Найти уникальные строки в numpy.array
Мне нужно найти уникальные строки в numpy.array,
Например:
>>> a # I have
array([[1, 1, 1, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
>>> new_a # I want to get to
array([[1, 1, 1, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 0]])
Я знаю, что могу создать набор и цикл по массиву, но я ищу эффективный чистый numpy решение. Я считаю, что есть способ установить тип данных недействительным, и тогда я мог бы просто использовать numpy.unique, но я не мог понять, как заставить это работать.
20 ответов
Начиная с NumPy 1.13, можно просто выбрать ось для выбора уникальных значений в любом массиве N-dim. Чтобы получить уникальные строки, можно сделать:
unique_rows = np.unique(original_array, axis=0)
Еще одно возможное решение
np.vstack({tuple(row) for row in a})
Другой вариант использования структурированных массивов - это использование void тип, который объединяет всю строку в один элемент:
a = np.array([[1, 1, 1, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
b = np.ascontiguousarray(a).view(np.dtype((np.void, a.dtype.itemsize * a.shape[1])))
_, idx = np.unique(b, return_index=True)
unique_a = a[idx]
>>> unique_a
array([[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
РЕДАКТИРОВАТЬ Добавлено np.ascontiguousarray следуя рекомендации @seberg. Это замедлит метод, если массив еще не является смежным.
РЕДАКТИРОВАТЬ Выше можно немного ускорить, возможно за счет ясности, выполнив:
unique_a = np.unique(b).view(a.dtype).reshape(-1, a.shape[1])
Кроме того, по крайней мере, в моей системе производительность выше или ниже, чем у метода lexsort:
a = np.random.randint(2, size=(10000, 6))
%timeit np.unique(a.view(np.dtype((np.void, a.dtype.itemsize*a.shape[1])))).view(a.dtype).reshape(-1, a.shape[1])
100 loops, best of 3: 3.17 ms per loop
%timeit ind = np.lexsort(a.T); a[np.concatenate(([True],np.any(a[ind[1:]]!=a[ind[:-1]],axis=1)))]
100 loops, best of 3: 5.93 ms per loop
a = np.random.randint(2, size=(10000, 100))
%timeit np.unique(a.view(np.dtype((np.void, a.dtype.itemsize*a.shape[1])))).view(a.dtype).reshape(-1, a.shape[1])
10 loops, best of 3: 29.9 ms per loop
%timeit ind = np.lexsort(a.T); a[np.concatenate(([True],np.any(a[ind[1:]]!=a[ind[:-1]],axis=1)))]
10 loops, best of 3: 116 ms per loop
Если вы хотите избежать затрат памяти на преобразование в серию кортежей или другую подобную структуру данных, вы можете использовать структурированные массивы numpy.
Хитрость заключается в том, чтобы просмотреть исходный массив в виде структурированного массива, где каждый элемент соответствует строке исходного массива. Это не делает копию, и довольно эффективно.
В качестве быстрого примера:
import numpy as np
data = np.array([[1, 1, 1, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
ncols = data.shape[1]
dtype = data.dtype.descr * ncols
struct = data.view(dtype)
uniq = np.unique(struct)
uniq = uniq.view(data.dtype).reshape(-1, ncols)
print uniq
Чтобы понять, что происходит, взгляните на промежуточные результаты.
Как только мы рассматриваем вещи как структурированный массив, каждый элемент в массиве является строкой в вашем исходном массиве. (По сути, это структура данных, аналогичная списку кортежей.)
