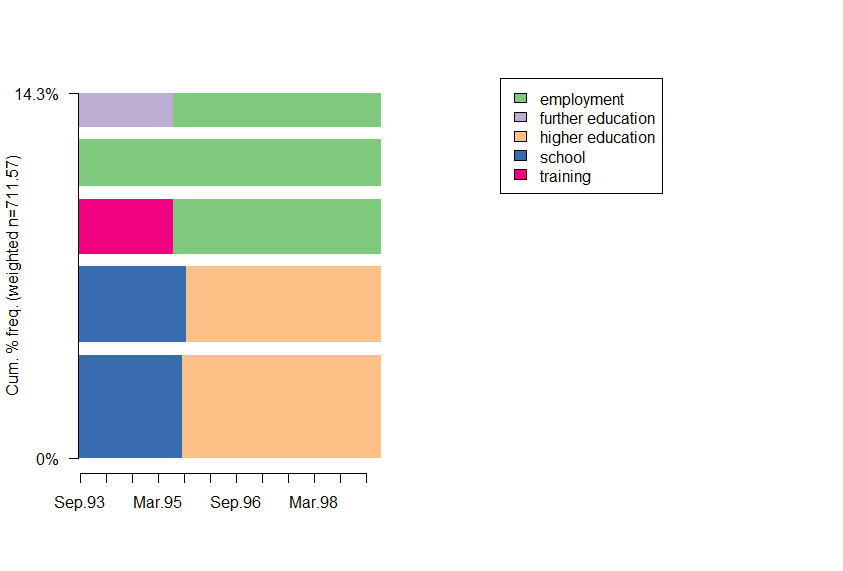TraMineR: построение графиков с метками около 3000 различных состояний
Я использую TraMineR для представления около 40000 последовательностей с около 3000 различных состояний. Сначала я сократил анализ для кластеризации до 3000 последовательностей (выбранных случайным образом). У меня есть последовательность, готовая к сюжету.
У меня проблемы с добавлением легенды на правой стороне любого сюжета. Если это невозможно, учитывая размер алфавита, по крайней мере, мы можем добавить в топ-10 наиболее часто встречающихся последовательностей сюжетное подмножество этих 10 последовательностей. Это то, что я имел в виду.
Когда я использую seqfplot для построения 10 самых частых последовательностей, есть ли способ ограничить легенду этими 10 самыми частыми последовательностями, чтобы читатели могли идентифицировать эти последовательности? Благодарю.
1 ответ
Одним из решений будет подавление легенды путем установки with.legend = FALSE в seqfplot позвоните, а затем сделать свою собственную легенду с основными legend функция.
Кроме того, вы можете воссоздать объект последовательности состояний из результатов seqtab функция, которая возвращает наиболее часто встречающиеся последовательности и затем строит этот новый объект. Единственная сложность здесь - сохранить оригинальные длинные ярлыки и цветовую палитру. Я иллюстрирую, используя mvad данные, которые поставляются с TraMineR,
Сначала мы создаем исходный объект последовательности состояний с длинными метками и весами.
library(TraMineR)
data(mvad)
mvad.lab <- c("employment", "further education", "higher education",
"joblessness", "school", "training")
mvad.shortlab <- c("EM", "FE", "HE", "JL", "SC", "TR")
mvad.seq <- seqdef(mvad[, 17:86], states = mvad.shortlab,
labels = mvad.lab, weights = mvad$weight, xtstep = 6)
Бег
seqfplot(mvad.seq, idxs=1:5)
Вы можете видеть, что пять самых частых последовательностей включают только 5 из 6 состояний (JL не встречается среди этих последовательностей).
Теперь мы строим объект последовательности состояний из 5 наиболее часто встречающихся последовательностей:
sf <- seqtab(mvad.seq, idxs = 1:5)
sff <- seqdef(sf, weights = attr(sf,"weights"))
Чтобы соответствовать длинным меткам и цветам, нам нужно идентифицировать положение сохраненных состояний в исходном векторе алфавита:
sti <- which(alphabet(sf) %in% alphabet(sff))
Это позволяет нам восстановить sff с желаемыми цветами и длинными этикетками.
sff <- seqdef(sf, weights = attr(sf,"weights"),
cpal=cpal(sf)[sti], labels=mvad.lab[sti], xtstep=6)
seqfplot(sff)
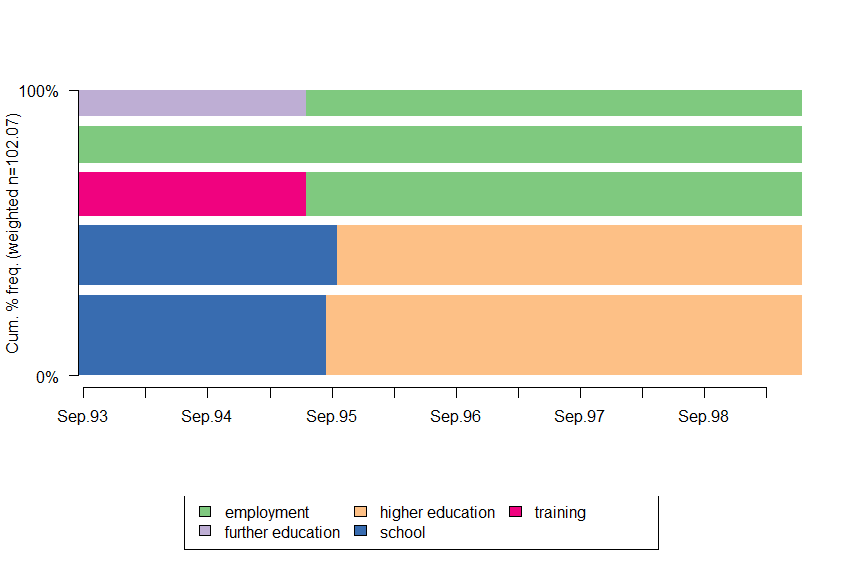
Конечно, отображаемый процент 100 % - это не процент всех последовательностей, а пять последовательностей в sff,
Решение иметь правильный процент будет делать
par(mfrow=c(1,2))
seqfplot(mvad.seq, idxs = 1:5, with.legend=FALSE)
seqlegend(sff)