Serverless - производительность DynamoDB (ужасная) по сравнению с RethinkDB + AWS Lambda
В процессе миграции существующего Node.js (Hapi.js) + RethinkDB с VPS OVH (наименьший vps) на Lambda (узел) + DynamoDB AWS я недавно столкнулся с очень большой проблемой производительности.
Использование довольно простое, люди используют онлайн-инструмент, и "материал" сохраняется в БД, проходя через сервер node.js /lambda. Этот "материал" занимает несколько пробелов, около 3 КБ без gzip (сложный объект с множеством ключей и дочерних элементов, поэтому имеет смысл использовать решение NOSQL)
Нет проблем с самим сохранением (на данный момент...), не так много людей используют инструмент, и не нужно много писать одновременно, что имеет смысл использовать Lambda вместо 24/7 работающего VPS.
Реальная проблема в том, когда я хочу загрузить эти результаты.
- Использование Node+RethinkDB занимает около 3 секунд для сканирования всей таблицы и генерации CSV-файла для загрузки.
- Тайм- аут AWS Lambda + DynamoDB через 30 секунд, даже если я разбиваю результаты на страницы для загрузки только 1000 элементов, это все равно занимает 20 секунд (на этот раз нет времени ожидания, просто очень медленное) -> На этой таблице 2200 элементов, и мы можем вывести это нам понадобится около 45 секунд, чтобы загрузить всю таблицу, если время ожидания AWS Lambda не истечет через 30 секунд
Таким образом, операция занимает около 3 с с RethinkDB и теоретически займет 45 с с DynamoDB для того же объема извлеченных данных.
Давайте посмотрим на эти данные сейчас. В таблице 2200 элементов, всего 5 МБ, вот статистика DynamoDB:
Provisioned read capacity units 29 (Auto Scaling Enabled)
Provisioned write capacity units 25 (Auto Scaling Enabled)
Last decrease time October 24, 2018 at 4:34:34 AM UTC+2
UTC: October 24, 2018 at 2:34:34 AM UTC
Local: October 24, 2018 at 4:34:34 AM UTC+2
Region (Ireland): October 24, 2018 at 2:34:34 AM UTC
Last increase time October 24, 2018 at 12:22:07 PM UTC+2
UTC: October 24, 2018 at 10:22:07 AM UTC
Local: October 24, 2018 at 12:22:07 PM UTC+2
Region (Ireland): October 24, 2018 at 10:22:07 AM UTC
Storage size (in bytes) 5.05 MB
Item count 2,195
Предусмотрено 5 единиц емкости для чтения / записи, с максимальным автоматическим масштабированием до 300. Но, похоже, автоматическое масштабирование не масштабируется, как я ожидал, оно возросло с 5 до 29, могло использовать 300, что будет достаточно для загрузки 5 МБ за 30 секунд, но не использую их (я только начинаю с автомасштабированием, так что я думаю, что он неправильно настроен?)
