Команда top для графических процессоров, использующих CUDA
Я пытаюсь контролировать процесс, который использует cuda и MPI, есть ли способ, которым я мог бы сделать это, что-то вроде команды "top", но который также контролирует GPU?
17 ответов
Я нахожу gpustat очень полезным. Может быть установлен с pip install gpustatи распечатывает данные об использовании процессов или пользователей.

Чтобы получить представление об используемых ресурсах в режиме реального времени, выполните:
nvidia-smi -l 1
Это зациклится и вызовет представление в каждую секунду.
Если вы не хотите сохранять прошлые следы зацикленного вызова в истории консоли, вы также можете сделать:
watch -n0.1 nvidia-smi
Где 0.1 - временной интервал в секундах.

Я не знаю ничего, что объединяет эту информацию, но вы можете использовать nvidia-smi инструмент для получения необработанных данных, вот так (спасибо @jmsu за подсказку по -l):
$ nvidia-smi -q -g 0 -d UTILIZATION -l
==============NVSMI LOG==============
Timestamp : Tue Nov 22 11:50:05 2011
Driver Version : 275.19
Attached GPUs : 2
GPU 0:1:0
Utilization
Gpu : 0 %
Memory : 0 %
Недавно я написал инструмент мониторинга под названием , интерактивный просмотрщик процессов NVIDIA-GPU. Он написан на чистом Python и прост в установке.
Установить из PyPI:
pip3 install --upgrade nvitop
Установите последнюю версию с GitHub (рекомендуется ):
pip3 install git+https://github.com/XuehaiPan/nvitop.git#egg=nvitop
Запустить как монитор ресурсов:
nvitop -m
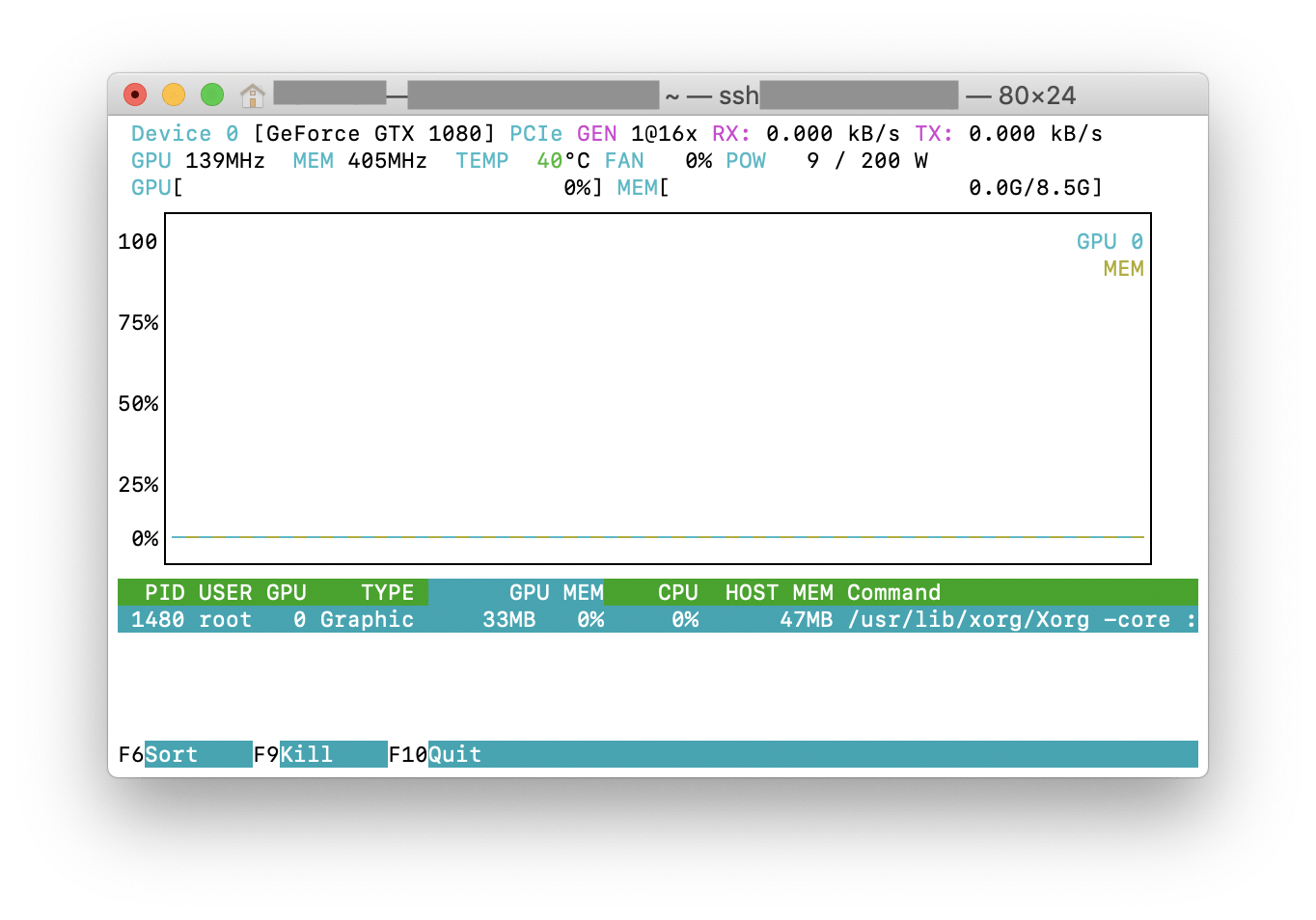
nvitop покажет состояние графического процессора, но с дополнительными причудливыми полосами и графиками истории.
