Почему эта реализация TensorFlow значительно менее успешна, чем NN Matlab?
В качестве примера игрушки я пытаюсь соответствовать функции f(x) = 1/x из 100 точек без шума данных. Реализация matlab по умолчанию является феноменально успешной со среднеквадратичной разностью ~10^-10 и отлично интерполируется.
Я реализую нейронную сеть с одним скрытым слоем из 10 сигмовидных нейронов. Я новичок в нейронных сетях, так что будьте осторожны с тупым кодом.
import tensorflow as tf
import numpy as np
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
#Can't make tensorflow consume ordinary lists unless they're parsed to ndarray
def toNd(lst):
lgt = len(lst)
x = np.zeros((1, lgt), dtype='float32')
for i in range(0, lgt):
x[0,i] = lst[i]
return x
xBasic = np.linspace(0.2, 0.8, 101)
xTrain = toNd(xBasic)
yTrain = toNd(map(lambda x: 1/x, xBasic))
x = tf.placeholder("float", [1,None])
hiddenDim = 10
b = bias_variable([hiddenDim,1])
W = weight_variable([hiddenDim, 1])
b2 = bias_variable([1])
W2 = weight_variable([1, hiddenDim])
hidden = tf.nn.sigmoid(tf.matmul(W, x) + b)
y = tf.matmul(W2, hidden) + b2
# Minimize the squared errors.
loss = tf.reduce_mean(tf.square(y - yTrain))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# For initializing the variables.
init = tf.initialize_all_variables()
# Launch the graph
sess = tf.Session()
sess.run(init)
for step in xrange(0, 4001):
train.run({x: xTrain}, sess)
if step % 500 == 0:
print loss.eval({x: xTrain}, sess)
Среднеквадратичная разница заканчивается на ~2*10^-3, поэтому примерно на 7 порядков хуже, чем у matlab. Визуализация с
xTest = np.linspace(0.2, 0.8, 1001)
yTest = y.eval({x:toNd(xTest)}, sess)
import matplotlib.pyplot as plt
plt.plot(xTest,yTest.transpose().tolist())
plt.plot(xTest,map(lambda x: 1/x, xTest))
plt.show()
мы видим, что подгонка систематически несовершенна: 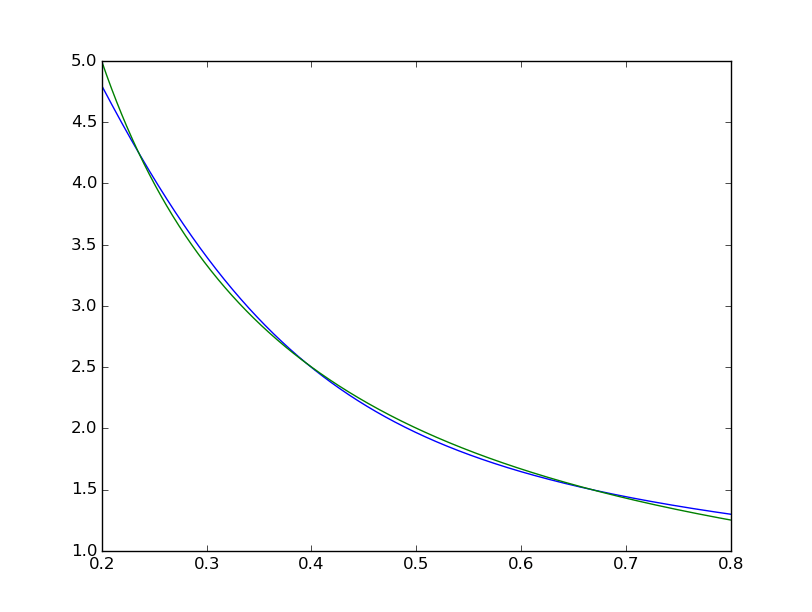 в то время как Matlab выглядит идеально невооруженным глазом с разницей равномерно< 10^-5:
в то время как Matlab выглядит идеально невооруженным глазом с разницей равномерно< 10^-5: 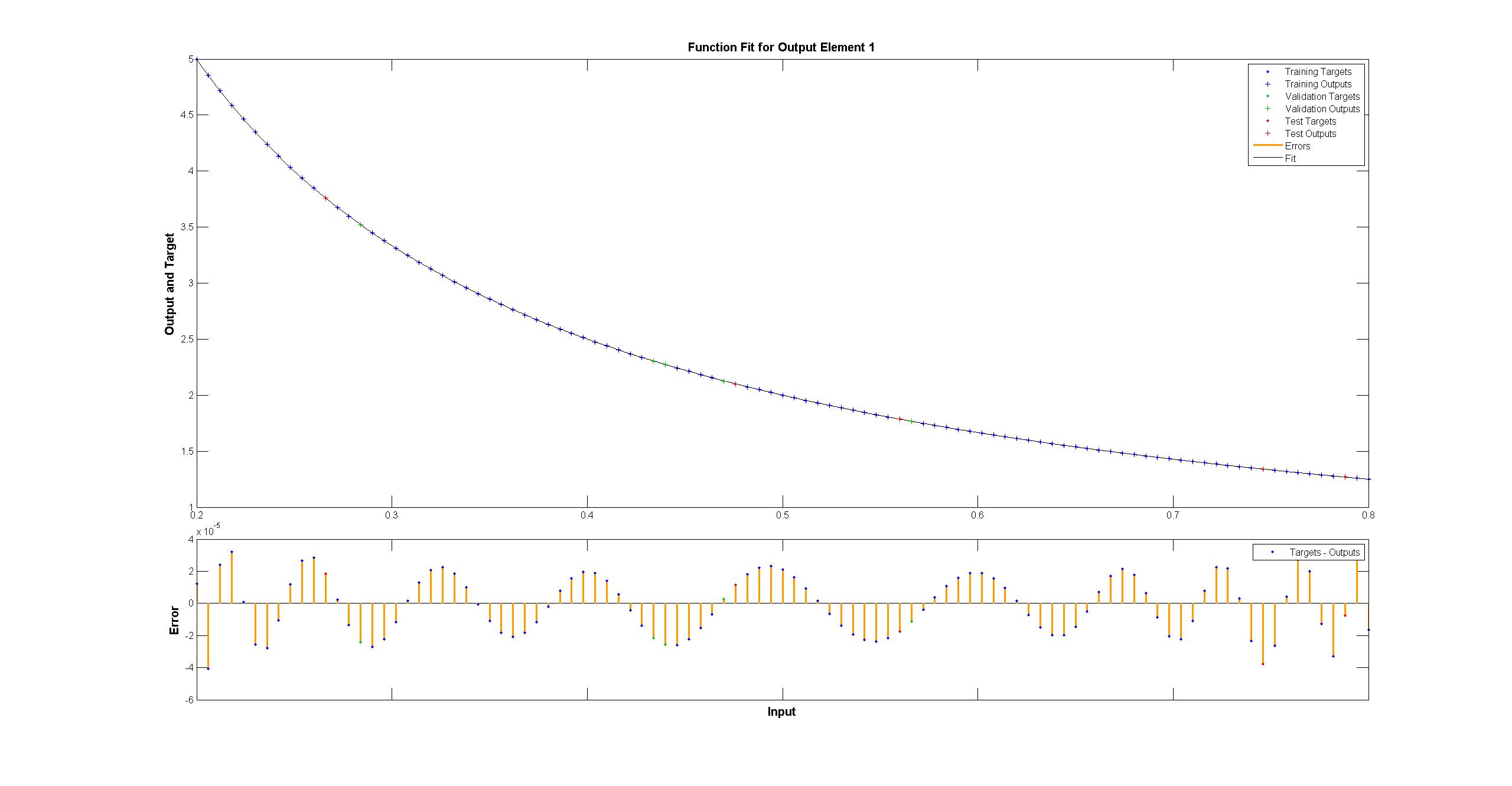 Я попытался повторить с TensorFlow диаграмму сети Matlab:
Я попытался повторить с TensorFlow диаграмму сети Matlab:
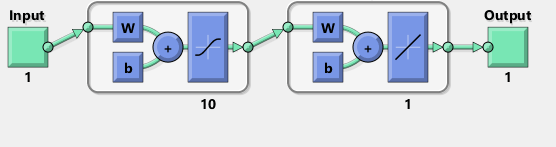
Между прочим, диаграмма, по-видимому, подразумевает скорее танх, чем сигмовидную активацию. Я не могу найти это нигде в документации, чтобы быть уверенным. Однако, когда я пытаюсь использовать tanh нейрон в TensorFlow, фитинг быстро терпит неудачу с nan для переменных. Я не знаю почему.