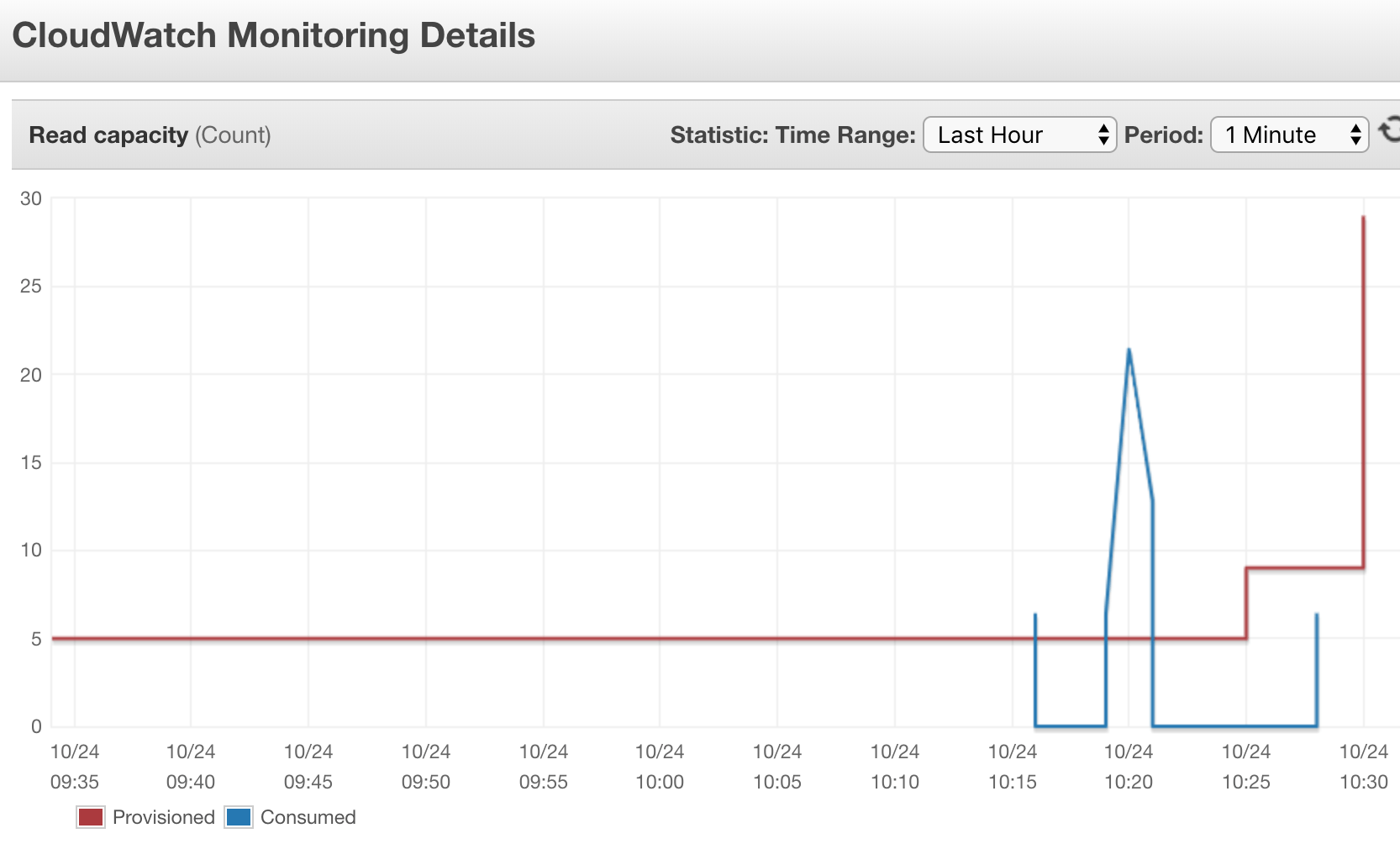
Здесь мы видим эффект автоматического масштабирования, который увеличивает количество единиц емкости чтения, но это происходит слишком поздно, и время ожидания уже произошло. Я пытался загрузить данные несколько раз подряд и не увидел особых улучшений, даже с 29 единицами.
Сама лямбда настроена с 128 МБ ОЗУ, увеличение до 1024 МБ не дает никакого эффекта (как и следовало ожидать, это подтверждает, что проблема связана с продолжительностью сканирования DynamoDB)
Итак, все это заставляет меня задуматься, почему DynamoDB не может сделать за 30 секунд то, что делает RethinkDB за 3 секунды, это не связано с каким-либо видом индексации, поскольку операция является "сканированием", поэтому она должна проходить все элементы в БД в любом порядке.,
Интересно, как я должен получить этот ОГРОМНЫЙ набор данных (5 МБ!) С DynamoDB для создания CSV.
