Что такое `lr_policy` в кафе?
Я просто пытаюсь выяснить, как я могу использовать Caffe. Для этого я просто взглянул на разные .prototxt файлы в папке примеров. Есть один вариант, который я не понимаю:
# The learning rate policy
lr_policy: "inv"
Возможные значения:
"fixed""inv""step""multistep""stepearly""poly"
Может кто-нибудь объяснить, пожалуйста, эти варианты?
2 ответа
Если вы посмотрите внутрь /caffe-master/src/caffe/proto/caffe.proto файл (вы можете найти его здесь), вы увидите следующие описания:
// The learning rate decay policy. The currently implemented learning rate
// policies are as follows:
// - fixed: always return base_lr.
// - step: return base_lr * gamma ^ (floor(iter / step))
// - exp: return base_lr * gamma ^ iter
// - inv: return base_lr * (1 + gamma * iter) ^ (- power)
// - multistep: similar to step but it allows non uniform steps defined by
// stepvalue
// - poly: the effective learning rate follows a polynomial decay, to be
// zero by the max_iter. return base_lr (1 - iter/max_iter) ^ (power)
// - sigmoid: the effective learning rate follows a sigmod decay
// return base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
//
// where base_lr, max_iter, gamma, step, stepvalue and power are defined
// in the solver parameter protocol buffer, and iter is the current iteration.
Обычной практикой является снижение скорости обучения (lr) по мере продвижения процесса оптимизации / обучения. Тем не менее, не ясно, как именно следует уменьшить скорость обучения в зависимости от числа итераций.
Если вы используете DIGITS в качестве интерфейса к Caffe, вы сможете визуально увидеть, как различные варианты влияют на скорость обучения.
фиксированный: скорость обучения сохраняется фиксированной на протяжении всего процесса обучения.
inv: скорость обучения уменьшается как ~ 1/T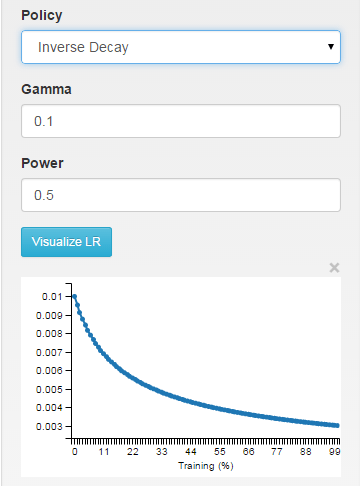
шаг: скорость обучения кусочно-постоянная, отбрасывая каждые X итераций 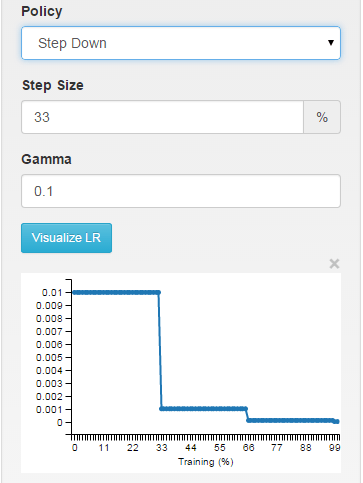
многошаговая: кусочно-постоянная на произвольных интервалах 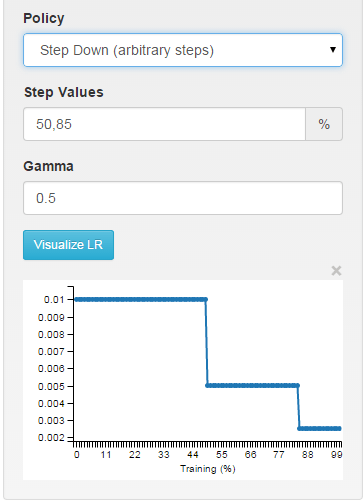
Вы можете точно увидеть, как скорость обучения вычисляется в функции SGDSolver<Dtype>::GetLearningRate (строка solvers/sgd_solver.cpp ~30).
Недавно я натолкнулся на интересный и нетрадиционный подход к настройке скорости обучения: работа Лесли Н. Смита "Больше не надоедливых игр с угадайкой". В своем докладе Лесли предлагает использовать lr_policy это чередуется между уменьшением и увеличением скорости обучения. Его работа также подсказывает, как реализовать эту политику в Кафе.