Показать значение на каждом цвете столбчатой диаграммы с накоплением из другого столбца фрейма данных
Это мой фрейм данных:
6month final-formula Question Text numPatients6month
286231 1 0.031730 CI_FINANCE 977
286270 1 0.147390 CI_MJO 977
286276 1 0.106448 CI_CONCENTRATING 977
286700 2 0.010323 CI_MJO 775
286323 2 0.018065 CI_FINANCE 775
286401 2 0.034839 CI_CONCENTRATING 775
286228 3 0.032020 CI_CONCENTRATING 812
286238 3 0.061576 CI_MJO 812
286292 3 0.008621 CI_FINANCE 812
286690 4 0.008097 CI_MJO 741
286342 4 0.005398 CI_FINANCE 741
286430 4 0.060729 CI_CONCENTRATING 741
286481 5 0.009840 CI_FINANCE 813
287441 5 0.008610 CI_MJO 813
286362 5 0.041820 CI_CONCENTRATING 813
286360 6 0.021622 CI_CONCENTRATING 740
286492 6 0.017568 CI_FINANCE 740
286494 6 0.014865 CI_MJO 740
286482 7 0.015464 CI_FINANCE 776
286483 7 0.042526 CI_MJO 776
286599 7 0.011598 CI_CONCENTRATING 776
286361 8 0.024490 CI_CONCENTRATING 735
286989 8 0.004082 CI_FINANCE 735
286402 8 0.021769 CI_MJO 735
287119 9 0.003916 CI_FINANCE 766
286408 9 0.011749 CI_MJO 766
286399 9 0.019582 CI_CONCENTRATING 766
286267 10 0.019337 CI_CONCENTRATING 724
286249 10 0.037293 CI_MJO 724
286810 10 0.008287 CI_FINANCE 724
Я построил этот фрейм данных как гистограмму с накоплением. эта столбчатая диаграмма с накоплением основана на (6month,final-formula),
Как вы видите, есть numPatients6month в кадре данных. Я хотел бы показать этот номер на каждой категории с накоплением бара. например:
это моя диаграмма: 
так что в соответствии со шкалой выше, я хочу показать 977 в первом баре синего цвета, показать 977 для CI_Finance который orange color,
Это отличается от этого вопроса, так как это не с накоплением бар, Также отличается от этого, так как я собираюсь показать другой столбец(numPatients6month) который находится в моем фрейме данных, а не в столбце y-axis, ось у final-formula, но я хотел бы показать numPatients6month на каждом цвете каждого сложенного бара.
Так же, как информация, я составил вышеприведенный график, используя этот код:
df = dffinal.drop('numPatients6month', 1).groupby(['6month','Question Text']).sum().unstack('Question Text')
df.columns = df.columns.droplevel()
ax=df.plot(kind='bar', stacked=True)
import matplotlib.pyplot as plt
plt.xticks(range(0,10), ['6month','1 year','1.5 year','2 year','2.5 year','3 year','3.5 year','4 year','4.5 year','5 year'], fontsize=8, rotation=45)
plt.title('Cognitive Impairement-Stack bar')
plt.show()
Спасибо,:)
2 ответа
Вот один из способов сделать это:
ax=df.plot(kind='bar', stacked=True)
#loop to add the text
list_values = (dffinal['numPatients6month'].tolist()[::3]
+ dffinal['numPatients6month'].tolist()[1::3]
+ dffinal['numPatients6month'].tolist()[2::3])
for rect, value in zip(ax.patches, list_values):
h = rect.get_height() /2.
w = rect.get_width() /2.
x, y = rect.get_xy()
ax.text(x+w, y+h,value,horizontalalignment='center',verticalalignment='center')
#same than your code
plt.xticks(range(0,10), ['6month','1 year','1.5 year','2 year','2.5 year','3 year','3.5 year','4 year','4.5 year','5 year'], fontsize=8, rotation=45)
plt.title('Cognitive Impairement-Stack bar')
plt.show()
list_values получить значение из столбца 'numPatients6month' в том же порядке, что и rect от ax.patches и результат:
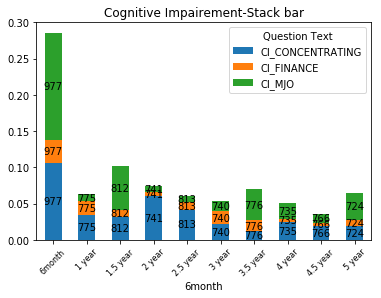
но из-за того, что некоторые столбцы маленькие, результаты не очень легко прочитать.
РЕДАКТИРОВАТЬ: о петле, ax.patches содержит информацию обо всех барах, которые вы строите, поэтому для каждого бара, который я назвал rect, с get_xy вы получите положение нижнего левого угла бара, и с get_height (р. get_width) получить высоту (об. ширины) бара. поэтому (x+w, y+h) дает координаты середины бара, куда вы добавляете текст value (от list_values) с функцией ax.text (параметры horizontalalignment а также verticalalignment должны центрировать текст)
РЕДАКТИРОВАТЬ 2: более общий метод, спасибо @SpghttCd за получение list_values
list_values = (dffinal.drop('final-formula', 1).groupby(['6month','Question Text']).sum()
.unstack('Question Text').fillna(0).astype(int).values.flatten('F'))
for rect, value in zip(ax.patches, list_values):
if value != 0:
h = rect.get_height() /2.
w = rect.get_width() /2.
x, y = rect.get_xy()
ax.text(x+w, y+h,value,horizontalalignment='center',verticalalignment='center')
Вы можете рассчитать x- и y-позиции меток непосредственно из вашего набора данных:
x_lbl = dffinal['6month'].values - 1
y_lbl = (df.cumsum(axis=1) - df/2).values.flatten()
Расположение меток может быть сделано так же, как для ваших данных:
df_lbl = dffinal.drop('final-formula', 1).groupby(['6month','Question Text']).sum().unstack('Question Text')
lbl = df_lbl.values.flatten()
а затем просто переберите списки ваших массивов x, y и label:
for x, y, txt in zip(x_lbl, y_lbl, lbl):
plt.text(x, y, txt, va='center', ha='center')