Как я могу профилировать код C++, работающий в Linux?
У меня есть приложение C++, работающее в Linux, которое я сейчас оптимизирую. Как я могу определить, какие области моего кода работают медленно?
20 ответов
Если ваша цель - использовать профилировщик, воспользуйтесь одним из предложенных.
Однако, если вы спешите и можете вручную прервать программу под отладчиком, пока она субъективно медленная, существует простой способ найти проблемы с производительностью.
Просто остановите его несколько раз, и каждый раз смотрите на стек вызовов. Если есть какой-то код, который тратит впустую некоторый процент времени, 20% или 50% или что-то еще, то есть вероятность, что вы поймаете его в действии на каждом образце. Так что это примерно процент образцов, на которых вы это увидите. Там не требуется образованное предположение. Если у вас есть предположение относительно проблемы, это докажет или опровергнет ее.
У вас может быть несколько проблем с производительностью разных размеров. Если вы уберете какой-либо из них, остальные будут занимать больший процент, и его будет легче обнаружить при последующих проходах. Этот эффект увеличения в сочетании с несколькими проблемами может привести к действительно огромным факторам ускорения.
Предостережение: программисты склонны скептически относиться к этой технике, если они сами ее не использовали. Они скажут, что профилировщики предоставляют вам эту информацию, но это верно только в том случае, если они производят выборку всего стека вызовов, а затем позволяют исследовать случайный набор выборок. (Сводные данные - то, где понимание потеряно.) Графики вызовов не дают вам ту же информацию, потому что
- они не суммируют на уровне инструкции, и
- они дают запутанные резюме при наличии рекурсии.
Они также скажут, что он работает только на игрушечных программах, когда на самом деле он работает на любой программе, и, кажется, он работает лучше на больших программах, потому что у них больше проблем. Они скажут, что иногда он находит вещи, которые не являются проблемами, но это правда, если вы видите что-то один раз. Если вы видите проблему более чем на одном образце, это реально.
PS Это также может быть сделано в многопоточных программах, если есть способ собрать образцы стека вызовов пула потоков в определенный момент времени, как это имеет место в Java.
PPS Как грубое обобщение, чем больше уровней абстракции в вашем программном обеспечении, тем больше вероятность того, что вы обнаружите, что это является причиной проблем с производительностью (и возможностью получить ускорение).
Добавлено: Это может быть неочевидно, но техника выборки из стека одинаково хорошо работает при наличии рекурсии. Причина в том, что время, которое будет сэкономлено удалением инструкции, аппроксимируется долей содержащих ее выборок, независимо от того, сколько раз это может произойти в выборке.
Другое возражение, которое я часто слышу, звучит так: " Это остановит что-то случайное и упустит реальную проблему ". Это происходит из-за наличия предварительного представления о том, что является реальной проблемой. Ключевым свойством проблем с производительностью является то, что они не поддаются ожиданиям. Выборка говорит вам, что что-то является проблемой, и ваша первая реакция - неверие. Это естественно, но вы можете быть уверены, что если оно обнаружит проблему, то это реально, и наоборот.
ДОБАВЛЕНО: Позвольте мне сделать байесовское объяснение того, как это работает. Предположим, есть какая-то инструкция I (вызов или иначе), который находится в стеке вызовов некоторой доли f времени (и, следовательно, стоит так дорого). Для простоты предположим, что мы не знаем, что f есть, но предположим, что это либо 0,1, 0,2, 0,3,... 0,9, 1,0, и априорная вероятность каждой из этих возможностей равна 0,1, поэтому все эти затраты одинаково вероятны априори.
Затем предположим, что мы берем только 2 образца стека и видим инструкцию I на обоих образцах назначено наблюдение o=2/2, Это дает нам новые оценки частоты f из I, согласно этому:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&&f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.1 1 1 0.1 0.1 0.25974026
0.1 0.9 0.81 0.081 0.181 0.47012987
0.1 0.8 0.64 0.064 0.245 0.636363636
0.1 0.7 0.49 0.049 0.294 0.763636364
0.1 0.6 0.36 0.036 0.33 0.857142857
0.1 0.5 0.25 0.025 0.355 0.922077922
0.1 0.4 0.16 0.016 0.371 0.963636364
0.1 0.3 0.09 0.009 0.38 0.987012987
0.1 0.2 0.04 0.004 0.384 0.997402597
0.1 0.1 0.01 0.001 0.385 1
P(o=2/2) 0.385
В последнем столбце говорится, что, например, вероятность того, что f >= 0,5 - это 92%, по сравнению с предыдущим предположением 60%.
Предположим, что предыдущие предположения отличаются. Предположим, мы предполагаем, что P(f=0,1) составляет 0,991 (почти наверняка), а все остальные возможности практически невозможны (0,001). Другими словами, наша предварительная уверенность в том, что I дешево. Тогда мы получим:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&& f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.001 1 1 0.001 0.001 0.072727273
0.001 0.9 0.81 0.00081 0.00181 0.131636364
0.001 0.8 0.64 0.00064 0.00245 0.178181818
0.001 0.7 0.49 0.00049 0.00294 0.213818182
0.001 0.6 0.36 0.00036 0.0033 0.24
0.001 0.5 0.25 0.00025 0.00355 0.258181818
0.001 0.4 0.16 0.00016 0.00371 0.269818182
0.001 0.3 0.09 0.00009 0.0038 0.276363636
0.001 0.2 0.04 0.00004 0.00384 0.279272727
0.991 0.1 0.01 0.00991 0.01375 1
P(o=2/2) 0.01375
Теперь он говорит, что P(f >= 0,5) составляет 26%, по сравнению с предыдущим предположением 0,6%. Таким образом, Байес позволяет нам обновить нашу оценку вероятной стоимости I, Если объем данных невелик, он не говорит нам точно, какова стоимость, а лишь то, что он достаточно большой, чтобы его можно было исправить.
