SQL Server: переведите все ВЕРХНИЕ дела в надлежащие дела / заглавные дела
У меня есть таблица, которая была импортирована как все UPPER CASE, и я хотел бы превратить ее в правильный случай. Какой сценарий кто-нибудь из вас использовал для этого?
25 ответов
Вот UDF, который сделает свое дело...
create function ProperCase(@Text as varchar(8000))
returns varchar(8000)
as
begin
declare @Reset bit;
declare @Ret varchar(8000);
declare @i int;
declare @c char(1);
if @Text is null
return null;
select @Reset = 1, @i = 1, @Ret = '';
while (@i <= len(@Text))
select @c = substring(@Text, @i, 1),
@Ret = @Ret + case when @Reset = 1 then UPPER(@c) else LOWER(@c) end,
@Reset = case when @c like '[a-zA-Z]' then 0 else 1 end,
@i = @i + 1
return @Ret
end
Вам все равно придется использовать его для обновления ваших данных.
Эта функция:
- "Собственные случаи" - все слова "UPPER CASE", разделенные пробелами.
- оставляет "строчные слова" в покое
- работает правильно даже для неанглийских алфавитов
- портативен тем, что не использует необычные функции последних версий SQL-сервера
- можно легко изменить, чтобы использовать NCHAR и NVARCHAR для поддержки юникода, а также любую длину параметра, которую вы считаете подходящей
- определение пустого пространства может быть настроено
CREATE FUNCTION ToProperCase(@string VARCHAR(255)) RETURNS VARCHAR(255)
AS
BEGIN
DECLARE @i INT -- index
DECLARE @l INT -- input length
DECLARE @c NCHAR(1) -- current char
DECLARE @f INT -- first letter flag (1/0)
DECLARE @o VARCHAR(255) -- output string
DECLARE @w VARCHAR(10) -- characters considered as white space
SET @w = '[' + CHAR(13) + CHAR(10) + CHAR(9) + CHAR(160) + ' ' + ']'
SET @i = 1
SET @l = LEN(@string)
SET @f = 1
SET @o = ''
WHILE @i <= @l
BEGIN
SET @c = SUBSTRING(@string, @i, 1)
IF @f = 1
BEGIN
SET @o = @o + @c
SET @f = 0
END
ELSE
BEGIN
SET @o = @o + LOWER(@c)
END
IF @c LIKE @w SET @f = 1
SET @i = @i + 1
END
RETURN @o
END
Результат:
dbo.ToProperCase('ALL UPPER CASE and SOME lower ÄÄ ÖÖ ÜÜ ÉÉ ØØ ĈĈ ÆÆ')
-----------------------------------------------------------------
All Upper Case and Some lower Ää Öö Üü Éé Øø Cc Ææ
UPDATE titles
SET title =
UPPER(LEFT(title, 1)) +
LOWER(RIGHT(title, LEN(title) - 1))
Если вы можете включить CLR в SQL Server (требуется 2005 или более поздняя версия), то вы можете создать функцию CLR, которая использует встроенную функцию TextInfo.ToTitleCase, которая позволит вам создать культурный способ сделать это всего за несколько строки кода.
Я знаю, что это поздний пост в этой теме, но стоит посмотреть. Эта функция работает для меня всегда. Так что думал поделиться этим.