Для процессов он будет использовать
psutil для сбора информации о процессе и отображения
USER,
%CPU,
%MEM,
TIME а также
COMMAND поля, которые гораздо более подробны, чем
nvidia-smi. Кроме того, он реагирует на ввод данных пользователем в режиме монитора. Вы можете прервать или убить свои процессы на графических процессорах.
См. Https://github.com/XuehaiPan/nvitop для получения дополнительных сведений.
Просто используйте watch nvidia-smi, он будет выводить сообщение с интервалом 2 с по умолчанию.
Например, как изображение ниже:

Вы также можете использовать watch -n 5 nvidia-smi (-n 5 на 5 с интервалом).
Ты можешь попробовать nvtop, который похож на широко используемый htop инструмент, но для графических процессоров NVIDIA. Вот скриншот nvtop об этом в действии.
Используйте аргумент "--query-compute-apps="
nvidia-smi --query-compute-apps=pid,process_name,used_memory --format=csv
для получения дополнительной помощи, пожалуйста, следуйте
nvidia-smi --help-query-compute-app
Загрузите и установите последнюю стабильную версию драйвера CUDA (4.2) отсюда. В Linux nVidia-smi 295.41 дает вам именно то, что вы хотите. использование nvidia-smi:
[root@localhost release]# nvidia-smi
Wed Sep 26 23:16:16 2012
+------------------------------------------------------+
| NVIDIA-SMI 3.295.41 Driver Version: 295.41 |
|-------------------------------+----------------------+----------------------+
| Nb. Name | Bus Id Disp. | Volatile ECC SB / DB |
| Fan Temp Power Usage /Cap | Memory Usage | GPU Util. Compute M. |
|===============================+======================+======================|
| 0. Tesla C2050 | 0000:05:00.0 On | 0 0 |
| 30% 62 C P0 N/A / N/A | 3% 70MB / 2687MB | 44% Default |
|-------------------------------+----------------------+----------------------|
| Compute processes: GPU Memory |
| GPU PID Process name Usage |
|=============================================================================|
| 0. 7336 ./align 61MB |
+-----------------------------------------------------------------------------+
РЕДАКТИРОВАТЬ: В последних драйверах NVIDIA эта поддержка ограничена картами Tesla.
Еще один полезный подход к мониторингу заключается в использовании ps фильтруется по процессам, которые потребляют ваши графические процессоры. Я часто этим пользуюсь:
ps f -o user,pgrp,pid,pcpu,pmem,start,time,command -p `lsof -n -w -t /dev/nvidia*`
Это покажет все процессы, использующие графические процессоры NVIDIA, и некоторые статистические данные о них. lsof ... извлекает список всех процессов, используя графический процессор nvidia, принадлежащий текущему пользователю, и ps -p ... шоу ps результаты для этих процессов. ps f показывает хорошее форматирование для отношений / иерархий дочерних / родительских процессов, и -o определяет пользовательское форматирование. Это похоже на просто делать ps u но добавляет идентификатор группы процессов и удаляет некоторые другие поля.
Одно преимущество этого по сравнению nvidia-smi в том, что он будет показывать ветки процессов, а также основные процессы, использующие графический процессор.