И мне действительно интересно, является ли DynamoDB подходящим инструментом для работы, я действительно не ожидал столь низких показателей по сравнению с тем, что я использовал в прошлом (монго, переосмысление, postgre и т. Д.)
Я предполагаю, что все сводится к правильной конфигурации (и там, вероятно, есть много вещей, которые можно улучшить), но даже в этом случае, почему такая боль загружать кучу данных? 5 МБ это не большое дело, но если вам кажется, что это требует больших усилий и внимания, то это обычная операция для экспорта одной таблицы (статистика, дамп для резервного копирования и т. Д.)
Изменить: так как я создал этот вопрос, я прочитал https://hackernoon.com/the-problems-with-dynamodb-auto-scaling-and-how-it-might-be-improved-a92029c8c10b который подробно объясняет проблему Я встретил. По сути, автоматическое масштабирование запускается медленно, что объясняет, почему оно не масштабируется правильно в моем случае использования. Эту статью необходимо прочитать, если вы хотите понять, как работает автоматическое масштабирование DynamoDB.
2 ответа
Я столкнулся с точно такой же проблемой в моем приложении (т. Е. Автоматическое масштабирование DynamoDB не срабатывает достаточно быстро для работы по требованию высокой интенсивности).
К тому времени, когда я смог справиться с проблемой, я был довольно предан ДинамоБ, поэтому я обошел ее. Вот что я сделал.
Когда я собираюсь начать работу с высокой интенсивностью, я постепенно увеличиваю RCU и WCU на своей таблице DynamoDB. В вашем случае вы, вероятно, могли бы иметь одну лямбду, чтобы увеличить пропускную способность, а затем, чтобы эта лямбда запускала другую, чтобы выполнять работу с высокой интенсивностью. Обратите внимание, что увеличение резервирования может занять несколько секунд, поэтому разделение его на отдельную лямбду, вероятно, является хорошей идеей.
Я буду вставлять свои личные заметки по проблеме, с которой я столкнулся ниже. Извиняюсь, но я не могу потрудиться отформатировать их в разметку stackru.
Мы хотим обеспечить достаточную пропускную способность, чтобы пользователи могли быстро работать и, что еще важнее, не получать никаких неудачных операций. Однако мы хотим обеспечить достаточную пропускную способность для удовлетворения наших потребностей, поскольку это стоит нам денег.
По большей части мы можем использовать автоматическое масштабирование в наших таблицах, что должно адаптировать нашу подготовленную пропускную способность к фактически потребляемому количеству (то есть, больше пользователей = больше пропускной способности, автоматически предоставляемой). Это не в двух ключевых аспектах для нас:
Автоматическое масштабирование увеличивает пропускную способность только через 10 минут после того, как порог обеспечения пропускной способности нарушен. Когда он начинает увеличиваться, он не очень агрессивен в этом. Здесь есть отличный блог на эту тему: https://hackernoon.com/the-problems-with-dynamodb-auto-scaling-and-how-it-might-be-improved-a92029c8c10b. Когда буквально нулевое потребление пропускной способности, DynamoDB не уменьшает пропускную способность. AWS Dynamo не выполняет автоматическое масштабирование обратно. Место, которое нам действительно необходимо для управления пропускной способностью, - это таблицы WCU в таблице счетов. RCU намного дешевле, чем WCU, поэтому считывание менее опасно для предоставления. Для большинства таблиц достаточно нескольких RCU и WCU. Однако, когда мы делаем извлечение из источника, наша емкость записи в таблице счетов-фактур высока в течение 30-минутного периода.
Давайте представим, что мы только что использовали Autoscaling. Когда пользователь запускает извлечение, у нас будет 5 минут непрерывной работы, чего может быть или не быть достаточной пропускной способностью. Автоматическое масштабирование включается примерно через 10 минут (в лучшем случае), но оно делает это тяжело - не масштабируя так быстро, как нам нужно. Наше положение не будет достаточно высоким, мы будем ограничены и не получим требуемые данные. Если бы несколько процессов выполнялись одновременно, эта проблема была бы еще хуже - мы просто не могли обрабатывать несколько экстрактов одновременно.