Матлаб использует алгоритм обучения Левенберга – Марквардта. Байесовская регуляризация еще более успешна со средними квадратами в 10^-12 (мы, вероятно, находимся в области паров арифметики с плавающей точкой).
Почему реализация TensorFlow намного хуже, и что я могу сделать, чтобы сделать ее лучше?
2 ответа
Я пробовал тренироваться на 50000 итераций, он получил ошибку 0,00012. Это займет около 180 секунд на Tesla K40.

Кажется, что для такого рода проблем градиентный спуск первого порядка не подходит (каламбур предназначен), и вам нужен Левенберг-Марквардт или l-BFGS. Я не думаю, что кто-то реализовал их в TensorFlow.
Изменить Использование tf.train.AdamOptimizer(0.1) для этой проблемы. Доходит до 3.13729e-05 после 4000 итераций. Кроме того, графический процессор со стратегией по умолчанию также кажется плохой идеей для этой проблемы. Есть много мелких операций, и из-за накладных расходов на моем компьютере версия GPU работает в 3 раза медленнее, чем процессор.
Кстати, вот слегка исправленная версия выше, которая убирает некоторые проблемы с формой и ненужные скачки между tf и np. Достигается 3e-08 после 40 тыс. Шагов или около 1,5e-5 после 4000:
import tensorflow as tf
import numpy as np
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
xTrain = np.linspace(0.2, 0.8, 101).reshape([1, -1])
yTrain = (1/xTrain)
x = tf.placeholder(tf.float32, [1,None])
hiddenDim = 10
b = bias_variable([hiddenDim,1])
W = weight_variable([hiddenDim, 1])
b2 = bias_variable([1])
W2 = weight_variable([1, hiddenDim])
hidden = tf.nn.sigmoid(tf.matmul(W, x) + b)
y = tf.matmul(W2, hidden) + b2
# Minimize the squared errors.
loss = tf.reduce_mean(tf.square(y - yTrain))
step = tf.Variable(0, trainable=False)
rate = tf.train.exponential_decay(0.15, step, 1, 0.9999)
optimizer = tf.train.AdamOptimizer(rate)
train = optimizer.minimize(loss, global_step=step)
init = tf.initialize_all_variables()
# Launch the graph
sess = tf.Session()
sess.run(init)
for step in xrange(0, 40001):
train.run({x: xTrain}, sess)
if step % 500 == 0:
print loss.eval({x: xTrain}, sess)
Все это говорит о том, что, вероятно, не слишком удивительно, что LMA работает лучше, чем более общий оптимизатор в стиле DNN для подгонки 2D-кривой. Адам и все остальные нацелены на проблемы с очень высокой размерностью, и LMA начинает очень медленно работать для очень больших сетей (см. 12-15).