Еще один способ взглянуть на это называется Правило наследования. Если вы подбрасываете монету 2 раза, и она выпадает в голову оба раза, что это говорит вам о вероятном весе монеты? Уважаемый способ ответить на этот вопрос - сказать, что это бета-распределение со средним значением (количество попаданий + 1) / (количество попыток + 2) = (2 + 1) / (2 + 2) = 75%.
(Ключ в том, что мы видим I больше чем единожды. Если мы увидим это только один раз, это мало что нам скажет, кроме того, что f > 0.)
Таким образом, даже очень небольшое количество образцов может многое сказать нам о стоимости инструкций, которые он видит. (И он будет видеть их с частотой, в среднем, пропорциональной их стоимости. Если n образцы взяты, и f это стоимость, то I появится на nf+/-sqrt(nf(1-f)) образцы. Пример, n=10, f=0.3, то есть 3+/-1.4 Образцы).
ДОБАВЛЕНО, чтобы дать интуитивное представление о разнице между измерением и выборкой из случайного стека:
Сейчас есть профилировщики, которые производят выборку стека даже по времени настенных часов, но в результате получаются измерения (или "горячая линия", или "горячая точка", от которой "узкое место" может легко скрыться). То, что они вам не показывают (и они легко могут), - это сами образцы. И если ваша цель - найти узкие места, то количество их, которое вам нужно увидеть, в среднем равно 2, деленному на долю времени, которое требуется. Таким образом, если это займет 30% времени, 2/.3 = 6,7 выборки в среднем покажет это, и вероятность того, что 20 выборок покажут это, составляет 99,2%.
Вот неординарная иллюстрация разницы между исследованием измерений и исследованием образцов стеков. Узким местом может быть один такой большой шарик или множество мелких, это не имеет значения.
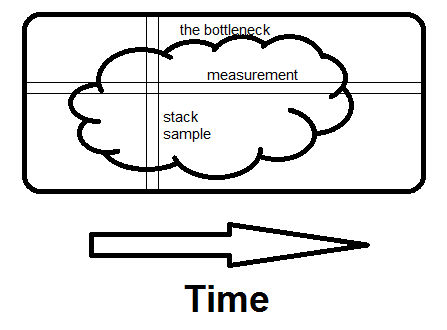
Измерение горизонтальное; он говорит вам, какую часть времени занимают определенные подпрограммы. Выборка вертикальная. Если есть какой-либо способ избежать того, что в данный момент делает вся программа, и если вы видите это во втором примере, вы нашли узкое место. Вот в чем разница - видя всю причину затраченного времени, а не только сколько.
Вы можете использовать Valgrind со следующими опциями
valgrind --tool=callgrind ./(Your binary)
Это сгенерирует файл с именем callgrind.out.x, Вы можете использовать kcachegrind инструмент для чтения этого файла. Это даст вам графический анализ вещей с результатами, например, какие строки стоят сколько.
Я полагаю, вы используете GCC. Стандартным решением будет профилирование с помощью gprof.
Обязательно добавлю -pg для компиляции перед профилированием:
cc -o myprog myprog.c utils.c -g -pg
Я еще не пробовал, но слышал хорошие вещи о google-perftools. Это определенно стоит попробовать.
Связанный вопрос здесь.
Несколько других модных слов, если gprof не делает работу за вас: Valgrind, Intel VTune, Sun DTrace.
Более новые ядра (например, новейшие ядра Ubuntu) поставляются с новыми инструментами 'perf' (apt-get install linux-tools) Ака perf_events.
Они поставляются с классическими профилировщиками сэмплирования ( man-page), а также с отличной временной диаграммой!
Важно то, что эти инструменты могут быть профилированием системы, а не просто профилированием процесса - они могут показывать взаимодействие между потоками, процессами и ядром и позволяют понять зависимости планирования и ввода-вывода между процессами.

Ответ бежать valgrind --tool=callgrind не совсем полный без некоторых вариантов. Обычно мы не хотим профилировать 10 минут медленного запуска под Valgrind и хотим профилировать нашу программу, когда она выполняет какую-то задачу.
Так что это то, что я рекомендую. Сначала запустите программу:
valgrind --tool=callgrind --dump-instr=yes -v --instr-atstart=no ./binary > tmp
Теперь, когда это работает и мы хотим начать профилирование, мы должны запустить в другом окне:
callgrind_control -i on
Это включает профилирование. Чтобы отключить и остановить всю задачу, мы можем использовать:
callgrind_control -k
Теперь у нас есть несколько файлов с именем callgrind.out.* В текущем каталоге. Чтобы увидеть результаты профилирования, используйте:
kcachegrind callgrind.out.*
Я рекомендую в следующем окне нажать на заголовок столбца "Self", иначе он показывает, что "main()" является наиболее трудоемкой задачей. "Self" показывает, сколько каждой функции потребовалось время, а не вместе с зависимыми.
Я бы использовал Valgrind и Callgrind в качестве основы для своего набора инструментов профилирования. Важно знать, что Valgrind - это виртуальная машина:
(Википедия) Valgrind по сути является виртуальной машиной, использующей технологии JIT-компиляции, в том числе динамическую перекомпиляцию. Ничто из оригинальной программы никогда не запускается непосредственно на главном процессоре. Вместо этого Valgrind сначала переводит программу во временную, более простую форму, называемую промежуточным представлением (IR), которая является независимой от процессора формой на основе SSA. После преобразования инструмент (см. Ниже) может свободно выполнять любые преобразования, которые он желает, на IR, прежде чем Valgrind переведет IR обратно в машинный код и позволит хост-процессору запустить его.
Callgrind - это профилировщик, основанный на этом. Основным преимуществом является то, что вам не нужно запускать приложение в течение нескольких часов, чтобы получить надежный результат. Даже одной секунды достаточно для получения надежных и надежных результатов, потому что Callgrind - не зондирующий профилировщик.