In [71]: struct
Out[71]:
array([[(1, 1, 1, 0, 0, 0)],
[(0, 1, 1, 1, 0, 0)],
[(0, 1, 1, 1, 0, 0)],
[(1, 1, 1, 0, 0, 0)],
[(1, 1, 1, 1, 1, 0)]],
dtype=[('f0', '<i8'), ('f1', '<i8'), ('f2', '<i8'), ('f3', '<i8'), ('f4', '<i8'), ('f5', '<i8')])
In [72]: struct[0]
Out[72]:
array([(1, 1, 1, 0, 0, 0)],
dtype=[('f0', '<i8'), ('f1', '<i8'), ('f2', '<i8'), ('f3', '<i8'), ('f4', '<i8'), ('f5', '<i8')])
Как только мы бежим numpy.uniqueмы вернем структурированный массив:
In [73]: np.unique(struct)
Out[73]:
array([(0, 1, 1, 1, 0, 0), (1, 1, 1, 0, 0, 0), (1, 1, 1, 1, 1, 0)],
dtype=[('f0', '<i8'), ('f1', '<i8'), ('f2', '<i8'), ('f3', '<i8'), ('f4', '<i8'), ('f5', '<i8')])
То, что мы затем должны рассматривать как "нормальный" массив (_ сохраняет результат последнего расчета в ipythonвот почему вы видите _.view...):
In [74]: _.view(data.dtype)
Out[74]: array([0, 1, 1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0])
А затем преобразовать обратно в 2D-массив (-1 это заполнитель, который говорит NumPy для вычисления правильного количества строк, укажите количество столбцов):
In [75]: _.reshape(-1, ncols)
Out[75]:
array([[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
Очевидно, что если вы хотите быть более кратким, вы можете написать это так:
import numpy as np
def unique_rows(data):
uniq = np.unique(data.view(data.dtype.descr * data.shape[1]))
return uniq.view(data.dtype).reshape(-1, data.shape[1])
data = np.array([[1, 1, 1, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
print unique_rows(data)
Что приводит к:
[[0 1 1 1 0 0]
[1 1 1 0 0 0]
[1 1 1 1 1 0]]
np.unique когда я запускаю его np.random.random(100).reshape(10,10) возвращает все уникальные отдельные элементы, но вы хотите уникальные строки, поэтому сначала вам нужно поместить их в кортежи:
array = #your numpy array of lists
new_array = [tuple(row) for row in array]
uniques = np.unique(new_array)
Это единственный способ, которым я вижу, как вы меняете типы, чтобы делать то, что вы хотите, и я не уверен, что итерация списка для перехода к кортежам подходит для того, чтобы вы "не проходили"
np.unique работает, сортируя плоский массив, а затем проверяет, равен ли каждый элемент предыдущему. Это можно сделать вручную без выравнивания:
ind = np.lexsort(a.T)
a[ind[np.concatenate(([True],np.any(a[ind[1:]]!=a[ind[:-1]],axis=1)))]]
Этот метод не использует кортежи и должен быть намного быстрее и проще, чем другие методы, приведенные здесь.
ПРИМЕЧАНИЕ: предыдущая версия этого не имела ind сразу после [, что означает, что были использованы неправильные индексы. Кроме того, Джо Кингтон подчеркивает, что это делает множество промежуточных копий. Следующий метод делает меньше, делая отсортированную копию и затем используя ее представления:
b = a[np.lexsort(a.T)]
b[np.concatenate(([True], np.any(b[1:] != b[:-1],axis=1)))]
Это быстрее и использует меньше памяти.
Кроме того, если вы хотите найти уникальные строки в ndarray независимо от того, сколько измерений в массиве, будет работать следующее:
b = a[lexsort(a.reshape((a.shape[0],-1)).T)];
b[np.concatenate(([True], np.any(b[1:]!=b[:-1],axis=tuple(range(1,a.ndim)))))]
Осталась бы интересная проблема, если бы вы хотели отсортировать / уникально вдоль произвольной оси массива произвольной размерности, что было бы более сложным.
