Использовать pytesseract для распознавания текста из изображения
Мне нужно использовать pytesseract для извлечения текста из этой картинки: 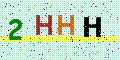
и код:
from PIL import Image, ImageEnhance, ImageFilter
import pytesseract
path = 'pic.gif'
img = Image.open(path)
img = img.convert('RGBA')
pix = img.load()
for y in range(img.size[1]):
for x in range(img.size[0]):
if pix[x, y][0] < 102 or pix[x, y][1] < 102 or pix[x, y][2] < 102:
pix[x, y] = (0, 0, 0, 255)
else:
pix[x, y] = (255, 255, 255, 255)
img.save('temp.jpg')
text = pytesseract.image_to_string(Image.open('temp.jpg'))
# os.remove('temp.jpg')
print(text)
и "temp.jpg" является 
Неплохо, но результат печати ,2 WWНе правильный текст2HHHИтак, как я могу удалить эти черные точки?
7 ответов
Чтобы выполнить распознавание текста на изображении, важно предварительно обработать изображение. Вот простой подход с использованием OpenCV и Pytesseract OCR. Идея состоит в том, чтобы получить обработанное изображение, в котором текст для извлечения будет черным, а фон - белым. Для этого мы можем преобразовать в оттенки серого, применить небольшое размытие по Гауссу, а затем установить порог Оцу для получения двоичного изображения. Отсюда мы можем применять морфологические операции для удаления шума. Наконец, мы инвертируем изображение. Выполняем извлечение текста с помощью--psm 6вариант конфигурации, чтобы принять единый единый блок текста. Посмотрите здесь, чтобы узнать больше.
Вот визуализация каждого шага:
Входное изображение
Преобразовать в оттенки серого -> Размытие по Гауссу -> Порог Оцу
Обратите внимание на крошечные характеристики шума, чтобы удалить их, мы можем выполнить морфологические операции.
Наконец мы инвертируем изображение
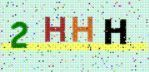
Результат Pytesseract OCR
2HHH
Код
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
# Grayscale, Gaussian blur, Otsu's threshold
image = cv2.imread('1.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (3,3), 0)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
# Morph open to remove noise and invert image
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3,3))
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=1)
invert = 255 - opening
# Perform text extraction
data = pytesseract.image_to_string(invert, lang='eng', config='--psm 6')
print(data)
cv2.imshow('thresh', thresh)
cv2.imshow('opening', opening)
cv2.imshow('invert', invert)
cv2.waitKey()
Вот мое решение:
import pytesseract
from PIL import Image, ImageEnhance, ImageFilter
im = Image.open("temp.jpg") # the second one
im = im.filter(ImageFilter.MedianFilter())
enhancer = ImageEnhance.Contrast(im)
im = enhancer.enhance(2)
im = im.convert('1')
im.save('temp2.jpg')
text = pytesseract.image_to_string(Image.open('temp2.jpg'))
print(text)
У меня есть другой подход к нашему сообществу. Вот мой подход
import pytesseract
from PIL import Image
text = pytesseract.image_to_string(Image.open("temp.jpg"), lang='eng',
config='--psm 10 --oem 3 -c tessedit_char_whitelist=0123456789')
print(text)
Чтобы извлечь текст непосредственно из Интернета, вы можете попробовать следующую реализацию (making use of the first image):
import io
import requests
import pytesseract
from PIL import Image, ImageFilter, ImageEnhance
response = requests.get('https://stackru.com/images/bb55e1326719a1af90083cb6473a9fe857077a78.gif')
img = Image.open(io.BytesIO(response.content))
img = img.convert('L')
img = img.filter(ImageFilter.MedianFilter())
enhancer = ImageEnhance.Contrast(img)
img = enhancer.enhance(2)
img = img.convert('1')
img.save('image.jpg')
imagetext = pytesseract.image_to_string(img)
print(imagetext)
Вот мое небольшое улучшение в устранении шума и произвольной линии в пределах определенного цветового частотного диапазона.
import pytesseract
from PIL import Image, ImageEnhance, ImageFilter
im = Image.open(img) # img is the path of the image
im = im.convert("RGBA")
newimdata = []
datas = im.getdata()
for item in datas:
if item[0] < 112 or item[1] < 112 or item[2] < 112:
newimdata.append(item)
else:
newimdata.append((255, 255, 255))
im.putdata(newimdata)
im = im.filter(ImageFilter.MedianFilter())
enhancer = ImageEnhance.Contrast(im)
im = enhancer.enhance(2)
im = im.convert('1')
im.save('temp2.jpg')
text = pytesseract.image_to_string(Image.open('temp2.jpg'),config='-c tessedit_char_whitelist=0123456789abcdefghijklmnopqrstuvwxyz -psm 6', lang='eng')
print(text)
Вам нужно только увеличить размер картинки cv2.resize
image = cv2.resize(image,(0,0),fx=7,fy=7)
моя картинка 200х40 -> HZUBS
изменил ту же картинку 1400x300 -> A 1234 (так что это правильно)
а потом,
retval, image = cv2.threshold(image,200,255, cv2.THRESH_BINARY)
image = cv2.GaussianBlur(image,(11,11),0)
image = cv2.medianBlur(image,9)
и измените параметры для улучшения результатов
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
from PIL import Image, ImageEnhance, ImageFilter
import pytesseract
path = 'hhh.gif'
img = Image.open(path)
img = img.convert('RGBA')
pix = img.load()
for y in range(img.size[1]):
for x in range(img.size[0]):
if pix[x, y][0] < 102 or pix[x, y][1] < 102 or pix[x, y][2] < 102:
pix[x, y] = (0, 0, 0, 255)
else:
pix[x, y] = (255, 255, 255, 255)
text = pytesseract.image_to_string(Image.open('hhh.gif'))
print(text)