CREATE FUNCTION [dbo].[fnConvert_TitleCase] (@InputString VARCHAR(4000) )
RETURNS VARCHAR(4000)
AS
BEGIN
DECLARE @Index INT
DECLARE @Char CHAR(1)
DECLARE @OutputString VARCHAR(255)
SET @OutputString = LOWER(@InputString)
SET @Index = 2
SET @OutputString = STUFF(@OutputString, 1, 1,UPPER(SUBSTRING(@InputString,1,1)))
WHILE @Index <= LEN(@InputString)
BEGIN
SET @Char = SUBSTRING(@InputString, @Index, 1)
IF @Char IN (' ', ';', ':', '!', '?', ',', '.', '_', '-', '/', '&','''','(')
IF @Index + 1 <= LEN(@InputString)
BEGIN
IF @Char != ''''
OR
UPPER(SUBSTRING(@InputString, @Index + 1, 1)) != 'S'
SET @OutputString =
STUFF(@OutputString, @Index + 1, 1,UPPER(SUBSTRING(@InputString, @Index + 1, 1)))
END
SET @Index = @Index + 1
END
RETURN ISNULL(@OutputString,'')
END
Тестовые звонки:
select dbo.fnConvert_TitleCase(Upper('ÄÄ ÖÖ ÜÜ ÉÉ ØØ ĈĈ ÆÆ')) as test
select dbo.fnConvert_TitleCase(upper('Whatever the mind of man can conceive and believe, it can achieve. – Napoleon hill')) as test
Результаты:
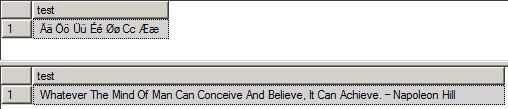
Я немного опаздываю в игре, но я считаю, что она более функциональна и работает с любым языком, включая русский, немецкий, тайский, вьетнамский и т. Д. Она будет писать заглавными буквами все после 'или - или. или (или) или пробел (очевидно:).
CREATE FUNCTION [dbo].[fnToProperCase]( @name nvarchar(500) )
RETURNS nvarchar(500)
AS
BEGIN
declare @pos int = 1
, @pos2 int
if (@name <> '')--or @name = lower(@name) collate SQL_Latin1_General_CP1_CS_AS or @name = upper(@name) collate SQL_Latin1_General_CP1_CS_AS)
begin
set @name = lower(rtrim(@name))
while (1 = 1)
begin
set @name = stuff(@name, @pos, 1, upper(substring(@name, @pos, 1)))
set @pos2 = patindex('%[- ''.)(]%', substring(@name, @pos, 500))
set @pos += @pos2
if (isnull(@pos2, 0) = 0 or @pos > len(@name))
break
end
end
return @name
END
GO
На Server Server 2016 и новее вы можете использовать STRING_SPLIT
with t as (
select 'GOOFYEAR Tire and Rubber Company' as n
union all
select 'THE HAPPY BEAR' as n
union all
select 'MONK HOUSE SALES' as n
union all
select 'FORUM COMMUNICATIONS' as n
)
select
n,
(
select ' ' + (
upper(left(value, 1))
+ lower(substring(value, 2, 999))
)
from (
select value
from string_split(t.n, ' ')
) as sq
for xml path ('')
) as title_cased
from t
пример
Если вы работаете с SSIS, импортирующим данные со смешанным регистром, и вам нужно выполнить поиск по столбцу с соответствующим регистром, вы заметите, что поиск не удастся, когда источник смешан, а источник поиска правильный. Вы также заметите, что не можете использовать правую и левую функции SSIS для SQL Server 2008r2 для производных столбцов. Вот решение, которое работает для меня:
UPPER(substring(input_column_name,1,1)) + LOWER(substring(input_column_name, 2, len(input_column_name)-1))
Вот версия, которая использует таблицу последовательности или чисел, а не цикл. Вы можете изменить предложение WHERE, чтобы оно соответствовало вашим личным правилам, когда нужно преобразовывать символ в верхний регистр. Я только что включил простой набор, который будет заглавными буквами любой буквы, за которой следует не буква, за исключением апострофов. Это означает, что 123apple будет иметь совпадение на "a", потому что "3" не является буквой. Если вам нужен только пробел (пробел, табуляция, возврат каретки, перевод строки), вы можете заменить шаблон '[^a-z]' с '[' + Char(32) + Char(9) + Char(13) + Char(10) + ']',
CREATE FUNCTION String.InitCap( @string nvarchar(4000) ) RETURNS nvarchar(4000) AS
BEGIN
-- 1. Convert all letters to lower case
DECLARE @InitCap nvarchar(4000); SET @InitCap = Lower(@string);
-- 2. Using a Sequence, replace the letters that should be upper case with their upper case version
SELECT @InitCap = Stuff( @InitCap, n, 1, Upper( SubString( @InitCap, n, 1 ) ) )
FROM (
SELECT (1 + n1.n + n10.n + n100.n + n1000.n) AS n
FROM (SELECT 0 AS n UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9) AS n1
