Ускорение расчета атомарности CUDA для многих лотков / нескольких лотков
Я пытаюсь оптимизировать свои вычисления гистограммы в CUDA. Это дает мне отличное ускорение по сравнению с соответствующими вычислениями процессора OpenMP. Тем не менее, я подозреваю (в соответствии с интуицией), что большинство пикселей попадают в несколько сегментов. Ради аргумента, предположим, что у нас есть 256 пикселей, попадающие, скажем, в два ведра.
Самый простой способ сделать это, кажется, это
- Загрузите переменные в общую память
- Делайте векторизованные загрузки для неподписанных символов и т.д., если это необходимо.
- Сделайте атомарное добавление в общую память
- Сделай объединенную запись в глобальную.
Что-то вроде этого:
__global__ void shmem_atomics_reducer(int *data, int *count){
uint tid = blockIdx.x*blockDim.x + threadIdx.x;
__shared__ int block_reduced[NUM_THREADS_PER_BLOCK];
block_reduced[threadIdx.x] = 0;
__syncthreads();
atomicAdd(&block_reduced[data[tid]],1);
__syncthreads();
for(int i=threadIdx.x; i<NUM_BINS; i+=NUM_BINS)
atomicAdd(&count[i],block_reduced[i]);
}
Производительность этого ядра падает (естественно), когда мы уменьшаем количество бинов, с примерно 45 ГБ / с на 32 бина до примерно 10 ГБ / с на 1 бин. Конфликты и конфликты банка с общей памятью приводятся в качестве причин. Я не знаю, есть ли какой-нибудь способ удалить любой из них для этого вычисления каким-либо существенным способом.
Я также экспериментировал с другой (красивой) идеей из блога параллельного фрейма, включающей снижение уровня деформации, используя __ballot для получения результатов деформации и затем использование __popc() для снижения уровня деформации.
__global__ void ballot_popc_reducer(int *data, int *count ){
uint tid = blockIdx.x*blockDim.x + threadIdx.x;
uint warp_id = threadIdx.x >> 5;
//need lane_ids since we are going warp level
uint lane_id = threadIdx.x%32;
//for ballot
uint warp_set_bits=0;
//to store warp level sum
__shared__ uint warp_reduced_count[NUM_WARPS_PER_BLOCK];
//shared data
__shared__ uint s_data[NUM_THREADS_PER_BLOCK];
//load shared data - could store to registers
s_data[threadIdx.x] = data[tid];
__syncthreads();
//suspicious loop - I think we need more parallelism
for(int i=0; i<NUM_BINS; i++){
warp_set_bits = __ballot(s_data[threadIdx.x]==i);
if(lane_id==0){
warp_reduced_count[warp_id] = __popc(warp_set_bits);
}
__syncthreads();
//do warp level reduce
//could use shfl, but it does not change the overall picture
if(warp_id==0){
int t = threadIdx.x;
for(int j = NUM_WARPS_PER_BLOCK/2; j>0; j>>=1){
if(t<j) warp_reduced_count[t] += warp_reduced_count[t+j];
__syncthreads();
}
}
__syncthreads();
if(threadIdx.x==0){
atomicAdd(&count[i],warp_reduced_count[0]);
}
}
}
Это дает приличные числа (ну, это спорный - пиковое значение mem bw устройства составляет 133 ГБ / с, кажется, что все зависит от конфигурации запуска) для случая одного бина (35-40 ГБ / с для 1 бина, по сравнению с 10-15 ГБ / с (с использованием атомарного алгоритма), но производительность резко падает, когда мы увеличиваем количество бинов. Когда мы работаем с 32 бинами, производительность падает примерно до 5 ГБ / с. Возможно, причина в том, что один поток проходит по всем бинам, запрашивая распараллеливание цикла NUM_BINS.
Я пробовал несколько способов распараллеливания цикла NUM_BINS, но ни один из них не работает должным образом. Например, можно (очень неуклюже) манипулировать ядром, чтобы создать несколько блоков для каждого бина. Кажется, что это ведет себя так же, возможно, потому что мы снова будем страдать от конкуренции из-за нескольких блоков, пытающихся читать из глобальной памяти. Плюс, программирование неуклюже. Аналогично, распараллеливание в направлении y для бункеров дает аналогично скучные результаты.
Другой идеей, которую я попробовал только для удовольствия, был динамический параллелизм, запускающий ядро для каждого бина. Это было катастрофически медленно, возможно из-за отсутствия реальной вычислительной работы для дочерних ядер и затрат на запуск.
Самый многообещающий подход, кажется, из статьи Николаса Уилта
при использовании этих так называемых приватизированных гистограмм, содержащих бины для каждого потока в разделяемой памяти, которые якобы были бы очень тяжелыми при использовании shmem (и у нас на Максвелле только 48 кБ на SM).
Возможно, кто-то мог бы пролить свет на проблему? Я чувствую, что нужно вместо этого изменить алгоритм, чтобы не использовать гистограммы, использовать что-то менее частое. В противном случае, я полагаю, что мы просто используем версию атомика.
