Извлечь цифры из химической формулы
Извиняюсь, если об этом уже спрашивали и отвечали, но я не мог найти удовлетворительный ответ.
У меня есть список химических формул, в том числе в следующем порядке: C, H, N и O. И я хотел бы вывести число после каждой из этих букв. Проблема в том, что не все формулы содержат N. Однако, все содержат C, H и O. И число может быть однозначным, двойным или (только в случае H) трехзначным.
Таким образом, данные выглядят так:
- C20H37N1O5
- C10H12O3
- C20H19N3O4
- C23H40O3
- C9H13N1O3
- C14H26O4
- C58H100N2O9
Я хотел бы каждый номер элемента для списка в отдельных столбцах. Так что в первом примере это будет:
20 37 1 5
Я пытался:
=IFERROR(MID(LEFT(A2,FIND("H",A2)-1),FIND("C",A2)+1,LEN(A2)),"")
выделить C#. Однако после этого я застреваю, так как H# находится между O или N.
Существует ли формула Excel или VBA, которая может это сделать?
6 ответов
Используйте регулярные выражения
Это хорошая задача для регулярных выражений (регулярных выражений). Поскольку VBA не поддерживает регулярные выражения "из коробки", нам нужно сначала обратиться к библиотеке Windows.
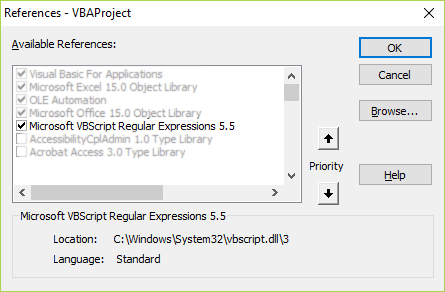
Добавьте ссылку на регулярное выражение в Инструменты, затем Ссылки
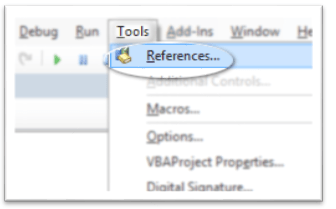
и выбрав Microsoft VBScript Regular Expression 5.5
Добавить эту функцию в модуль
Option Explicit Public Function ChemRegex(ChemFormula As String, Element As String) As Long Dim strPattern As String strPattern = "([CNHO])([0-9]*)" 'this pattern is limited to the elements C, N, H and O only. Dim regEx As New RegExp Dim Matches As MatchCollection, m As Match If strPattern <> "" Then With regEx .Global = True .MultiLine = True .IgnoreCase = False .Pattern = strPattern End With Set Matches = regEx.Execute(ChemFormula) For Each m In Matches If m.SubMatches(0) = Element Then ChemRegex = IIf(Not m.SubMatches(1) = vbNullString, m.SubMatches(1), 1) 'this IIF ensures that in CH4O the C and O are count as 1 Exit For End If Next m End If End FunctionИспользуйте такую функцию в формуле ячейки
Например, в ячейке B2:
=ChemRegex($A2,B$1)и скопировать его в другие ячейки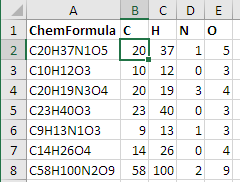
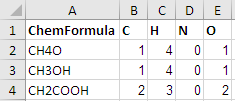
Распознавать также химические формулы с множественными вхождениями таких элементов, как CH3OH или же CH2COOH
Обратите внимание, что код выше не может рассчитывать что-то вроде CH3OH где элементы встречаются более одного раза. Тогда только первый H3 считается последний опущен.
Если вам нужно также распознать формулы в формате, как CH3OH или же CH2COOH (и суммируйте вхождения элементов), затем вам нужно изменить код, чтобы распознавать их тоже...
If m.SubMatches(0) = Element Then
ChemRegex = ChemRegex + IIf(Not m.SubMatches(1) = vbNullString, m.SubMatches(1), 1)
'Exit For needs to be removed.
End If
Распознавать также химические формулы с 2-мя буквенными элементами, такими как NaOH или же CaCl2
В дополнение к изменению выше для нескольких вхождений элементов используйте этот шаблон:
strPattern = "([A-Z][a-z]?)([0-9]*)" 'https://regex101.com/r/nNv8W6/2
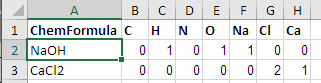
- Обратите внимание, что они должны быть в правильном верхнем / нижнем регистре.
CaCl2работает но неcacl2или жеCACL2, Обратите внимание, что это не доказывает, являются ли эти буквенные комбинации существующими элементами периодической таблицы. Так что это также признает, например.
Xx2Zz5Qв качестве вымышленных элементовXx = 2,Zz = 5а такжеQ = 1,Чтобы принимать только комбинации, которые существуют в периодической таблице, используйте следующий шаблон:
strPattern = "([A][cglmrstu]|[B][aehikr]?|[C][adeflmnorsu]?|[D][bsy]|[E][rsu]|[F][elmr]?|[G][ade]|[H][efgos]?|[I][nr]?|[K][r]?|[L][airuv]|[M][cdgnot]|[N][abdehiop]?|[O][gs]?|[P][abdmortu]?|[R][abefghnu]|[S][bcegimnr]?|[T][abcehilms]|[U]|[V]|[W]|[X][e]|[Y][b]?|[Z][nr])([0-9]*)" 'https://regex101.com/r/Hlzta2/3 'This pattern includes all 118 elements up to today. 'If new elements are found/generated by scientist they need to be added to the pattern.