Другой инструмент, основанный на Вальгринде, - Массив. Я использую его для профилирования использования кучи памяти. Работает отлично. Что он делает, так это то, что он дает вам снимки использования памяти - детальная информация, ЧТО содержит какой процент памяти, и ВОЗ поместила его туда. Такая информация доступна в разные моменты времени запуска приложения.
Обзор методов профилирования C++
В этом ответе я буду использовать несколько разных инструментов для анализа нескольких очень простых тестовых программ, чтобы конкретно сравнить, как эти инструменты работают.
Следующая тестовая программа очень проста и выполняет следующие функции:
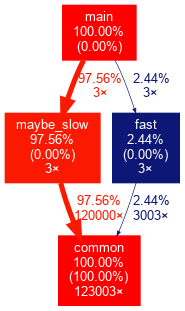
mainзвонкиfastа такжеmaybe_slow3 раза один изmaybe_slowзвонки медленныеМедленный зов
maybe_slowв 10 раз длиннее и доминирует во время выполнения, если мы рассмотрим вызовы дочерней функцииcommon. В идеале инструмент профилирования сможет указать нам на конкретный медленный вызов.обе
fastа такжеmaybe_slowвызовcommon, на долю которого приходится основная часть выполнения программыИнтерфейс программы:
./main.out [n [seed]]и программа делает
O(n^2)петель всего.seedпросто получить другой результат, не влияя на время выполнения.
main.c
#include <inttypes.h>
#include <stdio.h>
#include <stdlib.h>
uint64_t __attribute__ ((noinline)) common(uint64_t n, uint64_t seed) {
for (uint64_t i = 0; i < n; ++i) {
seed = (seed * seed) - (3 * seed) + 1;
}
return seed;
}
uint64_t __attribute__ ((noinline)) fast(uint64_t n, uint64_t seed) {
uint64_t max = (n / 10) + 1;
for (uint64_t i = 0; i < max; ++i) {
seed = common(n, (seed * seed) - (3 * seed) + 1);
}
return seed;
}
uint64_t __attribute__ ((noinline)) maybe_slow(uint64_t n, uint64_t seed, int is_slow) {
uint64_t max = n;
if (is_slow) {
max *= 10;
}
for (uint64_t i = 0; i < max; ++i) {
seed = common(n, (seed * seed) - (3 * seed) + 1);
}
return seed;
}
int main(int argc, char **argv) {
uint64_t n, seed;
if (argc > 1) {
n = strtoll(argv[1], NULL, 0);
} else {
n = 1;
}
if (argc > 2) {
seed = strtoll(argv[2], NULL, 0);
} else {
seed = 0;
}
seed += maybe_slow(n, seed, 0);
seed += fast(n, seed);
seed += maybe_slow(n, seed, 1);
seed += fast(n, seed);
seed += maybe_slow(n, seed, 0);
seed += fast(n, seed);
printf("%" PRIX64 "\n", seed);
return EXIT_SUCCESS;
}
гпроф
gprof требует перекомпиляции программного обеспечения с инструментами, а также использует метод выборки вместе с этим инструментарием. Таким образом, достигается баланс между точностью (выборка не всегда полностью точна и может пропускать функции) и замедлением выполнения (инструментирование и выборка - относительно быстрые методы, которые не сильно замедляют выполнение).
gprof встроен в GCC/binutils, поэтому все, что нам нужно сделать, это скомпилировать с -pgвозможность включить gprof. Затем мы запускаем программу в обычном режиме с параметром CLI размера, который обеспечивает прогон разумной продолжительности в несколько секунд (10000):
gcc -pg -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
time ./main.out 10000
В образовательных целях мы также выполним запуск без включенной оптимизации. Обратите внимание, что на практике это бесполезно, поскольку обычно вы заботитесь только об оптимизации производительности оптимизированной программы:
gcc -pg -ggdb3 -O0 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
./main.out 10000
Первый, time сообщает нам, что время выполнения с и без -pgбыли такие же, и это здорово: торможения нет! Однако я видел отчеты о 2–3-кратном замедлении работы сложного программного обеспечения, например, как показано в этом билете.
Потому что мы скомпилировали -pg, при запуске программы создается файл gmon.out файл, содержащий данные профилирования.
Мы можем наблюдать этот файл графически с помощью gprof2dotкак спросили на: Можно ли получить графическое представление результатов gprof?
sudo apt install graphviz
python3 -m pip install --user gprof2dot
gprof main.out > main.gprof
gprof2dot < main.gprof | dot -Tsvg -o output.svg
Здесь gprof инструмент читает gmon.out отслеживает информацию и создает отчет в удобном для чтения формате. main.gprof, который gprof2dot затем читает, чтобы построить график.
Источник gprof2dot находится по адресу: https://github.com/jrfonseca/gprof2dot.
Для -O0 пробег:
и для -O3 пробег:
В -O0вывод в значительной степени не требует пояснений. Например, это показывает, что 3maybe_slow вызовы и их дочерние вызовы занимают 97,56% от общего времени выполнения, хотя выполнение maybe_slow сама функция без дочерних элементов составляет 0,00% от общего времени выполнения, то есть почти все время, потраченное на эту функцию, было потрачено на дочерние вызовы.
TODO: почему main отсутствует в -O3 вывод, хотя я вижу его на btв GDB? Отсутствует функция в выходных данных GProf, я думаю, это потому, что gprof также основан на выборке в дополнение к его скомпилированным инструментам, и-O3 main просто слишком быстро и нет образцов.