CROSS JOIN (SELECT 0 AS n UNION SELECT 10 UNION SELECT 20 UNION SELECT 30 UNION SELECT 40 UNION SELECT 50 UNION SELECT 60 UNION SELECT 70 UNION SELECT 80 UNION SELECT 90) AS n10
CROSS JOIN (SELECT 0 AS n UNION SELECT 100 UNION SELECT 200 UNION SELECT 300 UNION SELECT 400 UNION SELECT 500 UNION SELECT 600 UNION SELECT 700 UNION SELECT 800 UNION SELECT 900) AS n100
CROSS JOIN (SELECT 0 AS n UNION SELECT 1000 UNION SELECT 2000 UNION SELECT 3000) AS n1000
) AS Sequence
WHERE
n BETWEEN 1 AND Len( @InitCap )
AND SubString( @InitCap, n, 1 ) LIKE '[a-z]' /* this character is a letter */
AND (
n = 1 /* this character is the first `character` */
OR SubString( @InitCap, n-1, 1 ) LIKE '[^a-z]' /* the previous character is NOT a letter */
)
AND (
n < 3 /* only test the 3rd or greater characters for this exception */
OR SubString( @InitCap, n-2, 3 ) NOT LIKE '[a-z]''[a-z]' /* exception: The pattern <letter>'<letter> should not capatolize the letter following the apostrophy */
)
-- 3. Return the modified version of the input
RETURN @InitCap
END
Небольшая модификация ответа @Galwegian - который, например, St Elizabeth's в St Elizabeth'S.
Эта модификация сохраняет апостроф-s в нижнем регистре, где s находится в конце предоставленной строки или s следует за пробелом (и только в этих обстоятельствах).
create function properCase(@text as varchar(8000))
returns varchar(8000)
as
begin
declare @reset int;
declare @ret varchar(8000);
declare @i int;
declare @c char(1);
declare @d char(1);
if @text is null
return null;
select @reset = 1, @i = 1, @ret = '';
while (@i <= len(@text))
select
@c = substring(@text, @i, 1),
@d = substring(@text, @i+1, 1),
@ret = @ret + case when @reset = 1 or (@reset=-1 and @c!='s') or (@reset=-1 and @c='s' and @d!=' ') then upper(@c) else lower(@c) end,
@reset = case when @c like '[a-za-z]' then 0 when @c='''' then -1 else 1 end,
@i = @i + 1
return @ret
end
Получается:
st elizabeth'sвSt Elizabeth'so'keefeвO'Keefeo'sullivanвO'Sullivan
Комментарии других о том, что для ввода не на английском языке предпочтительнее другие решения, остаются в силе.
Если вы знаете, что все данные - это всего лишь одно слово, вот решение. Сначала обновите столбец до всех нижних, а затем выполните следующее
update tableName set columnName =
upper(SUBSTRING(columnName, 1, 1)) + substring(columnName, 2, len(columnName)) from tableName
В Oracle SQL или PostgreSQL просто выполните:
SELECT INITCAP(title) FROM data;
В SQL Server сначала определите функцию, как показано ниже, затем:
SELECT dbo.InitCap(title) FROM data;
Определите dbo.InitCap():
-- Drop the function if it already exists
IF OBJECT_ID('dbo.InitCap') IS NOT NULL
DROP FUNCTION dbo.InitCap;
GO
-- Implementing Oracle INITCAP function
CREATE FUNCTION dbo.InitCap (@inStr VARCHAR(8000))
RETURNS VARCHAR(8000)
AS
BEGIN
DECLARE @outStr VARCHAR(8000) = LOWER(@inStr),
@char CHAR(1),
@alphanum BIT = 0,
@len INT = LEN(@inStr),
@pos INT = 1;
-- Iterate through all characters in the input string
WHILE @pos <= @len BEGIN
-- Get the next character
SET @char = SUBSTRING(@inStr, @pos, 1);
-- If the position is first, or the previous characater is not alphanumeric
-- convert the current character to upper case
IF @pos = 1 OR @alphanum = 0
SET @outStr = STUFF(@outStr, @pos, 1, UPPER(@char));
SET @pos = @pos + 1;
-- Define if the current character is non-alphanumeric
IF ASCII(@char) <= 47 OR (ASCII(@char) BETWEEN 58 AND 64) OR
(ASCII(@char) BETWEEN 91 AND 96) OR (ASCII(@char) BETWEEN 123 AND 126)
SET @alphanum = 0;
ELSE
SET @alphanum = 1;
END
RETURN @outStr;
END
GO
Заимствовал и улучшил ответ @Richard Sayakanit. Это обрабатывает несколько слов. Как и его ответ, здесь не используются пользовательские функции, только встроенные функции (STRING_SPLIT а также STRING_AGG) и это довольно быстро. STRING_AGG требует SQL Server 2017, но вы всегда можете использовать STUFF/XML трюк. Не будет обрабатывать все исключения, но может отлично работать для многих требований.