Редактировать:
Чтобы продемонстрировать разницу в скорости, я провел несколько тестов в ipython из трех разных методов, описанных в ответах. С вашим точным знаком a нет большой разницы, хотя эта версия немного быстрее:
In [87]: %timeit unique(a.view(dtype)).view('<i8')
10000 loops, best of 3: 48.4 us per loop
In [88]: %timeit ind = np.lexsort(a.T); a[np.concatenate(([True], np.any(a[ind[1:]]!= a[ind[:-1]], axis=1)))]
10000 loops, best of 3: 37.6 us per loop
In [89]: %timeit b = [tuple(row) for row in a]; np.unique(b)
10000 loops, best of 3: 41.6 us per loop
Однако при увеличении a эта версия оказывается намного, намного быстрее:
In [96]: a = np.random.randint(0,2,size=(10000,6))
In [97]: %timeit unique(a.view(dtype)).view('<i8')
10 loops, best of 3: 24.4 ms per loop
In [98]: %timeit b = [tuple(row) for row in a]; np.unique(b)
10 loops, best of 3: 28.2 ms per loop
In [99]: %timeit ind = np.lexsort(a.T); a[np.concatenate(([True],np.any(a[ind[1:]]!= a[ind[:-1]],axis=1)))]
100 loops, best of 3: 3.25 ms per loop
Я сравнил предложенную альтернативу для скорости и обнаружил, что, к удивлению, пустота unique решение даже немного быстрее, чем родной Numpy unique с axis аргумент. Если вы ищете скорость, вы захотите
numpy.unique(
a.view(numpy.dtype((numpy.void, a.dtype.itemsize*a.shape[1])))
).view(a.dtype).reshape(-1, a.shape[1])
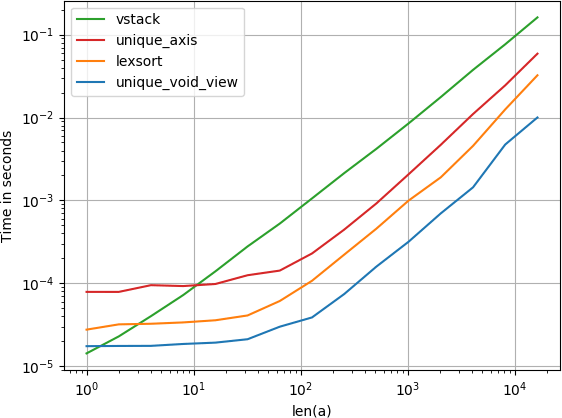
Код для воспроизведения сюжета:
import numpy
import perfplot
def unique_void_view(a):
return numpy.unique(
a.view(numpy.dtype((numpy.void, a.dtype.itemsize*a.shape[1])))
).view(a.dtype).reshape(-1, a.shape[1])
def lexsort(a):
ind = numpy.lexsort(a.T)
return a[ind[
numpy.concatenate((
[True], numpy.any(a[ind[1:]] != a[ind[:-1]], axis=1)
))
]]
def vstack(a):
return numpy.vstack({tuple(row) for row in a})
def unique_axis(a):
return numpy.unique(a, axis=0)
perfplot.show(
setup=lambda n: numpy.random.randint(2, size=(n, 20)),
kernels=[unique_void_view, lexsort, vstack, unique_axis],
n_range=[2**k for k in range(15)],
logx=True,
logy=True,
xlabel='len(a)',
equality_check=None
)
Вот еще один вариант @Greg pythonic ответа
np.vstack(set(map(tuple, a)))
Мне не понравился ни один из этих ответов, потому что ни один из них не обрабатывает массивы с плавающей точкой в линейной алгебре или в смысле векторного пространства, где две строки, "равные", означают "внутри некоторых". В одном ответе, который имеет пороговое значение допуска, /questions/2775350/najti-unikalnyie-stroki-v-numpyarray/2775366#2775366, был выбран порог как поэлементной, так и десятичной точности, который работает в некоторых случаях, но не так математически обобщен, как истинное векторное расстояние.
Вот моя версия:
from scipy.spatial.distance import squareform, pdist
def uniqueRows(arr, thresh=0.0, metric='euclidean'):
"Returns subset of rows that are unique, in terms of Euclidean distance"
distances = squareform(pdist(arr, metric=metric))
idxset = {tuple(np.nonzero(v)[0]) for v in distances <= thresh}
return arr[[x[0] for x in idxset]]
# With this, unique columns are super-easy:
def uniqueColumns(arr, *args, **kwargs):
return uniqueRows(arr.T, *args, **kwargs)
Функция общественного достояния выше использует scipy.spatial.distance.pdist найти евклидово (настраиваемое) расстояние между каждой парой строк. Затем он сравнивает каждое расстояние до thresh старый, чтобы найти строки, которые находятся в пределах thresh друг от друга, и возвращает только одну строку от каждого thresh -cluster.