Я выбираю вывод SVG вместо PNG, потому что SVG доступен для поиска с помощью Ctrl + F, а размер файла может быть примерно в 10 раз меньше. Кроме того, ширина и высота сгенерированного изображения могут быть огромными с десятками тысяч пикселей для сложного программного обеспечения, а GNOMEeog3.28.1 в этом случае не работает для PNG, в то время как SVG-файлы открываются моим браузером автоматически. gimp 2.8 работал хорошо, см. также:
- https://askubuntu.com/questions/1112641/how-to-view-extremely-large-images
- https://unix.stackexchange.com/questions/77968/viewing-large-image-on-linux
- https://superuser.com/questions/356038/viewer-for-huge-images-under-linux-100-mp-color-images
но даже в этом случае вы будете часто перетаскивать изображение, чтобы найти то, что хотите, см., например, это изображение из "реального" примера программного обеспечения, взятого из этого билета:
Сможете ли вы легко найти самый важный стек вызовов со всеми этими крошечными несортированными строками спагетти, пересекающими друг друга? Может быть лучшеdotварианты я уверен, но я не хочу туда сейчас. Что нам действительно нужно, так это специальная программа для просмотра, но я ее еще не нашел:
Однако вы можете использовать цветовую карту, чтобы немного смягчить эти проблемы. Например, на предыдущем огромном изображении мне, наконец, удалось найти критический путь слева, когда я сделал блестящий вывод, что зеленый идет после красного, а затем, наконец, темнее и темнее синего.
В качестве альтернативы мы также можем наблюдать текстовый вывод gprof встроенный инструмент binutils, который мы ранее сохранили по адресу:
cat main.gprof
По умолчанию это дает чрезвычайно подробный вывод, объясняющий, что означают выходные данные. Поскольку я не могу объяснить лучше, я позволю вам прочитать это самому.
Как только вы поймете формат вывода данных, вы можете уменьшить многословие, чтобы отображать только данные без учебника с -b вариант:
gprof -b main.out
В нашем примере выходы были для -O0:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
100.35 3.67 3.67 123003 0.00 0.00 common
0.00 3.67 0.00 3 0.00 0.03 fast
0.00 3.67 0.00 3 0.00 1.19 maybe_slow
Call graph
granularity: each sample hit covers 2 byte(s) for 0.27% of 3.67 seconds
index % time self children called name
0.09 0.00 3003/123003 fast [4]
3.58 0.00 120000/123003 maybe_slow [3]
[1] 100.0 3.67 0.00 123003 common [1]
-----------------------------------------------
<spontaneous>
[2] 100.0 0.00 3.67 main [2]
0.00 3.58 3/3 maybe_slow [3]
0.00 0.09 3/3 fast [4]
-----------------------------------------------
0.00 3.58 3/3 main [2]
[3] 97.6 0.00 3.58 3 maybe_slow [3]
3.58 0.00 120000/123003 common [1]
-----------------------------------------------
0.00 0.09 3/3 main [2]
[4] 2.4 0.00 0.09 3 fast [4]
0.09 0.00 3003/123003 common [1]
-----------------------------------------------
Index by function name
[1] common [4] fast [3] maybe_slow
и для -O3:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls us/call us/call name
100.52 1.84 1.84 123003 14.96 14.96 common
Call graph
granularity: each sample hit covers 2 byte(s) for 0.54% of 1.84 seconds
index % time self children called name
0.04 0.00 3003/123003 fast [3]
1.79 0.00 120000/123003 maybe_slow [2]
[1] 100.0 1.84 0.00 123003 common [1]
-----------------------------------------------
<spontaneous>
[2] 97.6 0.00 1.79 maybe_slow [2]
1.79 0.00 120000/123003 common [1]
-----------------------------------------------
<spontaneous>
[3] 2.4 0.00 0.04 fast [3]
0.04 0.00 3003/123003 common [1]
-----------------------------------------------
Index by function name
[1] common
В качестве очень быстрого резюме по каждому разделу, например:
0.00 3.58 3/3 main [2]
[3] 97.6 0.00 3.58 3 maybe_slow [3]
3.58 0.00 120000/123003 common [1]
центрируется вокруг функции с отступом слева (maybe_flow). [3]это идентификатор этой функции. Над функцией находятся ее вызывающие абоненты, а под ней - вызываемые.
За -O3здесь, как и в графическом выводе, maybe_slow а также fast не имеют известного родителя, о чем говорится в документации, <spontaneous> средства.
Я не уверен, есть ли хороший способ выполнить построчное профилирование с помощью gprof: `gprof` время, потраченное на определенные строки кода
valgrind callgrind
valgrind запускает программу через виртуальную машину valgrind. Это делает профилирование очень точным, но при этом сильно замедляет работу программы. Я также уже упоминал kcachegrind ранее: Инструменты для получения графического графа вызовов функций кода
callgrind - это инструмент valgrind для профилирования кода, а kcachegrind - это программа KDE, которая может визуализировать вывод cachegrind.
Сначала нам нужно удалить -pg флаг, чтобы вернуться к нормальной компиляции, иначе запуск действительно не удастся с Profiling timer expired, и да, это настолько распространено, что я сделал, и для этого был вопрос о переполнении стека.
Итак, мы компилируем и запускаем как:
sudo apt install kcachegrind valgrind
gcc -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
time valgrind --tool=callgrind valgrind --dump-instr=yes \
--collect-jumps=yes ./main.out 10000
Я включаю --dump-instr=yes --collect-jumps=yes потому что это также сбрасывает информацию, которая позволяет нам просматривать разбивку производительности по сборочной линии при относительно небольших дополнительных накладных расходах.
С места в карьер, timeсообщает нам, что выполнение программы заняло 29,5 секунд, поэтому в этом примере у нас было замедление примерно в 15 раз. Понятно, что это замедление станет серьезным ограничением для больших рабочих нагрузок. В упомянутом здесь "примере реального программного обеспечения" я заметил замедление в 80 раз.
