Застрял в понимании разницы между обновлениями использования TD(0) и TD(λ)
Я изучаю разницу во времени, изучая этот пост. Здесь правило обновления TD(0) мне ясно, но в TD(λ) я не понимаю, как значения служебной информации всех предыдущих состояний обновляются в одном обновлении.
Вот диаграмма, приведенная для сравнения обновлений ботов:
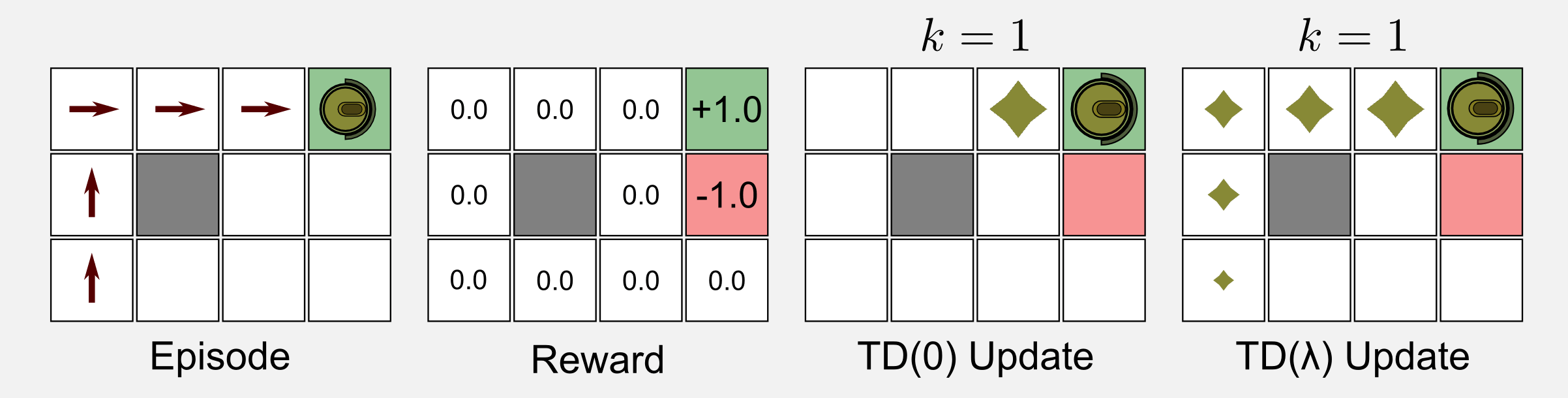
Приведенная выше схема объясняется следующим образом:
В TD(λ) результат распространяется во все предыдущие состояния благодаря следам приемлемости.
Мой вопрос заключается в том, как информация распространяется на все предыдущие состояния в одном обновлении, даже если мы используем следующее правило обновления со следами соответствия?
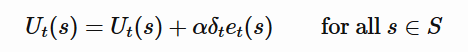
Здесь в одном обновлении мы обновляем только утилиту одного состояния Ut(s)тогда как обновляются утилиты всех предыдущих состояний?
редактировать
Что касается ответа, ясно, что это обновление применяется для каждого отдельного шага, и именно поэтому информация распространяется. Если это так, то это снова смущает меня, потому что единственное различие между правилами обновления - это трасса соответствия.
Таким образом, даже если значение трассы приемлемости не равно нулю для предыдущих состояний, значения дельты в приведенном выше случае будут равны нулю (потому что изначально вознаграждение и функция полезности инициализируются 0). Тогда как предыдущие состояния могут получить значения других утилит, отличные от нуля, при первом обновлении?
Также в данной реализации Python после одной итерации выдается следующий вывод:
[[ 0. 0.04595 0.1 0. ]
[ 0. 0. 0. 0. ]
[ 0. 0. 0. 0. ]]
Здесь обновляются только 2 значения вместо всех 5 предыдущих состояний, как показано на рисунке. Что мне здесь не хватает?
3 ответа
Таким образом, даже если значение трассы приемлемости не равно нулю для предыдущих состояний, значения delta будут равны нулю в вышеприведенном случае (потому что изначально вознаграждение и функция полезности инициализируются 0). Тогда как предыдущие состояния могут получить значения других утилит, отличные от нуля, при первом обновлении?
Вы правы в том, что в первом обновлении все награды и обновления все равно будут 0 (кроме случаев, когда нам уже удалось достичь цели за один шаг, награда не будет 0).
Тем не менее, следы приемлемости e_t будет продолжать "запоминать" или "запоминать" все состояния, которые мы посетили ранее. Таким образом, как только нам удастся достичь целевого состояния и получить ненулевое вознаграждение, следы соответствия будут помнить все состояния, через которые мы прошли. Эти состояния будут по-прежнему иметь ненулевые записи в таблице трасс приемлемости, и поэтому все сразу получат ненулевое обновление, как только вы заметите свое первое вознаграждение.
