Встроенная сборка Gcc: что не так с динамически размещенным регистром `r` во входном операнде?
Когда я тестирую встроенную сборку GCC, я использую test функция для отображения символа на экране с помощью эмулятора BOCHS. Этот код работает в 32-битном защищенном режиме. Код выглядит следующим образом:
test() {
char ch = 'B';
__asm__ ("mov $0x10, %%ax\n\t"
"mov %%ax, %%es\n\t"
"movl $0xb8000, %%ebx\n\t"
"mov $0x04, %%ah\n\t"
"mov %0, %%al\n\t"
"mov %%ax, %%es: ((80 * 3 + 40) * 2)(%%ebx)\n\t"
::"r"(ch):);
}
Результат, который я получаю: 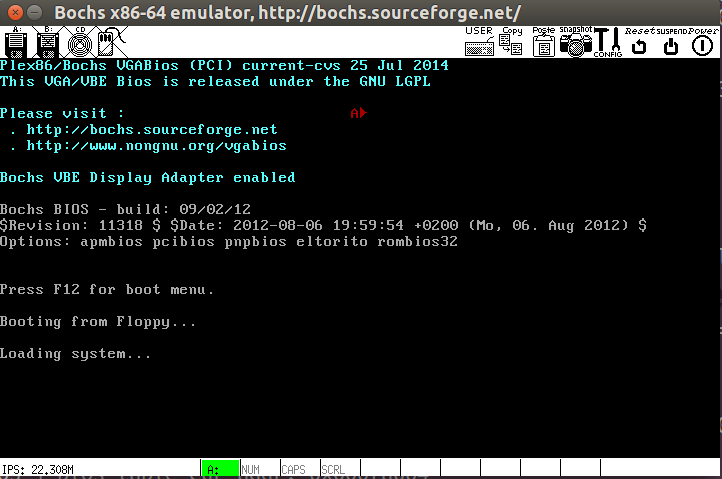
Красный символ на экране не отображается B правильно. Тем не менее, когда я изменил входной регистр r в c как это: ::"c"(ch):);, которая является последней строкой приведенного выше кода, символ "B" отображается нормально:
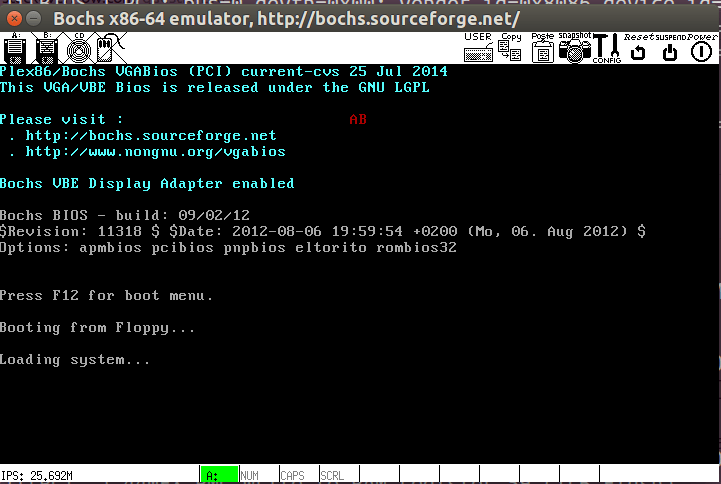 Какая разница? Я получил доступ к видеопамяти через сегмент данных сразу после того, как компьютер перешел в защищенный режим.
Какая разница? Я получил доступ к видеопамяти через сегмент данных сразу после того, как компьютер перешел в защищенный режим.
Я проследил код сборки, я обнаружил, что код был собран в mov al, al когда r регистр выбран и значение ax является 0x0010, так al является 0x10, Результат должен быть таким, но почему он выбрал al регистр. Разве не нужно выбирать регистр, который раньше не использовался? Когда я добавляю clobbers список, я решил проблему.
1 ответ
Как прокомментировал @MichaelPetch, вы можете использовать 32-битные адреса для доступа к любой памяти, которую вы хотите получить из C. Из-за того, что asm gcc выдает, будет занимать ровную область памяти и предполагать, что он может копировать esp в edi и использовать rep stos например, обнуление некоторой стековой памяти (для этого требуется, чтобы %es имеет ту же базу, что и %ss).