Запуск генерирует файл данных профиля с именем callgrind.out.<pid> например callgrind.out.8554в моем случае. Мы просматриваем этот файл с помощью:
kcachegrind callgrind.out.8554
который показывает графический интерфейс, содержащий данные, похожие на текстовый вывод gprof:
Кроме того, если мы перейдем на вкладку "График вызовов" в правом нижнем углу, мы увидим график вызовов, который мы можем экспортировать, щелкнув его правой кнопкой мыши, чтобы получить следующее изображение с необоснованным количеством белой границы:-)
я думаю fastне отображается на этом графике, потому что kcachegrind, должно быть, упростил визуализацию, потому что этот вызов занимает слишком мало времени, это, вероятно, будет тем поведением, которое вы хотите в реальной программе. В меню, вызываемом правой кнопкой мыши, есть некоторые настройки для управления отсечкой таких узлов, но я не смог заставить его показать такой короткий вызов после быстрой попытки. Если я нажму наfast в левом окне он показывает график вызовов с fast, так что стек действительно был захвачен. Никто еще не нашел способ показать полный граф вызовов графа: сделать callgrind показывать все вызовы функций в графе вызовов kcachegrind
TODO для сложного программного обеспечения C++, я вижу некоторые записи типа <cycle N>, например <cycle 11>где я бы ожидал имен функций, что это значит? Я заметил, что есть кнопка "Обнаружение цикла", чтобы включать и выключать это, но что это означает?
perf от linux-tools
perfпохоже, использует исключительно механизмы выборки ядра Linux. Это делает его очень простым в настройке, но при этом не полностью точным.
sudo apt install linux-tools
time perf record -g ./main.out 10000
Это добавило 0,2 секунды к выполнению, так что с точки зрения времени все в порядке, но я все еще не вижу особого интереса после расширения common узел со стрелкой вправо на клавиатуре:
Samples: 7K of event 'cycles:uppp', Event count (approx.): 6228527608
Children Self Command Shared Object Symbol
- 99.98% 99.88% main.out main.out [.] common
common
0.11% 0.11% main.out [kernel] [k] 0xffffffff8a6009e7
0.01% 0.01% main.out [kernel] [k] 0xffffffff8a600158
0.01% 0.00% main.out [unknown] [k] 0x0000000000000040
0.01% 0.00% main.out ld-2.27.so [.] _dl_sysdep_start
0.01% 0.00% main.out ld-2.27.so [.] dl_main
0.01% 0.00% main.out ld-2.27.so [.] mprotect
0.01% 0.00% main.out ld-2.27.so [.] _dl_map_object
0.01% 0.00% main.out ld-2.27.so [.] _xstat
0.00% 0.00% main.out ld-2.27.so [.] __GI___tunables_init
0.00% 0.00% main.out [unknown] [.] 0x2f3d4f4944555453
0.00% 0.00% main.out [unknown] [.] 0x00007fff3cfc57ac
0.00% 0.00% main.out ld-2.27.so [.] _start
Итак, я пытаюсь протестировать -O0 программа, чтобы увидеть, показывает ли это что-нибудь, и только теперь, наконец, я вижу график вызовов:
Samples: 15K of event 'cycles:uppp', Event count (approx.): 12438962281
Children Self Command Shared Object Symbol
+ 99.99% 0.00% main.out [unknown] [.] 0x04be258d4c544155
+ 99.99% 0.00% main.out libc-2.27.so [.] __libc_start_main
- 99.99% 0.00% main.out main.out [.] main
- main
- 97.54% maybe_slow
common
- 2.45% fast
common
+ 99.96% 99.85% main.out main.out [.] common
+ 97.54% 0.03% main.out main.out [.] maybe_slow
+ 2.45% 0.00% main.out main.out [.] fast
0.11% 0.11% main.out [kernel] [k] 0xffffffff8a6009e7
0.00% 0.00% main.out [unknown] [k] 0x0000000000000040
0.00% 0.00% main.out ld-2.27.so [.] _dl_sysdep_start
0.00% 0.00% main.out ld-2.27.so [.] dl_main
0.00% 0.00% main.out ld-2.27.so [.] _dl_lookup_symbol_x
0.00% 0.00% main.out [kernel] [k] 0xffffffff8a600158
0.00% 0.00% main.out ld-2.27.so [.] mmap64
0.00% 0.00% main.out ld-2.27.so [.] _dl_map_object
0.00% 0.00% main.out ld-2.27.so [.] __GI___tunables_init
0.00% 0.00% main.out [unknown] [.] 0x552e53555f6e653d
0.00% 0.00% main.out [unknown] [.] 0x00007ffe1cf20fdb
0.00% 0.00% main.out ld-2.27.so [.] _start
TODO: что случилось на -O3казнь? Это простоmaybe_slow а также fastбыли слишком быстрыми и не получили образцов? Хорошо ли работает с-O3на более крупные программы, выполнение которых занимает больше времени? Я пропустил какую-то опцию CLI? Я узнал о-F чтобы контролировать частоту дискретизации в Герцах, но я увеличил ее до максимального значения, разрешенного по умолчанию. -F 39500 (можно увеличить с помощью sudo), и я все еще не вижу четких звонков.
Одна крутая вещь о perf- это инструмент FlameGraph от Брендана Грегга, который очень аккуратно отображает тайминги стека вызовов, что позволяет быстро видеть большие вызовы. Инструмент доступен по адресу: https://github.com/brendangregg/FlameGraph, а также упоминается в его руководстве по perf по адресу: http://www.brendangregg.com/perf.html Когда я запускалperf без sudo я получил ERROR: No stack counts found так что пока я буду делать это с sudo:
git clone https://github.com/brendangregg/FlameGraph
sudo perf record -F 99 -g -o perf_with_stack.data ./main.out 10000
sudo perf script -i perf_with_stack.data | FlameGraph/stackcollapse-perf.pl | FlameGraph/flamegraph.pl > flamegraph.svg
но в такой простой программе вывод не очень легко понять, поскольку мы не можем легко увидеть ни maybe_slow ни fast на этом графике:
На более сложном примере становится ясно, что означает график:
TODO есть журнал [unknown] функции в этом примере, почему?