Как намекнуло, расстояние metric не должен быть евклидовым pdist может вычислять различные расстояния, включая cityblock (Манхэттен-норма) и cosine (угол между векторами).
Если thresh=0 (по умолчанию), то строки должны быть точными, чтобы считаться "уникальными". Другие хорошие значения для thresh использовать масштабированную машинную точность, т. е. thresh=np.spacing(1)*1e3,
Почему бы не использовать drop_duplicates из панд:
>>> timeit pd.DataFrame(image.reshape(-1,3)).drop_duplicates().values
1 loops, best of 3: 3.08 s per loop
>>> timeit np.vstack({tuple(r) for r in image.reshape(-1,3)})
1 loops, best of 3: 51 s per loop
Пакет numpy_indexed (отказ от ответственности: я его автор) оборачивает решение, опубликованное Jaime, в приятный и проверенный интерфейс, а также многие другие функции:
import numpy_indexed as npi
new_a = npi.unique(a) # unique elements over axis=0 (rows) by default
np.unique работает с учетом списка кортежей:
>>> np.unique([(1, 1), (2, 2), (3, 3), (4, 4), (2, 2)])
Out[9]:
array([[1, 1],
[2, 2],
[3, 3],
[4, 4]])
Со списком списков это поднимает TypeError: unhashable type: 'list'
Помимо превосходного ответа @Jaime, еще один способ свернуть строку заключается в использовании a.strides[0] (при условии, a С-смежный), который равен a.dtype.itemsize*a.shape[0], более того void(n) это ярлык для dtype((void,n)), мы наконец приходим к этой самой короткой версии:
a[unique(a.view(void(a.strides[0])),1)[1]]
За
[[0 1 1 1 0 0]
[1 1 1 0 0 0]
[1 1 1 1 1 0]]
Основываясь на ответе на этой странице, я написал функцию, которая копирует возможности MATLAB unique(input,'rows') функция, с дополнительной функцией, чтобы принять допуск для проверки уникальности. Он также возвращает такие индексы, что c = data[ia,:] а также data = c[ic,:], Пожалуйста, сообщите, если вы видите какие-либо расхождения или ошибки.
def unique_rows(data, prec=5):
import numpy as np
d_r = np.fix(data * 10 ** prec) / 10 ** prec + 0.0
b = np.ascontiguousarray(d_r).view(np.dtype((np.void, d_r.dtype.itemsize * d_r.shape[1])))
_, ia = np.unique(b, return_index=True)
_, ic = np.unique(b, return_inverse=True)
return np.unique(b).view(d_r.dtype).reshape(-1, d_r.shape[1]), ia, ic
Ни один из этих ответов не работал для меня. Я предполагаю, что мои уникальные строки содержали строки, а не числа. Однако этот ответ из другого потока работал:
Источник: /questions/43659863/2d-ekvivalent-numpyunique/43659867#43659867
Вы можете использовать методы списка.count() и.index()
coor = np.array([[10, 10], [12, 9], [10, 5], [12, 9]])
coor_tuple = [tuple(x) for x in coor]
unique_coor = sorted(set(coor_tuple), key=lambda x: coor_tuple.index(x))
unique_count = [coor_tuple.count(x) for x in unique_coor]
unique_index = [coor_tuple.index(x) for x in unique_coor]
Для общих целей, таких как трехмерные или более крупные многомерные вложенные массивы, попробуйте следующее:
import numpy as np
def unique_nested_arrays(ar):
origin_shape = ar.shape
origin_dtype = ar.dtype
ar = ar.reshape(origin_shape[0], np.prod(origin_shape[1:]))
ar = np.ascontiguousarray(ar)
unique_ar = np.unique(ar.view([('', origin_dtype)]*np.prod(origin_shape[1:])))
return unique_ar.view(origin_dtype).reshape((unique_ar.shape[0], ) + origin_shape[1:])