Один недостаток, однако, заключается в том, что он ограничен процессами, принадлежащими пользователю, который выполняет команду. Чтобы открыть его для всех процессов, принадлежащих любому пользователю, я добавляю sudo перед lsof,
Наконец, я объединяю это с watch чтобы получить постоянное обновление. Итак, в итоге это выглядит так:
watch -n 0.1 'ps f -o user,pgrp,pid,pcpu,pmem,start,time,command -p `sudo lsof -n -w -t /dev/nvidia*`'
Который имеет вывод, как:
Every 0.1s: ps f -o user,pgrp,pid,pcpu,pmem,start,time,command -p `sudo lsof -n -w -t /dev/nvi... Mon Jun 6 14:03:20 2016
USER PGRP PID %CPU %MEM STARTED TIME COMMAND
grisait+ 27294 50934 0.0 0.1 Jun 02 00:01:40 /opt/google/chrome/chrome --type=gpu-process --channel=50877.0.2015482623
grisait+ 27294 50941 0.0 0.0 Jun 02 00:00:00 \_ /opt/google/chrome/chrome --type=gpu-broker
grisait+ 53596 53596 36.6 1.1 13:47:06 00:05:57 python -u process_examples.py
grisait+ 53596 33428 6.9 0.5 14:02:09 00:00:04 \_ python -u process_examples.py
grisait+ 53596 33773 7.5 0.5 14:02:19 00:00:04 \_ python -u process_examples.py
grisait+ 53596 34174 5.0 0.5 14:02:30 00:00:02 \_ python -u process_examples.py
grisait+ 28205 28205 905 1.5 13:30:39 04:56:09 python -u train.py
grisait+ 28205 28387 5.8 0.4 13:30:49 00:01:53 \_ python -u train.py
grisait+ 28205 28388 5.3 0.4 13:30:49 00:01:45 \_ python -u train.py
grisait+ 28205 28389 4.5 0.4 13:30:49 00:01:29 \_ python -u train.py
grisait+ 28205 28390 4.5 0.4 13:30:49 00:01:28 \_ python -u train.py
grisait+ 28205 28391 4.8 0.4 13:30:49 00:01:34 \_ python -u train.py
Это может быть не элегантно, но вы можете попробовать
while true; do sleep 2; nvidia-smi; done
Я также попробовал метод @Edric, который работает, но я предпочитаю оригинальный макет nvidia-smi,
Вы можете использовать программу мониторинга взглядов с помощью плагина для мониторинга GPU:
- Открытый исходный код
- установить:
sudo apt-get install -y python-pip; sudo pip install glances[gpu] - запускать:
sudo glances
Он также контролирует процессор, дисковый ввод-вывод, дисковое пространство, сеть и некоторые другие вещи:
В Linux Mint и, скорее всего, в Ubuntu вы можете попробовать "nvidia-smi --loop=1"
Если вы просто хотите найти процесс, запущенный на графическом процессоре, вы можете просто использовать следующую команду:
lsof /dev/nvidia*
Для меня nvidia-smi а также watch -n 1 nvidia-smiв большинстве случаев достаточно. Иногдаnvidia-smi не показывает никакого процесса, но память графического процессора израсходована, поэтому мне нужно использовать указанную выше команду, чтобы найти процессы.
Я создал командный файл со следующим кодом на машине с Windows для мониторинга каждую секунду. Меня устраивает.
:loop
cls
"C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi"
timeout /T 1
goto loop
nvidia-smi exe обычно находится в папке "C:\Program Files\NVIDIA Corporation", если вы хотите запустить команду только один раз.
Ты можешь использовать nvidia-smi pmon -i 0 контролировать каждый процесс в графическом процессоре 0. включая режим вычислений, использование sm, использование памяти, использование кодера, использование декодера.
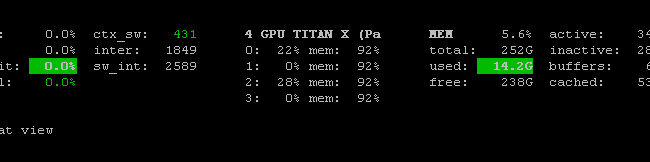
Существует Prometheus GPU Metrics Exporter (PGME), который использует двоичный файл nvidai-smi. Вы можете попробовать это. Когда экспортер запущен, вы можете получить к нему доступ через http://localhost:9101/metrics. Результат для двух графических процессоров выглядит следующим образом:
temperature_gpu{gpu="TITAN X (Pascal)[0]"} 41
utilization_gpu{gpu="TITAN X (Pascal)[0]"} 0
utilization_memory{gpu="TITAN X (Pascal)[0]"} 0
memory_total{gpu="TITAN X (Pascal)[0]"} 12189
memory_free{gpu="TITAN X (Pascal)[0]"} 12189
memory_used{gpu="TITAN X (Pascal)[0]"} 0
temperature_gpu{gpu="TITAN X (Pascal)[1]"} 78
utilization_gpu{gpu="TITAN X (Pascal)[1]"} 95
utilization_memory{gpu="TITAN X (Pascal)[1]"} 59
memory_total{gpu="TITAN X (Pascal)[1]"} 12189
memory_free{gpu="TITAN X (Pascal)[1]"} 1738
memory_used{gpu="TITAN X (Pascal)[1]"} 10451
Бегатьnvidia-smiв режиме мониторинга устройств , например:
$ nvidia-smi dmon -d 3 -s pcvumt
# gpu pwr gtemp mtemp mclk pclk pviol tviol sm mem enc dec fb bar1 rxpci txpci
# Idx W C C MHz MHz % bool % % % % MB MB MB/s MB/s
0 273 54 - 9501 2025 0 0 100 11 0 0 18943 75 5906 659
0 280 54 - 9501 2025 0 0 100 11 0 0 18943 75 7404 650
0 277 54 - 9501 2025 0 0 100 11 0 0 18943 75 7386 719
0 279 55 - 9501 2025 0 0 99 11 0 0 18945 75 6592 692
0 281 55 - 9501 2025 0 0 99 11 0 0 18945 75 7760 641
0 279 55 - 9501 2025 0 0 99 11 0 0 18945 75 7775 668
0 279 55 - 9501 2025 0 0 100 11 0 0 18947 75 7589 690
0 281 55 - 9501 2025 0 0 99 12 0 0 18947 75 7514 657
0 279 55 - 9501 2025 0 0 100 11 0 0 18947 75 6472 558
0 280 54 - 9501 2025 0 0 100 11 0 0 18947 75 7066 683
Полная информация находится вman nvidia-smi.