Mysql быстрее?
У меня есть таблица в базе данных MySQL:
CodeNo Block
a1 a
a2 a
b1 b
b2 b
c1 c
c2 c
Я могу сделать запрос, используя один из двух вариантов:
select codeno from mytab where block='b' and codeno like 'b%'
альтернативно
select codeno from mytab where codeno like 'b%'
Какой из них быстрее в реальном сценарии, когда в mytab есть миллионы записей? Также кто-нибудь может объяснить, как он на самом деле хранится в базе данных?
5 ответов
Не видя плана выполнения, я бы предположил, что первый фильтр уменьшит количество записей, для которых установлен второй фильтр, что ускоряет первый параметр, особенно если оператор like является строкой сравнения, что на самом деле не так эффективно. как числа или двоичное сравнение.
Чтобы узнать больше об этом, вы можете сгенерировать план выполнения обоих операторов и сравнить время выполнения, посмотрите документацию
Первый запрос должен быть быстрее, он ограничивает результат с помощью блочного фильтра.
Я бы сказал: применить индекс на block увеличить скорость.
ALTER TABLE mytab ADD INDEX blockindex (блок);
посмотрите sqlfiddle и сравните планы выполнения: http://sqlfiddle.com/
Я думаю, что оба будут занимать одно и то же время, потому что план выполнения для обоих одинаков
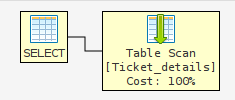
Выберите данные
Сканирование таблицы 100%
а также посмотрите детали плана выполнения
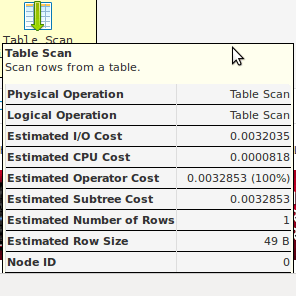
Если у вас нет индексов в таблице, первый запрос займет немного больше времени, потому что ничего не может быть взято из памяти, но вы должны проверить два поля вместо одного.
Но этот вид денормализации действительно очень полезен, когда вы можете добавлять свои собственные индексы. Вы можете добавить только (block) индекс, так что проверка на равенство будет выполняться в памяти, и данные для второго условия будут взяты с диска, но только для тех строк, которые соответствуют первому условию. Это особенно полезно, когда большинство строк, соответствующих первому условию, соответствуют второму.
С другой стороны, вы можете добавить (codeno(1)) индекс, и индекс будет использоваться для проверки префикса, как codeno like 'b%' (не забудьте указать достаточно длинный префикс в индексе), и это займет почти столько же времени. В этом случае условие block='b' не требуется, и даже мешает.
Смотрите @juergend комментарий об объяснении. Проблема "это зависит". Если ни в одном из полей нет индексов, БД выполнит полное сканирование таблицы, поэтому разницы нет. Если в кодене есть индекс, а в блоке его нет, то эти два оператора все равно будут примерно эквивалентны, поскольку в любом случае он будет использовать индекс для кодено. Если индекс по обоим полям тот, с двумя условиями, МОЖЕТ быть быстрее, если БД решит, что более выгодно использовать блочный индекс для первого доступа. Но объяснение должно показать вам, что БД решила использовать для плана доступа.