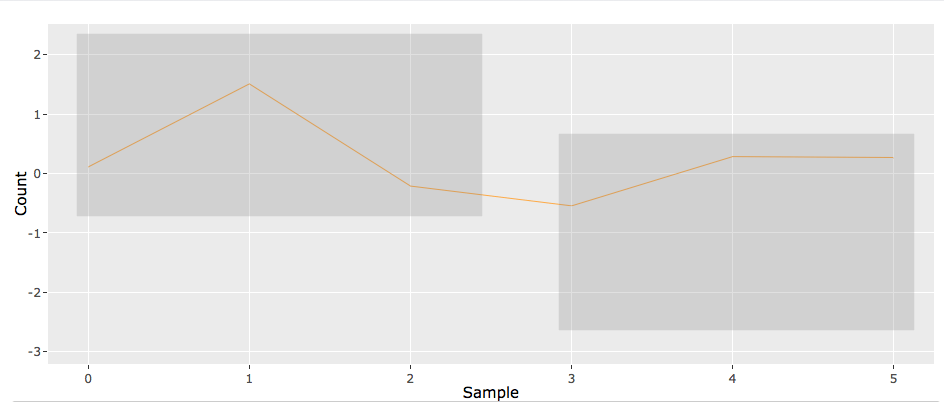
1 ответ
Если вы переведете свой ggplot и сюжетно javascript к plotly Пакет стандартный, тогда вы удалите лишние шаги и вычисления, которые у вас есть в настоящее время. Минимальный пример решения ниже:
output$plot1 <- renderPlotly({
plot_ly(type = "scatter", mode = "markers") %>%
add_trace(
x = ~wt,
y = ~mpg,
data = mtcars
) %>%
layout(
xaxis = list(title = "Sample"),
yaxis = list(title = "Count")
)
})

Чтобы выполнить скрытые следы, вы можете установить visible = "legendonly" Благодаря вашим следам, и пользователь может включить или выключить их. Смотрите эти ответы для более подробной информации, 1 и 2
Вы также можете использовать входные данные и реактивные элементы, чтобы ограничить объем данных, которые вы отправляете на график, вместо того, чтобы предоставлять их каждый раз, когда вы хотите сгенерировать.