Еще один удобный графический интерфейс, который может стоить того, включает:
Плагин Eclipse Trace Compass: https://www.eclipse.org/tracecompass/
Но у этого есть обратная сторона: вам нужно сначала преобразовать данные в общий формат трассировки, что можно сделать с помощью
perf data --to-ctf, но его необходимо включить во время сборки / иметьperfдостаточно новый, ни то, ни другое не относится к perf в Ubuntu 18.04https://github.com/KDAB/hotspot
Обратной стороной этого является то, что, похоже, пакета Ubuntu нет, и для его сборки требуется Qt 5.10, а Ubuntu 18.04 - Qt 5.9.
gperftools
Ранее назывался "Инструменты производительности Google", источник: https://github.com/gperftools/gperftools основе примеров.
Сначала установите gperftools с помощью:
sudo apt install google-perftools
Затем мы можем включить профилировщик ЦП gperftools двумя способами: во время выполнения или во время сборки.
Во время выполнения мы должны передать установку LD_PRELOAD указать на libprofiler.so, который вы можете найти с locate libprofiler.so, например, в моей системе:
gcc -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libprofiler.so \
CPUPROFILE=prof.out ./main.out 10000
Как вариант, мы можем встроить библиотеку во время компоновки, не передавая LD_PRELOAD во время выполнения:
gcc -Wl,--no-as-needed,-lprofiler,--as-needed -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
CPUPROFILE=prof.out ./main.out 10000
См. Также: gperftools - файл профиля не выгружается
Самый лучший способ просмотреть эти данные, которые я нашел до сих пор, - это заставить pprof выводить тот же формат, который kcachegrind принимает в качестве входных данных (да, инструмент Valgrind-project-viewer-tool), и использовать kcachegrind для просмотра этого:
google-pprof --callgrind main.out prof.out > callgrind.out
kcachegrind callgrind.out
После запуска любым из этих методов мы получаем prof.outфайл данных профиля в качестве вывода. Мы можем просмотреть этот файл графически как SVG с помощью:
google-pprof --web main.out prof.out
который представляет собой знакомый график вызовов, как и другие инструменты, но с неуклюжей единицей измерения количества выборок, а не секунд.
В качестве альтернативы мы также можем получить некоторые текстовые данные с помощью:
google-pprof --text main.out prof.out
который дает:
Using local file main.out.
Using local file prof.out.
Total: 187 samples
187 100.0% 100.0% 187 100.0% common
0 0.0% 100.0% 187 100.0% __libc_start_main
0 0.0% 100.0% 187 100.0% _start
0 0.0% 100.0% 4 2.1% fast
0 0.0% 100.0% 187 100.0% main
0 0.0% 100.0% 183 97.9% maybe_slow
См. Также: Как использовать инструменты google perf
Протестировано в Ubuntu 18.04, gprof2dot 2019.11.30, valgrind 3.13.0, perf 4.15.18, ядро Linux 4.15.0, FLameGraph 1a0dc6985aad06e76857cf2a354bd5ba0c9ce96b, gperftools 2.5-2.
Это ответ на ответ Назгоба от Gprof.
Я использовал Gprof последние пару дней и уже нашел три существенных ограничения, одно из которых я не видел нигде (пока), документированных:
Он не работает должным образом для многопоточного кода, если вы не используете обходной путь
Граф вызовов запутывается указателями на функции. Пример: у меня есть функция с именем
multithread()что позволяет мне многопоточность указанной функции по указанному массиву (оба передаются в качестве аргументов). Gprof, однако, просматривает все звонки наmultithread()как эквивалент для целей вычисления времени, проведенного у детей. Так как некоторые функции я передаюmultithread()займет больше времени, чем другие, мои графики вызовов в основном бесполезны. (Для тех, кто интересуется, является ли здесь многопоточность: нет,multithread()опционально может и в этом случае выполнять все последовательно только на вызывающем потоке).Здесь говорится, что "... цифры количества вызовов получены путем подсчета, а не выборки. Они абсолютно точны...". Тем не менее, я нахожу свой график вызовов, показывающий мне 5345859132+784984078 как статистику вызовов для моей наиболее вызываемой функции, где первый номер должен быть прямым вызовом, а второй рекурсивный вызов (который все из себя). Поскольку это означало, что у меня была ошибка, я вставил в код длинные (64-битные) счетчики и повторил тот же прогон. По моим подсчетам: 5345859132 прямых и 78094395406 саморекурсивных вызовов. Там много цифр, поэтому я укажу, что измеряемые мной рекурсивные вызовы составляют 78 млрд. Против 784 млн. Из Gprof: коэффициент в 100 разнится. Оба прогона были однопоточными и неоптимизированными, один скомпилированный
-gи другие-pg,
Это был GNU Gprof (GNU Binutils для Debian) 2.18.0.20080103, работающий под 64-битным Debian Lenny, если это кому-нибудь поможет.
Используйте Valgrind, callgrind и kcachegrind:
valgrind --tool=callgrind ./(Your binary)
генерирует callgrind.out.x. Прочитайте это, используя kcachegrind.
Используйте gprof (добавьте -pg):
cc -o myprog myprog.c utils.c -g -pg
(не очень хорошо для многопоточности, указателей на функции)
Используйте google-perftools:
Использует временную выборку, выявляются узкие места ввода-вывода и ЦП.
Intel VTune является лучшим (бесплатно для образовательных целей).