SELECT StateName = 'North Carolina'
INTO #States
UNION ALL
SELECT 'Texas'
;WITH cteData AS
(
SELECT
UPPER(LEFT(value, 1)) +
LOWER(RIGHT(value, LEN(value) - 1)) value, op.StateName
FROM #States op
CROSS APPLY STRING_SPLIT(op.StateName, ' ') AS ss
)
SELECT
STRING_AGG(value, ' ')
FROM cteData c
GROUP BY StateName
Недавно пришлось заняться этим и придумал следующее после того, как ничто не поразило все, что я хотел. Это сделает все предложение, случаи для специальной обработки слов. У нас также были проблемы с односимвольными "словами", которые обрабатываются многими более простыми методами, но не более сложными. Однократная возвращаемая переменная, без циклов и курсоров.
CREATE FUNCTION ProperCase(@Text AS NVARCHAR(MAX))
RETURNS NVARCHAR(MAX)
AS BEGIN
DECLARE @return NVARCHAR(MAX)
SELECT @return = COALESCE(@return + ' ', '') + Word FROM (
SELECT CASE
WHEN LOWER(value) = 'llc' THEN UPPER(value)
WHEN LOWER(value) = 'lp' THEN UPPER(value) --Add as many new special cases as needed
ELSE
CASE WHEN LEN(value) = 1
THEN UPPER(value)
ELSE UPPER(LEFT(value, 1)) + (LOWER(RIGHT(value, LEN(value) - 1)))
END
END AS Word
FROM STRING_SPLIT(@Text, ' ')
) tmp
RETURN @return
END
Я знаю, что дьявол кроется в деталях (особенно в том, что касается личных данных людей), и что было бы очень хорошо иметь правильно написанные заглавными буквами имена, но из-за вышеупомянутого рода хлопот, почему прагматичные, осознающие время среди нас используют следующее:
SELECT UPPER('Put YoUR O'So oddLy casED McWeird-nAme von rightHERE here')
По моему опыту, люди хорошо видят ИМЯ... даже когда оно на полпути к предложению.
Обратитесь к: русские использовали карандаш!
Ссылка, которую я разместил выше, является отличным вариантом, который решает основную проблему: мы никогда не сможем программно учесть все случаи (Смит-Джонс, фон Хауссен, Джон Смит, доктор медицины), по крайней мере, элегантно. Тони вводит концепцию символа исключения / прерывания, чтобы иметь дело с этими случаями. В любом случае, основываясь на идее Черво (верхние все нижние символы предшествуют пробелом), операторы замены могут быть помещены в одну замену на основе таблицы. На самом деле, любая комбинация символов "низкий / повышенный" может быть вставлена в @alpha, и оператор не изменится:
declare @str nvarchar(8000)
declare @alpha table (low nchar(1), up nchar(1))
set @str = 'ALL UPPER CASE and SOME lower ÄÄ ÖÖ ÜÜ ÉÉ ØØ ĈĈ ÆÆ'
-- stage the alpha (needs number table)
insert into @alpha
-- A-Z / a-z
select nchar(n+32),
nchar(n)
from dbo.Number
where n between 65 and 90 or
n between 192 and 223
-- append space at start of str
set @str = lower(' ' + @str)
-- upper all lower case chars preceded by space
select @str = replace(@str, ' ' + low, ' ' + up)
from @Alpha
select @str
Было бы целесообразно вести поиск исключений, чтобы позаботиться о фон Неймана, Маккейна, ДеГузмана и Джонсона-Смита.
