Служба WCF прекращает обработку вызовов на 15 секунд
Я столкнулся со странным поведением в одном из моих сервисов WCF. Этот сервис работал нормально около 1,5 лет, но через несколько недель он показывает какие-то "отключения" (к сожалению, я не могу публиковать изображения, потому что я новичок здесь).
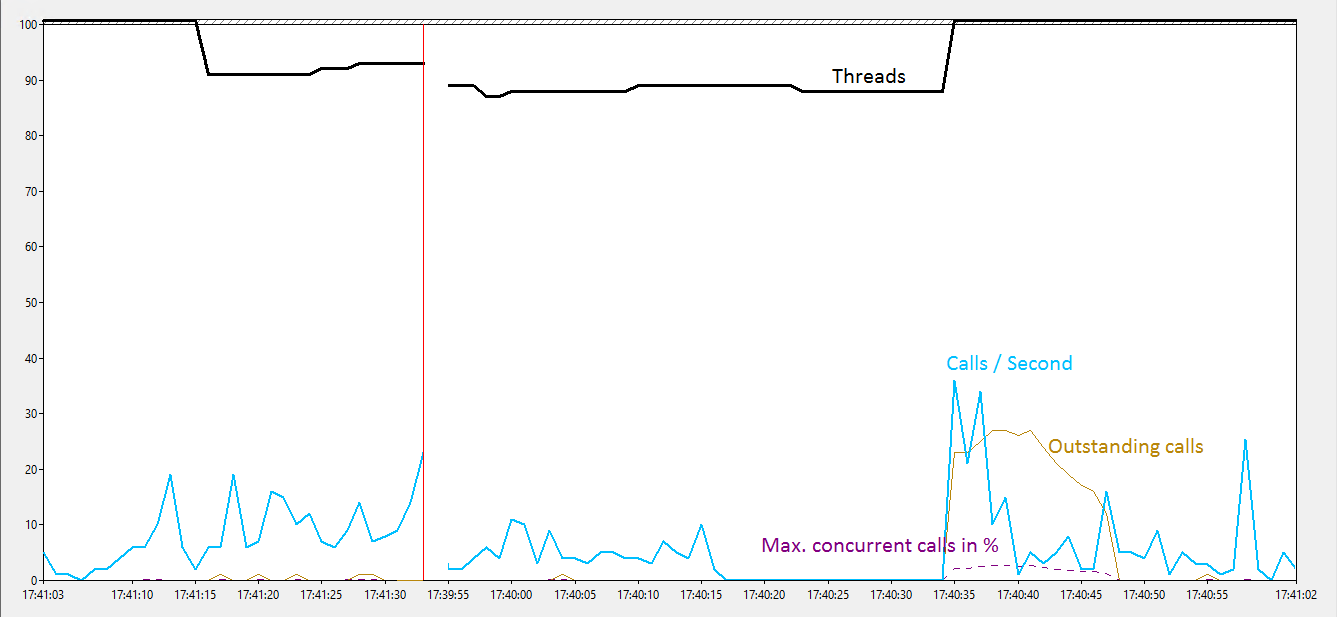
Число вызовов / секунд снижается до 0, хотя все еще поступают входящие вызовы. "Отключение" всегда длится 15 секунд. Через эти 15 секунд вызовы в очереди обрабатываются. Он не может быть связан с сетью, поскольку 90% всех вызовов поступают из другой службы WCF на том же сервере, и никакое другое обслуживание (всего 10) не подвержено этому поведению. Сам сервис продолжает работать, как вычисление внутренних вещей, обновление БД и т. Д. Нет увеличения времени выполнения внутренней работы. Это происходит примерно через 18 - 25 минут, но отключение всегда составляет 15 секунд.
Операционные системы
Windows Server 2012
WCF работает как служба Windows
Конфигурация WCF:
InstanceContextMode = InstanceContextMode.PerCall,
ConcurrencyMode = ConcurrencyMode.Multiple,
UseSynchronizationContext = false,
IncludeExceptionDetailInFaults = true
Binding = WebHttpBinding
Настройки дроссельной заслонки:
MaxConcurrentCalls = 384,
MaxConcurrentInstances = 2784,
MaxConcurrentSessions = 2400
Я уже провел некоторое расследование:
- Настройки газа WCF
Я сделал полный сброс службы в точное время, когда это произошло. Ни ConcurrentCalls, ни ConcurrentSessions не исчерпаны. В дампе не было исключений, которые могли быть причиной проблемы.
- MAX TCP Conenction
Мониторинг активного TCP-соединения далек от своих пределов.
- Магистральный порт в коммутаторе
Поскольку никакие звонки не поступают, даже от локальных служб (использующих localhost), я почти уверен, что это не связано с сетью.