Другие: AMD Codeanalyst (с заменой на AMD CodeXL), OProfile, инструменты 'perf' (apt-get install linux-tools)
Также стоит упомянуть
- HPCToolkit ( http://hpctoolkit.org/) - с открытым исходным кодом, работает для параллельных программ и имеет графический интерфейс для просмотра результатов несколькими способами
- Intel VTune ( https://software.intel.com/en-us/vtune) - если у вас есть компиляторы Intel, это очень хорошо
- TAU ( http://www.cs.uoregon.edu/research/tau/home.php)
Я использовал HPCToolkit и VTune, и они очень эффективны при поиске длинного полюса в палатке и не требуют перекомпиляции вашего кода (за исключением того, что вы должны использовать -g -O или RelWithDebInfo type build в CMake, чтобы получить значимый вывод), Я слышал, что TAU схожи по возможностям.
Для однопоточных программ вы можете использовать igprof, Ignominous Profiler: https://igprof.org/.
Это профилировщик выборки, аналогичный ответу... long... Mike Dunlavey, который будет обернуть результаты в дерево стека вызовов с возможностью просмотра, снабженное комментариями с указанием времени или памяти, потраченных на каждую функцию, кумулятивную или за функции.
На самом деле немного удивлен, что не многие упомянули о https://github.com/google/benchmark, хотя немного громоздко закрепить конкретную область кода, особенно если база кода немного большая, однако я нашел это действительно полезным при использовании в сочетании сcallgrind
ИМХО, определение того, что вызывает узкое место, является ключевым моментом. Однако я сначала попробую ответить на следующие вопросы и выберу инструмент на основе этого
- мой алгоритм правильный?
- Есть ли замки, которые оказались узкими местами?
- есть ли конкретный раздел кода, который оказался виновником?
- как насчет ввода-вывода, обработанного и оптимизированного?
valgrind с комбинацией callrind а также kcachegrind должен предоставить достойную оценку по вышеуказанным пунктам, и как только будет установлено, что есть проблемы с некоторым разделом кода, я бы предложил провести микро-тест google benchmark это хорошее место для начала.
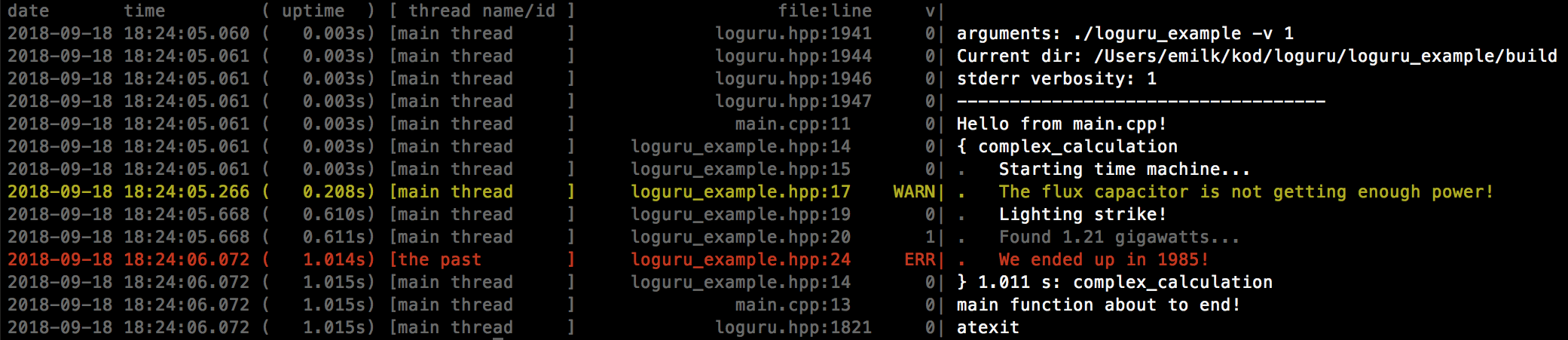
Вы можете использовать каркас журнала, как loguru поскольку он включает метки времени и общее время безотказной работы, которые могут быть использованы для профилирования:
Вы можете использовать библиотеку iprof:
https://gitlab.com/Neurochrom/iprof
https://github.com/Neurochrom/iprof
Он кроссплатформенный и позволяет вам не измерять производительность вашего приложения также в режиме реального времени. Вы можете даже соединить это с живым графиком. Полный отказ от ответственности: я автор.
Вот два метода, которые я использую для ускорения моего кода:
Для приложений, связанных с процессором:
- Используйте профилировщик в режиме отладки для определения сомнительных частей вашего кода
- Затем переключитесь в режим RELEASE и закомментируйте сомнительные разделы вашего кода (заглушите его ничем), пока не увидите изменения в производительности.
Для приложений ввода-вывода:
- Используйте профилировщик в режиме RELEASE для определения сомнительных частей вашего кода.
NB
Если у вас нет профилировщика, используйте профилировщик для бедняка. Хит пауза при отладке вашего приложения. Большинство комплектов разработчика будут разбиты на сборки с закомментированными номерами строк. По статистике вы можете приземлиться в регионе, который потребляет большую часть ваших циклов ЦП.
Для CPU, причина для профилирования в режиме DEBUG заключается в том, что если вы попробовали профилирование в режиме RELEASE, компилятор собирается уменьшить математические, векторизованные циклы и встроенные функции, которые имеют тенденцию превращать ваш код в не отображаемый беспорядок при сборке. Непоправимый беспорядок означает, что ваш профилировщик не сможет четко определить, что занимает так много времени, поскольку сборка может не соответствовать оптимизируемому исходному коду. Если вам нужна производительность (например, чувствительная к времени) в режиме RELEASE, отключите функции отладчика, чтобы сохранить работоспособность.
Для привязки к вводу / выводу профилировщик все еще может идентифицировать операции ввода / вывода в режиме RELEASE, поскольку операции ввода / вывода либо внешне связаны с общей библиотекой (большую часть времени), либо в худшем случае приводят к системной вектор прерывания вызова (который также легко определяется профилировщиком).
