Добавление избыточного назначения ускоряет код при компиляции без оптимизации
Я нахожу интересное явление:
#include<stdio.h>
#include<time.h>
int main() {
int p, q;
clock_t s,e;
s=clock();
for(int i = 1; i < 1000; i++){
for(int j = 1; j < 1000; j++){
for(int k = 1; k < 1000; k++){
p = i + j * k;
q = p; //Removing this line can increase running time.
}
}
}
e = clock();
double t = (double)(e - s) / CLOCKS_PER_SEC;
printf("%lf\n", t);
return 0;
}
Я использую GCC 7.3.0 на Mac OS i5-5257U для компиляции кода без какой-либо оптимизации. Вот среднее время выполнения более 10 раз: 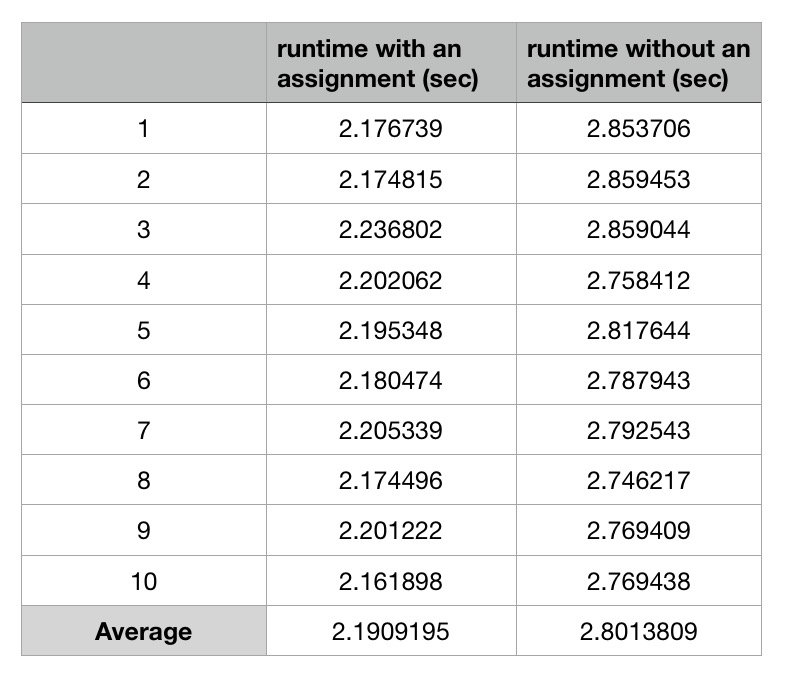 Есть и другие люди, которые тестируют кейс на других платформах Intel и получают тот же результат.
Есть и другие люди, которые тестируют кейс на других платформах Intel и получают тот же результат.
Я публикую сборку, сгенерированную GCC здесь. Единственная разница между двумя кодами сборки заключается в том, что до addl $1, -12(%rbp) быстрее выполняется еще две операции:
movl -44(%rbp), %eax
movl %eax, -48(%rbp)
Так почему же при таком назначении программа работает быстрее?
Ответ Питера очень полезен. Тесты на AMD Phenom II X4 810 и процессоре ARMv7 (BCM2835) показывают противоположный результат, который подтверждает, что ускорение пересылки в хранилище характерно для некоторых процессоров Intel.
А комментарии и советы BeeOnRope заставляют меня переписать вопрос.:)
Суть этого вопроса - интересное явление, связанное с архитектурой и сборкой процессора. Поэтому я думаю, что это стоит того, чтобы обсудить.
1 ответ
Вы тестируете отладочную сборку, которая в принципе бесполезна.
Но, очевидно, существует реальная причина того, что отладочная сборка одной версии работает медленнее, чем отладочная сборка другой версии. (Предполагая, что вы измерили правильно, и это было не просто изменение частоты процессора (турбо / энергосбережение), приводящее к разнице во времени настенных часов.)
Если вы хотите вникнуть в детали анализа производительности x86, мы можем попытаться объяснить, почему asm работает так, как он это делает, и почему asm из дополнительного оператора C (который с -O0 компилируется в дополнительные инструкции asm) может сделать это быстрее в целом. Это скажет нам кое-что об эффектах производительности asm, но ничего полезного в оптимизации C.