Я думаю, вы найдете, что следующее более эффективно:
IF OBJECT_ID('dbo.ProperCase') IS NOT NULL
DROP FUNCTION dbo.ProperCase
GO
CREATE FUNCTION dbo.PROPERCASE (
@str VARCHAR(8000))
RETURNS VARCHAR(8000)
AS
BEGIN
SET @str = ' ' + @str
SET @str = REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE( @str, ' a', ' A'), ' b', ' B'), ' c', ' C'), ' d', ' D'), ' e', ' E'), ' f', ' F'), ' g', ' G'), ' h', ' H'), ' i', ' I'), ' j', ' J'), ' k', ' K'), ' l', ' L'), ' m', ' M'), ' n', ' N'), ' o', ' O'), ' p', ' P'), ' q', ' Q'), ' r', ' R'), ' s', ' S'), ' t', ' T'), ' u', ' U'), ' v', ' V'), ' w', ' W'), ' x', ' X'), ' y', ' Y'), ' z', ' Z')
RETURN RIGHT(@str, LEN(@str) - 1)
END
GO
Оператор замены может быть вырезан и вставлен непосредственно в запрос SQL. Это очень уродливо, однако, заменив @str на интересующий вас столбец, вы не будете платить цену за неявный курсор, как и при размещенных таким образом udf. Я считаю, что даже используя мой UDF, он намного эффективнее.
Ох, и вместо генерации оператора замены используйте это:
-- Code Generator for expression
DECLARE @x INT,
@c CHAR(1),
@sql VARCHAR(8000)
SET @x = 0
SET @sql = '@str' -- actual variable/column you want to replace
WHILE @x < 26
BEGIN
SET @c = CHAR(ASCII('a') + @x)
SET @sql = 'REPLACE(' + @sql + ', '' ' + @c+ ''', '' ' + UPPER(@c) + ''')'
SET @x = @x + 1
END
PRINT @sql
Во всяком случае, это зависит от количества строк. Я бы хотел, чтобы вы просто делали s/\b([az])/uc $1/, ну да ладно, мы работаем с инструментами, которые у нас есть.
Обратите внимание, что вам придется использовать это, как если бы вы использовали его как...SELECT dbo.ProperCase(LOWER(column)), так как столбец в верхнем регистре. Это на самом деле работает довольно быстро на моей таблице из 5000 записей (даже не одной секунды), даже с нижней.
В ответ на поток комментариев относительно интернационализации я представляю следующую реализацию, которая обрабатывает каждый символ ascii, полагаясь только на реализацию SQL Server верхнего и нижнего уровней. Помните, что переменные, которые мы здесь используем, являются VARCHAR, что означает, что они могут содержать только значения ASCII. Чтобы использовать другие международные алфавиты, вы должны использовать NVARCHAR. Логика была бы аналогичной, но вам нужно было бы использовать UNICODE и NCHAR вместо ASCII и CHAR, а оператор замены был бы намного более громоздким....