который удовлетворяет вашему 2D-набору данных:
a = np.array([[1, 1, 1, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
unique_nested_arrays(a)
дает:
array([[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
Но также и 3D-массивы, такие как:
b = np.array([[[1, 1, 1], [0, 1, 1]],
[[0, 1, 1], [1, 1, 1]],
[[1, 1, 1], [0, 1, 1]],
[[1, 1, 1], [1, 1, 1]]])
unique_nested_arrays(b)
дает:
array([[[0, 1, 1], [1, 1, 1]],
[[1, 1, 1], [0, 1, 1]],
[[1, 1, 1], [1, 1, 1]]])
На самом деле мы можем превратить числовой массив nxy m x n в массив строк nxy m x 1, попробуйте использовать следующую функцию, она предоставляет count, inverse_idx и т. Д., Как numpy.unique:
import numpy as np
def uniqueRow(a):
#This function turn m x n numpy array into m x 1 numpy array storing
#string, and so the np.unique can be used
#Input: an m x n numpy array (a)
#Output unique m' x n numpy array (unique), inverse_indx, and counts
s = np.chararray((a.shape[0],1))
s[:] = '-'
b = (a).astype(np.str)
s2 = np.expand_dims(b[:,0],axis=1) + s + np.expand_dims(b[:,1],axis=1)
n = a.shape[1] - 2
for i in range(0,n):
s2 = s2 + s + np.expand_dims(b[:,i+2],axis=1)
s3, idx, inv_, c = np.unique(s2,return_index = True, return_inverse = True, return_counts = True)
return a[idx], inv_, c
Пример:
A = np.array([[ 3.17 9.502 3.291],
[ 9.984 2.773 6.852],
[ 1.172 8.885 4.258],
[ 9.73 7.518 3.227],
[ 8.113 9.563 9.117],
[ 9.984 2.773 6.852],
[ 9.73 7.518 3.227]])
B, inv_, c = uniqueRow(A)
Results:
B:
[[ 1.172 8.885 4.258]
[ 3.17 9.502 3.291]
[ 8.113 9.563 9.117]
[ 9.73 7.518 3.227]
[ 9.984 2.773 6.852]]
inv_:
[3 4 1 0 2 4 0]
c:
[2 1 1 1 2]
Давайте возьмем в качестве списка всю матрицу numy, затем удалим дубликаты из этого списка и, наконец, вернем наш уникальный список обратно в матрицу numpy:
matrix_as_list=data.tolist()
matrix_as_list:
[[1, 1, 1, 0, 0, 0], [0, 1, 1, 1, 0, 0], [0, 1, 1, 1, 0, 0], [1, 1, 1, 0, 0, 0], [1, 1, 1, 1, 1, 0]]
uniq_list=list()
uniq_list.append(matrix_as_list[0])
[uniq_list.append(item) for item in matrix_as_list if item not in uniq_list]
unique_matrix=np.array(uniq_list)
unique_matrix:
array([[1, 1, 1, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 0]])
Самое простое решение - сделать строки одним элементом, сделав их строками. Затем каждый ряд можно сравнить как единое целое по его уникальности, используя numpy. Это решение обобщенно - вам просто нужно изменить форму и транспонировать ваш массив для других комбинаций. Вот решение для предоставленной проблемы.
import numpy as np
original = np.array([[1, 1, 1, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
uniques, index = np.unique([str(i) for i in original], return_index=True)
cleaned = original[index]
print(cleaned)
Дам:
array([[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
Отправить мой Нобелевский приз по почте
import numpy as np
original = np.array([[1, 1, 1, 0, 0, 0],
[0, 1, 1, 1, 0, 0],
[0, 1, 1, 1, 0, 0],
[1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 0]])
# create a view that the subarray as tuple and return unique indeies.
_, unique_index = np.unique(original.view(original.dtype.descr * original.shape[1]),
return_index=True)
# get unique set
print(original[unique_index])