Регулярное выражение, чтобы найти строку, включенную между двумя символами при ИСКЛЮЧЕНИИ разделителей
Мне нужно извлечь из строки набор символов, которые находятся между двумя разделителями, не возвращая сами разделители.
Простой пример должен быть полезен:
Цель: извлечь подстроку в квадратных скобках, не возвращая сами скобки.
Базовая строка: This is a test string [more or less]
Если я использую следующие рег. ех.
\ [. *? \]
Матч [more or less], Мне нужно только получить more or less (без скобок).
Возможно ли это сделать?
13 ответов
Легко сделано:
(?<=\[)(.*?)(?=\])
Технически это использует lookaheads и lookbehinds. См. Утверждение Lookahead и Lookbehind Утверждения нулевой ширины. Шаблон состоит из:
- предшествует [который не захвачен (взгляд сзади);
- не жадная захваченная группа. Нежадно останавливаться на первом]; а также
- сопровождается], который не захвачен (взгляд вперед).
В качестве альтернативы вы можете просто взять то, что находится в квадратных скобках:
\[(.*?)\]
и вернуть первую захваченную группу вместо всего совпадения.
Если вы используете JavaScript, первое решение, предоставляемое Cletus, (?<=\[)(.*?)(?=\]), не будет работать, потому что JavaScript не поддерживает оператор lookbehind.
Тем не менее, второе решение работает хорошо, но вам нужно получить второй соответствующий элемент.
Пример:
var regex = /\[(.*?)\]/;
var strToMatch = "This is a test string [more or less]";
var matched = regex.exec(strToMatch);
Он вернется:
["[more or less]", "more or less"]
Итак, что вам нужно, это второе значение. Использование:
var matched = regex.exec(strToMatch)[1];
Возвращать:
"more or less"
Вам просто нужно "захватить" бит между скобками.
\[(.*?)\]
Для захвата вы положите его в скобки. Вы не говорите, на каком языке это используется. Например, в Perl вы могли бы получить к нему доступ, используя переменную $1.
my $string ='This is the match [more or less]';
$string =~ /\[(.*?)\]/;
print "match:$1\n";
Другие языки будут иметь разные механизмы. Я полагаю, что в C# используется класс коллекции Match.
Вот общий пример с очевидными разделителями (и):
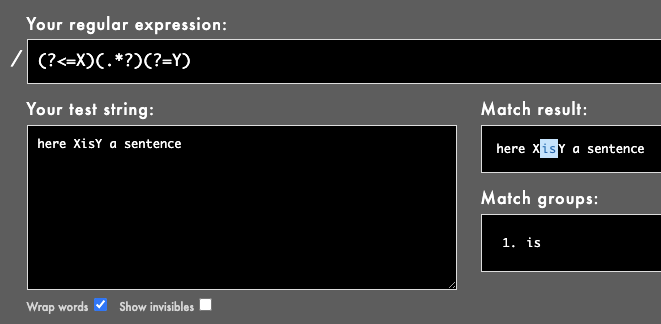
(?<=X)(.*?)(?=Y)
Здесь он используется для поиска строки между
X а также
Y. Рубулярный пример здесь , или см. Изображение:
[^\[] Подберите любой символ, который не [.
+ Матч 1 или более из всего, что не [, Создает группы из этих матчей.
(?=\]) Позитивный взгляд ], Соответствует группе, заканчивающейся на ] без включения его в результат.
Готово.
[^\[]+(?=\])
Доказательство.
Аналогично решению, предложенному null. Но дополнительный \] не требуется. В качестве дополнительной заметки \ не требуется избегать [ после ^, Для удобства чтения я бы оставил это в.
Не работает в ситуации, в которой разделители идентичны. "more or less" например.
Самое обновленное решение
Если вы используете Javascript, лучшее решение, которое я придумал, - использовать match вместо того execметод. Затем выполните итерацию совпадений и удалите разделители с результатом первой группы, используя$1
const text = "This is a test string [more or less], [more] and [less]";
const regex = /\[(.*?)\]/gi;
const resultMatchGroup = text.match(regex); // [ '[more or less]', '[more]', '[less]' ]
const desiredRes = resultMatchGroup.map(match => match.replace(regex, "$1"))
console.log("desiredRes", desiredRes); // [ 'more or less', 'more', 'less' ]
Как видите, это также полезно для нескольких разделителей в тексте.
PHP:
$string ='This is the match [more or less]';
preg_match('#\[(.*)\]#', $string, $match);
var_dump($match[1]);
Это специально работает для парсера регулярных выражений javascript /[^[\]]+(?=])/g
просто запустите это в консоли
var regex = /[^[\]]+(?=])/g;
var str = "This is a test string [more or less]";
var match = regex.exec(str);
match;
У меня была та же проблема с использованием регулярных выражений с сценариями Bash. Я использовал двухэтапное решение, используя трубы с применением grep -o
'\[(.*?)\]'
будет первый
'\b.*\b'
Очевидно, не так эффективно, как другие ответы, но альтернатива.
Я хотел найти строку между / и #, но # иногда не является обязательным. Вот регулярное выражение, которое я использую:
(?<=\/)([^#]+)(?=#*)
Вот как я обошелся без '[' и ']' в C#:
var text = "This is a test string [more or less]";
//Getting only string between '[' and ']'
Regex regex = new Regex(@"\[(.+?)\]");
var matchGroups = regex.Matches(text);
for (int i = 0; i < matchGroups.Count; i++)
{
Console.WriteLine(matchGroups[i].Groups[1]);
}
Результат:
more or less
Если вам нужно извлечь текст без скобок, вы можете использовать bash awk
echo " [hola mundo] " | awk -F'[][]' '{print $2}'
результат:
hola mundo