-- Code Generator for expression
DECLARE @x INT,
@c CHAR(1),
@sql VARCHAR(8000),
@count INT
SEt @x = 0
SET @count = 0
SET @sql = '@str' -- actual variable you want to replace
WHILE @x < 256
BEGIN
SET @c = CHAR(@x)
-- Only generate replacement expression for characters where upper and lowercase differ
IF @x = ASCII(LOWER(@c)) AND @x != ASCII(UPPER(@c))
BEGIN
SET @sql = 'REPLACE(' + @sql + ', '' ' + @c+ ''', '' ' + UPPER(@c) + ''')'
SET @count = @count + 1
END
SET @x = @x + 1
END
PRINT @sql
PRINT 'Total characters substituted: ' + CONVERT(VARCHAR(255), @count)
По сути, предпосылка метода my заключается в обмене предварительными вычислениями на эффективность. Полная реализация ASCII выглядит следующим образом:
IF OBJECT_ID('dbo.ProperCase') IS NOT NULL
DROP FUNCTION dbo.ProperCase
GO
CREATE FUNCTION dbo.PROPERCASE (
@str VARCHAR(8000))
RETURNS VARCHAR(8000)
AS
BEGIN
SET @str = ' ' + @str
SET @str = REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(@str, ' a', ' A'), ' b', ' B'), ' c', ' C'), ' d', ' D'), ' e', ' E'), ' f', ' F'), ' g', ' G'), ' h', ' H'), ' i', ' I'), ' j', ' J'), ' k', ' K'), ' l', ' L'), ' m', ' M'), ' n', ' N'), ' o', ' O'), ' p', ' P'), ' q', ' Q'), ' r', ' R'), ' s', ' S'), ' t', ' T'), ' u', ' U'), ' v', ' V'), ' w', ' W'), ' x', ' X'), ' y', ' Y'), ' z', ' Z'), ' š', ' Š'), ' œ', ' Œ'), ' ž', ' Ž'), ' à', ' À'), ' á', ' Á'), ' â', ' Â'), ' ã', ' Ã'), ' ä', ' Ä'), ' å', ' Å'), ' æ', ' Æ'), ' ç', ' Ç'), ' è', ' È'), ' é', ' É'), ' ê', ' Ê'), ' ë', ' Ë'), ' ì', ' Ì'), ' í', ' Í'), ' î', ' Î'), ' ï', ' Ï'), ' ð', ' Ð'), ' ñ', ' Ñ'), ' ò', ' Ò'), ' ó', ' Ó'), ' ô', ' Ô'), ' õ', ' Õ'), ' ö', ' Ö'), ' ø', ' Ø'), ' ù', ' Ù'), ' ú', ' Ú'), ' û', ' Û'), ' ü', ' Ü'), ' ý', ' Ý'), ' þ', ' Þ'), ' ÿ', ' Ÿ')
RETURN RIGHT(@str, LEN(@str) - 1)
END
GO
Вот еще один вариант, который я нашел на форумах SQLTeam.com @ http://www.sqlteam.com/forums/topic.asp?TOPIC_ID=47718
create FUNCTION PROPERCASE
(
--The string to be converted to proper case
@input varchar(8000)
)
--This function returns the proper case string of varchar type
RETURNS varchar(8000)
AS
BEGIN
IF @input IS NULL
BEGIN
--Just return NULL if input string is NULL
RETURN NULL
END
--Character variable declarations
DECLARE @output varchar(8000)
--Integer variable declarations
DECLARE @ctr int, @len int, @found_at int
--Constant declarations
DECLARE @LOWER_CASE_a int, @LOWER_CASE_z int, @Delimiter char(3), @UPPER_CASE_A int, @UPPER_CASE_Z int
--Variable/Constant initializations
SET @ctr = 1
SET @len = LEN(@input)
SET @output = ''
SET @LOWER_CASE_a = 97
SET @LOWER_CASE_z = 122
SET @Delimiter = ' ,-'
SET @UPPER_CASE_A = 65
SET @UPPER_CASE_Z = 90
WHILE @ctr <= @len
BEGIN
--This loop will take care of reccuring white spaces
WHILE CHARINDEX(SUBSTRING(@input,@ctr,1), @Delimiter) > 0
BEGIN
SET @output = @output + SUBSTRING(@input,@ctr,1)
SET @ctr = @ctr + 1
END
IF ASCII(SUBSTRING(@input,@ctr,1)) BETWEEN @LOWER_CASE_a AND @LOWER_CASE_z
BEGIN
--Converting the first character to upper case
SET @output = @output + UPPER(SUBSTRING(@input,@ctr,1))
END
ELSE
BEGIN
SET @output = @output + SUBSTRING(@input,@ctr,1)
