Сценарий рассеяния Python и Matplotlib
У меня есть точечный график в Python, на котором я хочу нарисовать линию тренда. Из различных примеров, которые я нашел в Интернете, чтобы научиться рисовать линию тренда, мой код выглядит следующим образом:
import matplotlib.pyplot as plt
import numpy as np
x=np.array([9.80,13.20,13.46,14.09,13.96,10.77,8.79,8.61,8.83,11.08,10.13,12.40,9.90,10.96,12.75,11.79,11.79,12.38,12.78,13.08,12.83,12.57,12.96,12.90,12.91,13.67,12.83,12.50,12.42,12.83,12.82,12.70,12.60,12.90,13.20])
y=np.array([0.0706,0.0969,0.0997,0.1031,0.0848,0.1044,0.0815,0.1030,0.0783,0.0970,0.1193,0.0796,0.0697,0.0738,0.0895,0.0912,0.0887,0.0973,0.0942,0.1052,0.0984,0.0965,0.0903,0.0876,0.1071,0.0872,0.0857,0.0967,0.0926,0.0837,0.0967,0.0935,0.0946,0.0930,0.0758
])
plt.scatter(x, y)
fit = np.polyfit(x, y, deg=4)
p = np.poly1d(fit)
plt.plot(x,p(x),"r--")
plt.show()
Но строка результата, а не кривая, представляет собой просто смесь линий. Кто-нибудь может объяснить мою ошибку?
3 ответа
Я думаю это потому что x значения не отсортированы. Посмотрите на этот код:
import matplotlib.pyplot as plt
import numpy as np
x=np.array([9.80,13.20,13.46,14.09,13.96,10.77,8.79,8.61,8.83,11.08,10.13,12.40,9.90,10.96,12.75,11.79,11.79,12.38,12.78,
13.08,12.83,12.57,12.96,12.90,12.91,13.67,12.83,12.50,12.42,12.83,12.82,12.70,12.60,12.90,13.20])
y=np.array([0.0706,0.0969,0.0997,0.1031,0.0848,0.1044,0.0815,0.1030,0.0783,0.0970,0.1193,0.0796,0.0697,0.0738,
0.0895,0.0912,0.0887,0.0973,0.0942,0.1052,0.0984,0.0965,0.0903,0.0876,0.1071,0.0872,0.0857,0.0967,0.0926,0.0837,0.0967,0.0935,0.0946,0.0930,0.0758 ])
# Here I sort x values and their corresponding y values
args = np.argsort(x)
x = x[args]
y = y[args]
plt.scatter(x, y)
fit = np.polyfit(x, y, deg=4)
p = np.poly1d(fit)
plt.plot(x,p(x),"r--")
plt.show()
Результат:

Это будет делать:
plt.scatter(x,y)
x = sorted(x)
plt.plot(x,p(x),"r--")
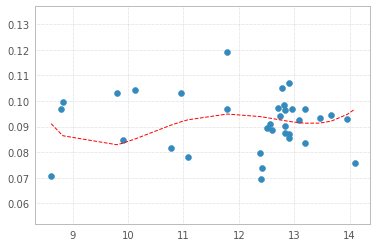
Хитрость заключается в сортировке x значения перед нанесением линии над ними.
df["Medal"].fillna("None",inplace=True) df["Medal_Int"] = df["Medal"] df["Medal_Int"].replace(["Gold","Silver","Bronze ","Нет"],[1,2,3,4],inplace=True)df_medals = df.groupby(["Год","Медаль"]).count().reset_index()
df_entries = df.groupby(["Год"]).count().reset_index()moving_avg = df_entries.rolling(window=5).mean()
cum_sum[:5]
sns.scatterplot(x="Год",y="ID",size="Медаль",hue="Медаль",data=df_medals[df_medals["Медаль"] !="Нет"]) sns.lineplot(x ="Год",г="ID",данные=cum_sum)