Это, кажется, работает просто отлично:
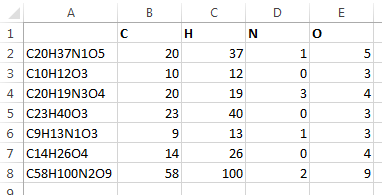
Формула в B2 ниже. Перетащите через и вниз
=IFERROR(IFERROR(--(MID($A2,SEARCH(B$1,$A2)+1,3)),IFERROR(--(MID($A2,SEARCH(B$1,$A2)+1,2)),--MID($A2,SEARCH(B$1,$A2)+1,1))),0)
Или более короткая формула массива, которая должна быть введена с помощью Ctrl+Shift+Enter
=MAX(IFERROR(--MID($A2,SEARCH(B$1,$A2)+1,ROW($A$1:$A$3)),0))
Если вы хотите сохранить простоту VBA, то тоже самое работает:
Public Function ElementCount(str As String, element As String) As Long
Dim i As Integer
Dim s As String
For i = 1 To 3
s = Mid(str, InStr(str, element) + 1, i)
On Error Resume Next
ElementCount = CLng(s)
On Error GoTo 0
Next i
End Function
Используйте это так:
=ElementCount(A1,"C")
Я сделал это в VBA, используя регулярные выражения. Вероятно, вы можете сделать это так, как предлагает Витята, также перебирая строку, но я подозреваю, что это немного быстрее и легче для чтения.
Option Explicit
Function find_associated_number(chemical_formula As Range, element As String) As Variant
Dim regex As Object: Set regex = CreateObject("VBScript.RegExp")
Dim pattern As String
Dim matches As Object
If Len(element) > 1 Or chemical_formula.CountLarge <> 1 Then
find_associated_number = CVErr(xlErrName)
Else
pattern = element + "(\d+)\D"
With regex
.pattern = pattern
.ignorecase = True
If .test(chemical_formula) Then
Set matches = .Execute(chemical_formula)
find_associated_number = matches(0).submatches(0)
Else
find_associated_number = CVErr(xlErrNA)
End If
End With
End If
End Function
Затем вы используете формулу на вашем листе, как обычно:
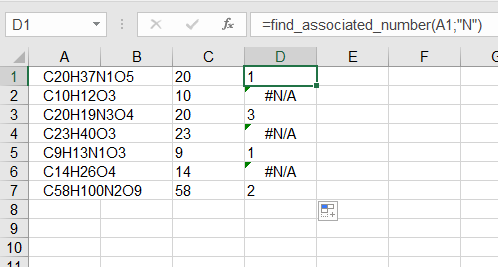
Столбец C содержит количество атомов углерода, столбец D - количество атомов азота. Просто разверните это, скопировав формулу и изменив искомый элемент.
Используйте метод split и тому подобное.
Sub test()
Dim vDB As Variant, vR() As Variant
Dim s As String
Dim vSplit As Variant
Dim i As Long, n As Long, j As Integer
vDB = Range("a2", Range("a" & Rows.Count).End(xlUp))
n = UBound(vDB, 1)
ReDim vR(1 To n, 1 To 4)
For i = 1 To n
s = vDB(i, 1)
For j = 1 To Len(s)
If Mid(s, j, 1) Like "[A-Z]" Then
s = Replace(s, Mid(s, j, 1), " ")
End If
Next j
vSplit = Split(s, " ")
For j = 1 To UBound(vSplit)
vR(i, j) = vSplit(j)
Next j
Next i
Range("b2").Resize(n, 4) = vR
End Sub
Если вы хотите, чтобы решение vba извлекало все числа, я предпочитаю использовать регулярные выражения. Следующий код извлечет все числа из строки
Sub GetMolecularFormulaNumbers()
Dim rng As Range
Dim RegExp As Object
Dim match, matches
Dim j As Long
Set rng = Range(Cells(1, 1), Cells(Cells(Rows.Count, 1).End(xlUp).Row, 1))
Set RegExp = CreateObject("vbscript.regexp")
With RegExp
.Pattern = "\d+"
.IgnoreCase = True
.Global = True
For Each c In rng
j = 0
Set matches = .Execute(c)
If matches.Count > 0 Then
For Each match In matches
j = j + 1
c.Offset(0, j) = CInt(match)
Next match
End If
Next c
End With
End Sub
С VBA это простая задача - вы должны циклически проходить через символы и проверять значения на числовые. В Excel решение включает некоторую избыточность. Но это выполнимо. Например,
C20H37NO5 вернет 20375, если вы примените следующую формулу:
=IF(ISNUMBER(1*MID(A1,1,1)),MID(A1,1,1),"")&
IF(ISNUMBER(1*MID(A1,2,1)),MID(A1,2,1),"")&
IF(ISNUMBER(1*MID(A1,3,1)),MID(A1,3,1),"")&
IF(ISNUMBER(1*MID(A1,4,1)),MID(A1,4,1),"")&
IF(ISNUMBER(1*MID(A1,5,1)),MID(A1,5,1),"")&
IF(ISNUMBER(1*MID(A1,6,1)),MID(A1,6,1),"")&
IF(ISNUMBER(1*MID(A1,7,1)),MID(A1,7,1),"")&
IF(ISNUMBER(1*MID(A1,8,1)),MID(A1,8,1),"")&
IF(ISNUMBER(1*MID(A1,9,1)),MID(A1,9,1),"")
В настоящее время он проверяет первые 9 символов на числовые. Если вы хотите включить более 9, просто добавьте несколько строк в формулу.
В формуле есть маленькая хитрость - 1*, Он преобразует текстовый символ в числовой, если это возможно. Таким образом, 5 как текст, умноженный на 1 становится числовым символом.