END
SET @ctr = @ctr + 1
WHILE CHARINDEX(SUBSTRING(@input,@ctr,1), @Delimiter) = 0 AND (@ctr <= @len)
BEGIN
IF ASCII(SUBSTRING(@input,@ctr,1)) BETWEEN @UPPER_CASE_A AND @UPPER_CASE_Z
BEGIN
SET @output = @output + LOWER(SUBSTRING(@input,@ctr,1))
END
ELSE
BEGIN
SET @output = @output + SUBSTRING(@input,@ctr,1)
END
SET @ctr = @ctr + 1
END
END
RETURN @output
END
GO
SET QUOTED_IDENTIFIER OFF
GO
SET ANSI_NULLS ON
GO
Это работало в SSMS:
Select Jobtitle,
concat(Upper(LEFT(jobtitle,1)), SUBSTRING(jobtitle,2,LEN(jobtitle))) as Propercase
From [HumanResources].[Employee]
Только что узнал о InitCap(),
Вот пример кода:
SELECT ID
,InitCap(LastName ||', '|| FirstName ||' '|| Nvl(MiddleName,'')) AS RecipientName
FROM SomeTable
К сожалению, я предлагаю еще одну функцию. Этот кажется быстрее, чем большинство, но использует только первую букву слов, разделенных пробелами. Я проверил, что ввод не равен нулю, и что он работает, если у вас есть несколько пробелов где-то в середине строки. Я перекрестно применяю функцию длины, поэтому мне не нужно вызывать ее дважды. Я бы подумал, что SQL Server кэширует это значение. Пусть покупатель будет бдителен.
CREATE OR ALTER FUNCTION dbo.ProperCase(@value varchar(MAX)) RETURNS varchar(MAX) AS
BEGIN
RETURN (SELECT STRING_AGG(CASE lv WHEN 0 THEN '' WHEN 1 THEN UPPER(value)
ELSE UPPER(LEFT(value,1)) + LOWER(RIGHT(value,lv-1)) END,' ')
FROM STRING_SPLIT(TRIM(@value),' ') AS ss
CROSS APPLY (SELECT LEN(VALUE) lv) AS reuse
WHERE @value IS NOT NULL)
END
Эта функция у меня сработала
create function [dbo].Pascal (@string varchar(max))
returns varchar(max)
as
begin
declare @Index int
,@ResultString varchar(max)
set @Index = 1
set @ResultString = ''
while (@Index < LEN(@string) + 1)
begin
if (@Index = 1)
begin
set @ResultString += UPPER(SUBSTRING(@string, @Index, 1))
set @Index += 1
end
else if (
(
SUBSTRING(@string, @Index - 1, 1) = ' '
or SUBSTRING(@string, @Index - 1, 1) = '-'
or SUBSTRING(@string, @Index + 1, 1) = '-'
)
and @Index + 1 <> LEN(@string) + 1
)
begin
set @ResultString += UPPER(SUBSTRING(@string, @Index, 1))
set @Index += 1
end
else
begin
set @ResultString += LOWER(SUBSTRING(@string, @Index, 1))
set @Index += 1
end
end
if (@@ERROR <> 0)
begin
set @ResultString = @string
end
return replace(replace(replace(@ResultString, ' ii', ' II'), ' iii', ' III'), ' iv', ' IV')
end
Не слишком ли поздно вернуться и получить данные без заглавных букв?
Фон Неймана, Маккейна, ДеГузмана и Джонсона-Смита вашей клиентской базы может не понравиться результат вашей обработки...
Кроме того, я предполагаю, что это должно быть разовое обновление данных? Возможно, будет проще экспортировать, фильтровать / изменять и повторно импортировать исправленные имена в базу данных, а затем вы можете использовать не-SQL подходы для фиксации имен...
Скопируйте и вставьте свои данные в MS Word и используйте встроенное преобразование текста, чтобы "использовать заглавные буквы в каждом слове". Сравните с вашими исходными данными, чтобы устранить исключения. Не вижу способа вручную обойти исключения типа "MacDonald" и "IBM", но именно так я сделал FWIW.