Таблица трасс приемлемости затухает при каждом временном шаге (умножается на gamma * lambda_), поэтому величина обновлений состояний, которые были посещены давно, будет меньше, чем величина обновлений состояний, которые мы посетили совсем недавно, но мы будем продолжать помнить все эти состояния, они будут иметь ненулевые записи (при условии, что gamma > 0 а также lambda_ > 0). Это позволяет обновлять значения всех посещенных состояний не сразу после того, как мы достигнем этих состояний, а как только мы наблюдаем ненулевое вознаграждение (или, в эпохи после первой эпохи, как только мы достигаем состояния для который у нас уже есть существующее ненулевое прогнозируемое значение) после посещения их в более ранний момент времени.
Также в данной реализации Python после одной итерации выдается следующий вывод:
[[ 0. 0.04595 0.1 0. ] [ 0. 0. 0. 0. ] [ 0. 0. 0. 0. ]]Здесь обновляются только 2 значения вместо всех 5 предыдущих состояний, как показано на рисунке. Что мне здесь не хватает?
Первая часть их кода выглядит следующим образом:
for epoch in range(tot_epoch):
#Reset and return the first observation
observation = env.reset(exploring_starts=True)
Итак, каждую новую эпоху они начинают со сброса окружения, используя exploring_starts флаг. Если мы посмотрим на реализацию их среды, то увидим, что использование этого флага означает, что мы всегда начинаем со случайной начальной позиции.
Итак, я подозреваю, что когда код запускался для генерации этого вывода, начальная позиция была просто случайным образом выбрана, чтобы быть позицией в двух шагах слева от цели, а не позицией в левом нижнем углу. Если начальная позиция выбирается случайным образом, чтобы она уже была ближе к цели, агент посещает только те два состояния, для которых вы видите ненулевые обновления, поэтому они также будут единственными состояниями с ненулевыми записями в таблице приемлемости. следы и, следовательно, быть единственными государствами с ненулевыми обновлениями.
Если начальная позиция действительно является позицией в нижнем левом углу, правильная реализация алгоритма действительно обновит значения для всех состояний вдоль этого пути (при условии, что дополнительные трюки не добавляются, как, например, установка записей в 0 если они окажутся "достаточно близко" к 0 из-за гниения).
Я также хотел бы отметить, что на самом деле в коде на этой странице есть ошибка: они не сбрасывают все записи таблицы трасс приемлемости в 0 при перезагрузке среды / начале новой эпохи. Это должно быть сделано. Если этого не сделать, трассы соответствия будут по-прежнему запоминать состояния, которые были посещены в предыдущие эпохи, а также обновлять все из них, даже если они не были посещены снова в новой эпохе. Это неверно Правильная версия их кода должна начинаться так:
for epoch in range(tot_epoch):
#Reset and return the first observation
observation = env.reset(exploring_starts=True)
trace_matrix = trace_matrix * 0.0 # IMPORTANT, added this
for step in range(1000):
...
Вам не хватает небольшой, но важной детали, правило обновления применяется ко всем состояниям, а не только к текущему состоянию. Таким образом, на практике вы обновляете все состояния, чьи e_t(s) отличается от нуля.
редактировать
delta не равно нулю, потому что вычисляется для текущего состояния, когда эпизод заканчивается, и агент получает вознаграждение +1. Поэтому после вычисления delta отличается от нуля, вы обновляете все состояния, используя это delta и текущие следы правомочности.
Я не знаю, почему в реализации Python (я не проверял это тщательно) выходные данные обновляют только 2 значения, но, пожалуйста, убедитесь, что трассы приемлемости для всех 5 предыдущих состояний отличаются от 0, и если это не так Попробуй понять почему. Иногда вы не заинтересованы в том, чтобы поддерживать трассировки под очень маленьким порогом (например, 10e-5), потому что это очень мало влияет на процесс обучения и приводит к потере вычислительных ресурсов.
Как можно видеть, δ используется для вычисления полезности состояний. Но, δ использует утилиту следующего состояния, как показано в статье. Это означает, что для TD(0) он обновит все состояния, потому что для вычисления Ut нам нужно вычислить U следующего состояния и так далее.
- в то же время трасса соответствия использует трассу соответствия предыдущих состояний
- В соответствии с критериями приемлемости, поскольку гамма равна 0,999 (меньше 1), лямбда = 0,5, умноженная на гамму и ламбу, дает коммунальным предприятиям сильное снижение,
- вес, добавив +1 только к состоянию текущего времени t.
- Это означает, что чем ближе мы к текущему состоянию, тем больше вес у нас и, следовательно, больше множитель
- и чем дальше, тем меньше и меньше множитель.
В TD(λ) также происходит дополнительное уменьшение при добавлении трассы приемлемости в расчет. Вышеприведенное приводит к выводу, что предыдущие значения равны 0 на первой итерации, поскольку все утилиты равны 0 в начале и в TD(λ) при обновлении они получают намного более сильное снижение по трассе соответствия. Можно сказать, что они очень маленькие, слишком маленькие, чтобы их можно было рассчитать или рассмотреть.