Я предполагаю, что лучшее решение - не использовать какой-либо встроенный asm, а вместо этого просто использовать глобальную константу в качестве указателя на char, например
// pointer is constant, but points to non-const memory
uint16_t *const vga_base = (uint16_t*)0xb8000; // + whatever was in your segment
// offsets are scaled by 2. Do some casting if you want the address math to treat offsets as byte offsets
void store_in_flat_memory(unsigned char c, uint32_t offset) {
vga_base[offset] = 0x0400U | c; // it matters that c is unsigned, so it zero-extends instead of sign-extending
}
movzbl 4(%esp), %eax # c, c
movl 8(%esp), %edx # offset, offset
orb $4, %ah #, tmp95 # Super-weird, wtf gcc. We get this even for -mtune=core2, where it causes a partial-register stall
movw %ax, 753664(%edx,%edx) # tmp95, *_3 # the addressing mode scales the offset by two (sizeof(uint16_t)), by using it as base and index
ret
С gcc6.1 на Godbolt (ссылка ниже), с -O3 -m32,
Без const код как vga_base[10] = 0x4 << 8 | 'A'; должен был бы загрузить vga_base глобальный, а затем смещение от него. С const, &vga_base[10] является константой времени компиляции.
Если вы действительно хотите сегмент:
Так как ты не можешь уйти %es модифицированный, вам нужно сохранить / восстановить его. Это еще одна причина, чтобы не использовать его в первую очередь. Если вы действительно хотите специальный сегмент для чего-то, настройте %fs или же %gs один раз и оставьте их установленными, чтобы это не влияло на нормальную работу любых инструкций, которые не используют переопределение сегмента.
Существует встроенный синтаксис для использования %fs или же %gs без встроенного asm, для локальных переменных потока. Вы можете воспользоваться этим, чтобы вообще избежать встроенного ассемблера
Если вы используете пользовательский сегмент, вы можете сделать его базовый адрес ненулевым, поэтому вам не нужно добавлять 0xb8000 сам. Тем не менее, процессоры Intel оптимизированы для плоской памяти, поэтому генерация адресов с использованием ненулевых сегментов происходит на пару циклов медленнее, IIRC.
Я нашел запрос на gcc, чтобы разрешить переопределение сегментов без встроенного asm, и вопрос о добавлении поддержки сегментов в gcc. В настоящее время вы не можете этого сделать.
Делаем это вручную в asm, с выделенным сегментом
Чтобы посмотреть на вывод ASM, я положил его на Godbolt с -mx32 ABI, поэтому аргументы передаются в регистрах, но адреса не нужно расширять до 64 бит. (Я хотел избежать шума загрузки аргументов из стека для -m32 код. -m32 Asm для защищенного режима будет выглядеть аналогично)
void store_in_special_segment(unsigned char c, uint32_t offset) {
char *base = (char*)0xb8000; // sizeof(char) = 1, so address math isn't scaled by anything
// let the compiler do the address math at compile time, instead of forcing one 32bit constant into a register, and another into a disp32
char *dst = base+offset; // not a real address, because it's relative to a special segment. We're using a C pointer so gcc can take advantage of whatever addressing mode it wants.
uint16_t val = (uint32_t)c | 0x0400U; // it matters that c is unsigned, so it zero-extends
asm volatile ("movw %[val], %%fs: %[dest]\n"
:
: [val] "ri" (val), // register or immediate
[dest] "m" (*dst)
: "memory" // we write to something that isn't an output operand
);
}
movzbl %dil, %edi # dil is the low 8 of %edi (AMD64-only, but 32bit code prob. wouldn't put a char there in the first place)
orw $1024, %di #, val # gcc causes an LCP stall, even with -mtune=haswell, and with gcc 6.1
movw %di, %fs: 753664(%esi) # val, *dst_2
void test_const_args(void) {
uint32_t offset = (80 * 3 + 40) * 2;
store_in_special_segment('B', offset);
}
movw $1090, %fs: 754224 #, MEM[(char *)754224B]
void test_const_offset(char ch) {
uint32_t offset = (80 * 3 + 40) * 2;
store_in_special_segment(ch, offset);
}
movzbl %dil, %edi # ch, ch
orw $1024, %di #, val
movw %di, %fs: 754224 # val, MEM[(char *)754224B]
void test_const_char(uint32_t offset) {
store_in_special_segment('B', offset);
}
movw $1090, %fs: 753664(%edi) #, *dst_4
Таким образом, этот код заставляет gcc отлично справляться с использованием режима адресации для вычисления адресов и делать как можно больше во время компиляции.
Сегментный регистр
Если вы хотите изменить регистр сегмента для каждого магазина, имейте в виду, что он медленный: таблицы insn Agner Fog перестают включать mov sr, r после Nehalem, но на Nehalem это инструкция по 6 моп, которая включает 3 мопа загрузки (из GDT, я полагаю). Он имеет пропускную способность один на 13 циклов. Чтение сегментного регистра в порядке (например, push sr или же mov r, sr). pop sr еще немного медленнее.
Я даже не собираюсь писать код для этого, потому что это плохая идея. Убедитесь, что вы используете ограничения clobber, чтобы компилятор знал о каждом регистре, на который вы переходите, иначе у вас возникнут трудные для отладки ошибки, когда окружающий код перестает работать.
См. Вики-тег x86 для встроенной информации asm GNU C.