Как сделать мемкаширование БД в Django с производными данными?
ПРИМЕЧАНИЕ. Это подробный вопрос о том, как лучше всего реализовать и управлять кэшированием базы данных в моем веб-приложении с помощью memcached. Этот вопрос использует Python/Django, чтобы проиллюстрировать модели данных и их использование, но язык на самом деле не так уж актуален. Мне действительно больше интересно узнать, какова лучшая стратегия для поддержания когерентности кэша. Python/Django просто является языком, который я использую для иллюстрации этого вопроса.
ПРАВИЛА МОЕЙ ЗАЯВКИ:
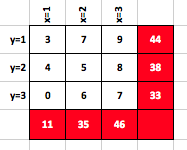
- У меня есть 3 х 3 сетки ячеек целых чисел
- Размер этой сетки может увеличиться или уменьшиться в будущем. Наше решение должно масштабироваться.
- Их совокупный показатель для каждой строки, который рассчитывается путем суммирования
(value * Y-Coord)для каждой клетки в этом ряду. - Их совокупный показатель для каждого столбца, который рассчитывается путем суммирования
(value * X-Coord)для каждой ячейки в этом столбце. - Значения в ячейках меняются нечасто. Но эти значения и оценки часто читаются.
- Я хочу использовать
memcachedчтобы минимизировать доступ к моей базе данных. - Я хочу минимизировать / исключить хранение дубликатов или производной информации в моей базе данных
На изображении ниже показан пример состояния моей сетки.
МОЙ КОД:
import memcache
mc = memcache.Client(['127.0.0.1:11211'], debug=0)
class Cell(models.Model):
x = models.IntegerField(editable=False)
y = models.IntegerField(editable=False)
# Whenever this value is updated, the keys for the row and column need to be
# invalidated. But not sure exactly how I should manage that.
value = models.IntegerField()
class Row(models.Model):
y = models.IntegerField()
@property
def cummulative_score(self):
# I need to do some memcaching here.
# But not sure the smartest way to do it.
return sum(map(lambda p: p.x * p.value, Cell.objects.filter(y=self.y)))
class Column(models.Model):
x = models.IntegerField()
@property
def cummulative_score(self):
# I need to do some memcaching here.
# But not sure the smartest way to do it.
return sum(map(lambda p: p.y * p.value, Cell.objects.filter(x=self.x)))
ВОТ МОЙ ВОПРОС:
Вы можете видеть, что я настроил memcached пример. Конечно, я знаю, как вставить / удалить / обновить ключи и значения в memcached, Но учитывая мой код выше, как я должен правильно называть ключи? Это не будет работать, если имена ключей фиксированы, так как должны существовать отдельные ключи для каждой строки и столбца. И критически важно, как я могу гарантировать, что соответствующие ключи (и только соответствующие ключи) становятся недействительными при обновлении значений в ячейках?
Как мне управлять аннулированием кэша всякий раз, когда кто-либо обновляет Cell.values, чтобы доступ к базе данных был минимизирован? Есть ли какое-то промежуточное программное обеспечение Django, которое может справиться с этой бухгалтерией для меня? Документы, которые я видел, этого не делают.
3 ответа
# your client, be it memcache or redis, assign to client variable
# I think both of them use set without TTL for permanent values.
class Cell(models.Model):
x = models.IntegerField(editable=False)
y = models.IntegerField(editable=False)
value = models.IntegerField()
def save(self, *args, **kwargs):
Cell.cache("row",self.y)
Cell.cache("column",self.x)
super(Cell, self).save(*args, **kwargs)
@staticmethod
def score(dimension, number):
return client.get(dimension+str(number), False) or Cell.cache(number)
@staticmethod
def cache(dimension, number):
if dimension == "row":
val = sum([c.y * c.value for c in Cell.objects.filter(y=number)])
client.set(dimension+str(self.y),val)
return val
if dimension == "column":
val = sum([c.x * c.value for c in Cell.objects.filter(x=number)])
client.set(dimension+str(self.x),val)
return val
raise Exception("No such dimension:"+str(dimension))
Если вы хотите кэшировать отдельные комбинации строк / столбцов, вы должны добавить идентификатор объекта к имени ключа.
заданный топор, у переменных:
key = 'x={}_y={}'.format(x, y)
Я хотел бы использовать имя таблицы и просто добавить идентификатор, идентификатор строки может быть просто таблица PK, идентификатор столбца может быть просто имя столбца, как это
key = '{}_{}_{}'.format(table_name, obj.id, column_name)
В любом случае я предлагаю рассмотреть возможность кэширования всего ряда вместо отдельных ячеек
Cell объект может сделать недействительными кэшированные значения для его Row а также Column когда объект модели сохраняется.
(Row а также Column здесь простые объекты, а не модели Django, но, конечно, вы можете изменить это, если по какой-то причине вам необходимо сохранить их в базе данных.)
import memcache
mc = memcache.Client(['127.0.0.1:11211'], debug=0)
class Cell(models.Model):
x = models.IntegerField(editable=False)
y = models.IntegerField(editable=False)
# Whenever this value is updated, the keys for the row and column need to be
# invalidated. But not sure exactly how I should manage that.
value = models.IntegerField()
def invalidate_cache(self):
Row(self.y).invalidate_cache()
Column(self.x).invalidate_cache()
def save(self, *args, **kwargs):
super(Cell, self).save(*args, **kwargs)
self.invalidate_cache()
class Row(object):
def __init__(self, y):
self.y = y
@property
def cache_key(self):
return "row_{}".format(self.y)
@property
def cumulative_score(self):
score = mc.get(self.cache_key)
if not score:
score = sum(map(lambda p: p.x * p.value, Cell.objects.filter(y=self.y)))
mc.set(self.cache_key, score)
return score
def invalidate_cache(self):
mc.delete(self.cache_key)
class Column(object):
def __init__(self, x):
self.x = x
@property
def cache_key(self):
return "column_{}".format(self.x)
@property
def cumulative_score(self):
score = mc.get(self.cache_key)
if not score:
score = sum(map(lambda p: p.y * p.value, Cell.objects.filter(x=self.x)))
mc.set(self.cache_key, score)
return score
def invalidate_cache(self):
mc.delete(self.cache_key)