На работе у нас есть действительно хороший инструмент, который помогает нам отслеживать то, что мы хотим с точки зрения планирования. Это было полезно много раз.
Он находится на C++ и должен быть настроен в соответствии с вашими потребностями. К сожалению, я не могу поделиться кодом, только понятиями. Вы используете "большой" volatile буфер, содержащий метки времени и идентификатор события, которые вы можете выгрузить после вскрытия или после остановки системы журналирования (и, например, вывести ее в файл).
Вы получаете так называемый большой буфер со всеми данными, а небольшой интерфейс анализирует его и показывает события с именем (вверх / вниз + значение), как осциллограф с цветами (настраивается в .hpp файл).
Вы настраиваете количество генерируемых событий, чтобы сосредоточиться исключительно на том, что вы хотите. Это очень помогло нам в планировании проблем при использовании требуемого количества процессора на основе количества зарегистрированных событий в секунду.
Вам нужно 3 файла:
toolname.hpp // interface
toolname.cpp // code
tool_events_id.hpp // Events ID
Концепция заключается в определении событий в tool_events_id.hpp как это:
// EVENT_NAME ID BEGIN_END BG_COLOR NAME
#define SOCK_PDU_RECV_D 0x0301 //@D00301 BGEEAAAA # TX_PDU_Recv
#define SOCK_PDU_RECV_F 0x0302 //@F00301 BGEEAAAA # TX_PDU_Recv
Вы также определяете несколько функций в toolname.hpp:
#define LOG_LEVEL_ERROR 0
#define LOG_LEVEL_WARN 1
// ...
void init(void);
void probe(id,payload);
// etc
Везде, где в вашем коде вы можете использовать:
toolname<LOG_LEVEL>::log(EVENT_NAME,VALUE);
probe Функция использует несколько сборочных строк для извлечения метки времени часов как можно скорее, а затем устанавливает запись в буфере. У нас также есть атомарный инкремент для безопасного поиска индекса, в котором будет храниться событие журнала. Конечно, буфер является круглым.
Надеюсь, что идея не запутана отсутствием примера кода.
использовать программное обеспечение для отладки, как определить, где код работает медленно?
просто подумайте, что у вас есть препятствие, пока вы в движении, тогда ваша скорость уменьшится
как это нежелательное перераспределение циклов, переполнение буфера, поиск, утечки памяти и т. д. операции потребляют больше мощности выполнения, это отрицательно повлияет на производительность кода. Обязательно добавьте -pg к компиляции перед профилированием:
g++ your_prg.cpp -pg или cc my_program.cpp -g -pg согласно вашему компилятору
еще не пробовал, но слышал хорошие отзывы о google-perftools. Однозначно стоит попробовать.
valgrind --tool=callgrind ./(Your binary)
Будет создан файл с именем gmon.out или callgrind.out.x. Затем вы можете использовать kcachegrind или инструмент отладчика для чтения этого файла. Это даст вам графический анализ вещей с такими результатами, как то, сколько строк стоит.
я думаю так
Поскольку никто не упомянул Arm MAP, я бы добавил его, поскольку лично я успешно использовал Map для профилирования научной программы на C++.
Arm MAP - это профилировщик для параллельных, многопоточных или однопоточных кодов C, C++, Fortran и F90. Он обеспечивает углубленный анализ и определение узких мест в строке источника. В отличие от большинства профилировщиков, он предназначен для профилирования потоков pthread, OpenMP или MPI для параллельного и многопоточного кода.
MAP - коммерческое программное обеспечение.
Использовать -pgфлаг при компиляции и компоновке кода и запуск исполняемого файла. Пока эта программа выполняется, данные профилирования собираются в файле a.out.
Есть два разных типа профилирования
1- Плоское профилирование:
запустив командуgprog --flat-profile a.outу вас есть следующие данные
- какой процент от общего времени был потрачен на функцию,
- сколько секунд было потрачено на функцию, включая и исключая вызовы подфункций,
- количество вызовов,
- среднее время на вызов.
2- график профилирования
командыgprof --graph a.outчтобы получить следующие данные для каждой функции, которая включает:
- В каждом разделе одна функция отмечена порядковым номером.
- Над функцией находится список функций, которые вызывают эту функцию.
- Ниже функции находится список функций, которые она вызывает.
Чтобы получить дополнительную информацию, вы можете посмотреть https://sourceware.org/binutils/docs-2.32/gprof/
Мой опыт работы с инструментами perf в LINUX
1. cachegrind
Слишком медленно!
2. гпроф
Заставляет профилированный процесс зависать в системном вызове fork().
3. Профилировщик процессора Google
Настолько нестабильно, что может быть непригодным для использования, потому что он использует сигналы и вызывает определенную библиотеку libunwind из обработчика сигналов. Исключительно полезный результат, когда он работает. Также вызывает зависание профилированного процесса в системном вызове fork().
4. intel vtune 2019
Постпроцессор часто зависает. Нет ссылки на источник, пригодный для использования. Инструмент непригоден.
5. родной linux perf
Я нашел его непригодным для использования, так как я не мог работать с инструментами постобработки. Например, невозможно отсортировать функции по времени процессора и включению / исключению вызываемых функций (perf-report). Я обнаружил, что невозможно увидеть исходные строки, связанные с процессорным временем (perf-annotate).
6. Заключение
Ваш пробег может отличаться. Особенно, если вы профилируете небольшой исполняемый файл, работающий всего несколько секунд. Также может быть важно иметь права root и инструменты установки / удаления. Может быть важно иметь возможность использовать инструменты, поставляемые с используемой ОС! Если вам нужно использовать определенный набор инструментов, не являющийся родным (компилятор, компоновщик и уже скомпилированные библиотеки), вам может не повезти.