Вы не показали весь внутренний цикл, только часть тела цикла, но gcc -O0 довольно предсказуемо Каждый оператор C компилируется отдельно от всех остальных, причем все переменные C распределяются / перезагружаются между блоками для каждого оператора. Это позволяет вам изменять переменные с помощью отладчика при пошаговом выполнении или даже переходить к другой строке в функции, и код по-прежнему работает. Стоимость компиляции таким образом катастрофична. Например, ваш цикл не имеет побочных эффектов (ни один из результатов не используется), поэтому весь цикл с тройным вложением может и будет компилироваться в ноль инструкций в реальной сборке, работая бесконечно быстрее.
Узким местом является, вероятно, зависимость, переносимая циклами от k, с магазином / перезагрузкой и add увеличить. Задержка пересылки в магазине обычно составляет около 5 циклов на большинстве процессоров. И, таким образом, ваш внутренний цикл ограничен выполнением один раз в ~6 циклов, задержка места назначения памяти add,
Если вы используете процессор Intel, задержка хранения / перезагрузки может быть на самом деле ниже (лучше), когда перезагрузка не может быть выполнена сразу же. Наличие большего количества независимых загрузок / хранилищ между зависимыми парами может объяснить это в вашем случае. См. Цикл с вызовом функции быстрее, чем пустой цикл.
Так что с большей работой в цикле, что addl $1, -12(%rbp) который может выдерживать пропускную способность один на 6 циклов при параллельном запуске, вместо этого может создать узкое место в одну итерацию на 4 или 5 циклов.
Обновление: этот эффект, по-видимому, происходит на Sandybridge и Haswell, согласно измерениям из сообщения в блоге 2013 года, так что да, это также наиболее вероятное объяснение на вашем Broadwell i5-5257U. Похоже, что этот эффект происходит на всех процессорах семейства Intel Sandybridge.
Без дополнительной информации о тестовом оборудовании, версии компилятора (или источника asm для внутреннего цикла), а также абсолютных и / или относительных показателей производительности для обеих версий, это мое лучшее предположение без особых усилий при объяснении. Бенчмаркинг / профилирование gcc -O0 на моей системе Skylake не достаточно интересно, чтобы на самом деле попробовать это сам. В следующий раз включите временные числа.
Задержка хранения / перезагрузки для всей работы, которая не является частью цепочки зависимостей, переносимых циклом, не имеет значения, только пропускная способность. Очередь хранилища в современных процессорах, вышедших из строя, эффективно обеспечивает переименование памяти, устраняя опасность записи после записи и записи после чтения от повторного использования одной и той же стековой памяти для p быть написанным, а затем читать и писать в другом месте. (См. https://en.wikipedia.org/wiki/Memory_disambiguation для получения дополнительной информации об опасностях памяти, в частности, и в этом разделе " Вопросы и ответы" для получения дополнительной информации о задержке и пропускной способности и повторном использовании одного и того же регистра / переименования регистров)
Несколько итераций внутреннего цикла могут быть запущены одновременно, поскольку буфер порядка памяти отслеживает, из какого хранилища должна извлекаться каждая загрузка данных, не требуя предыдущего хранилища в том же месте для фиксации в L1D и выхода из хранить очередь. (См. Руководство по оптимизации Intel и PDF-файл Agner Fog для получения дополнительной информации о внутренних процессорах микроархитектуры ЦП.)
Означает ли это, что добавление бесполезных операторов ускорит работу реальных программ? (с включенной оптимизацией)
В общем, нет, это не так. Компиляторы хранят переменные цикла в регистрах для самых внутренних циклов. И бесполезные заявления фактически оптимизируют с включенной оптимизацией.
Настройка вашего источника для gcc -O0 бесполезно. Мера с -O3 или любой другой вариант, используемый сценариями сборки по умолчанию для вашего проекта.
Кроме того, это ускорение пересылки магазина характерно для семейства Intel Sandybridge, и вы не увидите его на других микроархитектурах, таких как Ryzen, если только у них нет аналогичного эффекта задержки пересылки магазина.
Задержка пересылки в хранилище может быть проблемой при реальном (оптимизированном) выводе компилятора, особенно если вы не использовали оптимизацию по времени канала (LTO), чтобы позволить встроенным функциям крошечных функций, особенно функциям, которые передают или возвращают что-либо по ссылке (так пройти через память вместо регистров). Смягчение проблемы может потребовать таких хаков, как volatile если вы действительно хотите обойти это на процессорах Intel и, возможно, ухудшить ситуацию на некоторых других процессорах. Смотрите обсуждение в комментариях