Изменить: контекст для моей проблемы в вычислении функций плотности вероятности, которые будут использоваться для классификации шаблонов. Мы можем вычислить приблизительные гистограммы (точнее, pdfs), используя непараметрические методы, такие как Parzen Windows или оценка плотности ядра. Однако это не решает проблему размерности, поскольку нам необходимо суммировать по всем точкам данных для каждой ячейки, что удорожает, когда количество ячейок становится большим. Смотрите здесь: Parzen
1 ответ
Я сталкивался с подобными проблемами при работе с кластеризацией, но в конце концов, лучшим решением было использование шаблона сканирования для группировки обработки. Поэтому я не думаю, что это сработает для вас. Так как вы попросили некоторый опыт в этом, я поделюсь с вами своим.
Проблемы
В вашем первом коде я предполагаю, что работа с низкой производительностью при уменьшении количества бинов связана с остановкой деформации, так как вы выполняете очень мало обработки для каждой оцененной информации. Когда количество бинов увеличивается, соотношение между обработкой и глобальной загрузкой памяти (информация о данных) для этого ядра также увеличивается. Это очень легко проверить с помощью экспериментов "Эффективность проблемы" в Анализ производительности от Nsight. Вероятно, вы получаете низкую частоту циклов по крайней мере с одним изящным деформацией (Эффективность деформации).
 Поскольку мне не удалось увеличить число изящных деформаций до уровня, близкого к 95%, я отказался от этого подхода, поскольку в некоторых случаях он ухудшается (зависимость от памяти останавливает 90% моих циклов обработки.
Поскольку мне не удалось увеличить число изящных деформаций до уровня, близкого к 95%, я отказался от этого подхода, поскольку в некоторых случаях он ухудшается (зависимость от памяти останавливает 90% моих циклов обработки. 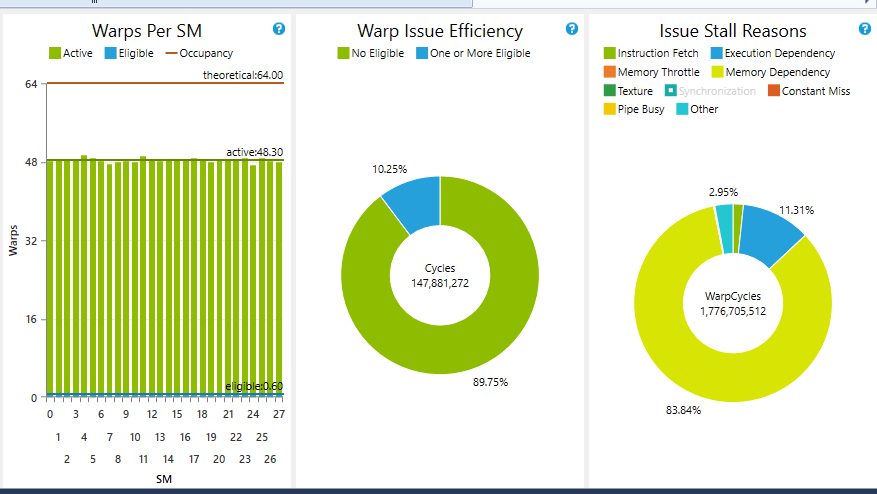
Сокращение числа голосов и перемешивание очень полезно, если количество ячеек невелико. Если оно слишком большое, для каждого фильтра bin должно быть активно небольшое количество потоков. Таким образом, вы можете столкнуться с большим расхождением кода, и это очень нежелательно для параллельной обработки. Вы можете попытаться сгруппировать дивергенцию, чтобы убрать ветвление и получить хороший поток управления, поэтому весь перекос / блок представляет собой аналогичную обработку, но с большими шансами для разных блоков.
Выполнимое решение
Я не знаю где, но есть очень хорошие решения для вашей проблемы, которые я видел. Вы пробовали это?
Также вы можете использовать векторизованную загрузку и попробовать что-то подобное, но я не уверен, насколько это улучшит вашу производительность:
__global__ hist(int4 *data, int *count, int N, int rem, unsigned int init) {
__shared__ unsigned int sBins[N_OF_BINS]; // you may want to declare this one dinamically
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (threadIdx.x < N_OF_BINS) sBins[threadIdx.x] = 0;
for (int i = 0; i < N; i+= warpSize) {
atomicAdd(&sBins[data[i + init].w], 1);
atomicAdd(&sBins[data[i + init].x], 1);
atomicAdd(&sBins[data[i + init].y], 1);
atomicAdd(&sBins[data[i + init].z], 1);
}
//process remaining elements if the data is not multiple of 4
// using recast and a additional control
for (int i = 0; i < rem; i++) {
atomicAdd(&sBins[reinterpret_cast<int*>(data)[N * 4 + init + i]], 1);
}
//update your histogram data here
}