- Проблема с нагрузкой
Это происходит при низкой нагрузке (см. Ниже), а также при высокой нагрузке (в 5 раз больше входящих вызовов). Частота этого не меняется в зависимости от нагрузки. Я также пытался воспроизвести поведение в моей промежуточной системе со скоростью 600-1000 вызовов в секунду. Мне удалось перевести службу в состояние, когда я отправлял больше входящих вызовов в секунду, поскольку служба могла справиться. Количество невыполненных звонков возросло, и в какой-то момент сервис, конечно, упал Но это поведение никогда не обнаруживалось.
- Исчерпание пула потоков
Проблема возникает, когда служба работает с 50 потоками, а также с 200 потоками. Хотя с отсутствующими доступными потоками, об этом появилось бы сообщение об ошибке.
У меня заканчиваются возможные вещи, которые могут вызвать такое поведение. Я думаю, это могут быть блокирующие потоки GC, поскольку служба использует около 10 ГБ в оперативной памяти. Это своего рода сервис кеш-памяти. Или это может быть ОС (Windows Server 2012) или что-то, связанное с самой службой Windows.
Кто-нибудь сталкивался с чем-то подобным самостоятельно или у кого-то есть другая идея, что может вызвать это?
Изменить: Теперь я могу публиковать изображения:
Изменить: GC дамп кучи (спасибо usr)
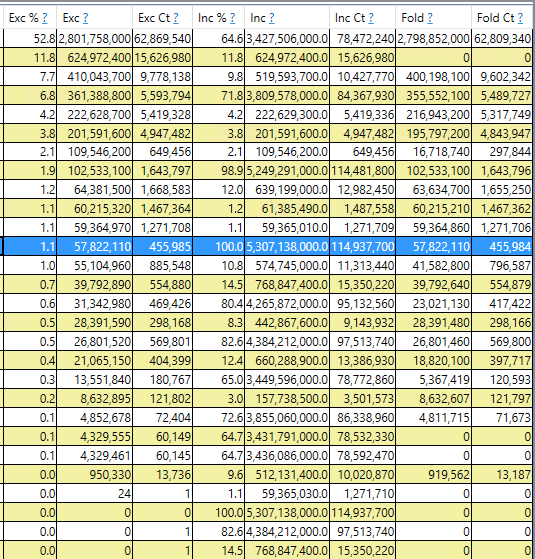
Я вижу, что почти 50% (всего 70%, включая связанные ссылки) вызваны одним большим словарем с ок. 27 миллионов записей (на основе кучи дампа памяти). Я сосредоточусь на этом, чтобы рефакторинг. В нем много неиспользованных предметов. Может быть, это поможет.
Кроме того, я добавлю метод GC.WaitForFullGCApproach из msdn, чтобы посмотреть, работает ли GC, когда служба перестает обрабатывать входящие запросы.
Я буду держать вас в курсе, когда узнаю больше.
Редактировать: GC Stats (включая 14 секунд простоя)
•CLR Startup Flags: CONCURRENT_GC
•Total CPU Time: 42.662 msec
•Total GC CPU Time: 2.748 msec
•Total Allocs : 1.524,637 MB
•MSec/MB Alloc : 1,802 msec/MB
•Total GC Pause: 2.977,2 msec
•% Time paused for Garbage Collection: 19,4%
•% CPU Time spent Garbage Collecting: 6,4%
•Max GC Heap Size: 11.610,333 MB
•Peak Process Working Set: 14.917,915 MB
•Peak Virtual Memory Usage: 15.326,974 MB
Это "всего лишь" 3 секунды паузы. Во всяком случае, это не должно быть так высоко, и я собираюсь реорганизовать хранилище памяти. Но это никак не объясняет 15 секунд:(
Изменить: в выходные дни я сделал следующее:
Установлены последние обновления Windows (последнее обновление было 2 месяца назад)
Перезапустил сервер Windows
Реорганизовал магазин в памяти 27 миллионов предметов. Мне удалось уменьшить используемую память с 11 ГБ до 6-8 ГБ (что довольно много). Очень старый код там;)
Проблема не повторяется до сих пор (около 17 часов работы). Это приводит меня к предположению, что сборщик мусора вызвал паузу службы, или это вызвано некоторой проблемой, связанной с ОС.
Я полагаю, что проблема вообще не "решена" и в какой-то момент снова возникнет, поскольку данные со временем будут увеличиваться.
Спасибо всем, кто уделил этому время. Я буду продолжать исследовать свалки и постараюсь выяснить, что произошло подробно. Я буду держать вас в курсе.
1 ответ
Если отключение достаточно предсказуемо, можете ли вы подключиться к windbg+SOS во время отключения и:
- Приостановить обслуживание дважды во время простоя
- Каждый раз бегать
!threadsа также~*e!dumpstackпоказать состояние потока и стеки
Если у вас 100 потоков ничего не делают в течение 15 секунд, это должно быть отражено в стеках - если повезет, большая часть ваших 100 потоков:
- Застрял в одном из ваших методов (проверьте "текущий кадр" для каждого потока)
- Застрял в методах WCF
- Выполнение
*WaitFor*вызов - Выполнение вызова Sleep/Delay/IO Completion