К счастью, мы знаем, когда собираемся превратить таблицу счетов-фактур, поэтому мы можем программно увеличить пропускную способность таблицы счетов-фактур. Похоже, что увеличение пропускной способности происходит очень быстро. Вероятно, в течение нескольких секунд. При тестировании я заметил, что представление Metrics в DynamoDB довольно бесполезно. Его очень медленно обновлять, и я думаю, что иногда он просто отображал неверную информацию. Вы можете использовать интерфейс командной строки AWS, чтобы описать таблицу, и посмотреть, как обеспечивается пропускная способность в режиме реального времени:
AWS DynamoDb таблицы описания - имя-таблицы DEV_Invoices
Теоретически мы могли бы просто увеличить пропускную способность, когда началось извлечение, а затем снова уменьшить ее, когда мы закончили. Однако, хотя вы можете увеличивать пропускную способность столько раз, сколько захотите, вы можете уменьшать пропускную способность только 4 раза в день, хотя затем вы можете уменьшить пропускную способность один раз в час (т.е. в 27 раз за 24 часа). https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Limits.html. Этот подход не сработает, так как наше уменьшение в резерве вполне может потерпеть неудачу.
Даже если автоматическое масштабирование находится в игре, оно все равно должно соблюдать правила уменьшения выделения ресурсов. Таким образом, если мы уменьшили 4 раза, Autoscaling придется подождать час, прежде чем снова уменьшиться - и это как для чтения, так и для записи значений
Хорошим вариантом является программное увеличение пропускной способности, мы можем сделать это быстро (намного быстрее, чем автоматическое масштабирование), поэтому оно работает для наших нечасто высоких рабочих нагрузок. Мы не можем уменьшить пропускную способность программно после извлечения (см. Выше), но есть несколько других вариантов.
Автоматическое масштабирование для снижения пропускной способности
Обратите внимание, что даже когда установлено автоматическое масштабирование, мы можем программно изменить его на что угодно (например, выше максимального уровня автоматического масштабирования).
Мы можем просто рассчитывать на автоматическое масштабирование, чтобы снизить производительность через час или два после завершения извлечения, это не будет стоить нам слишком дорого.
Есть еще одна проблема. Если после извлечения наша потребляемая мощность падает до нуля, что, вероятно, не приводит к тому, что данные о потреблении не отправляются в CloudWatch, и автоматическое масштабирование ничего не делает для уменьшения выделенной емкости, в результате чего мы застряли на большой емкости.
Есть два варианта, чтобы исправить это. Во-первых, мы можем установить минимальную и максимальную пропускную способность одинаковыми. Так, например, установка минимального и максимального выделенных RCU в Autoscaling на 20 гарантирует, что выделенная емкость вернется к 20, даже если потребляемая емкость равна нулю. Я не уверен, почему, но это работает (я проверял, и это делает), AWS признает обходной путь здесь:
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/AutoScaling.html
Другой вариант - создать лямбда-функцию, которая будет пытаться выполнять (неудачную) операцию чтения и удаления таблицы каждую минуту. Неудачные операции по-прежнему потребляют емкость, поэтому это работает. Это задание обеспечивает регулярную отправку данных в CloudWatch, даже когда наше "реальное" потребление равно нулю, и, следовательно, автоматическое масштабирование будет правильно уменьшать емкость.
Обратите внимание, что данные для чтения и записи отправляются отдельно в CloudWatch. Поэтому, если мы хотим, чтобы WCU уменьшались, когда реальные потребляемые WCU равны нулю, нам нужно использовать операцию записи (то есть удаление). Точно так же нам нужна операция чтения, чтобы убедиться, что RCU обновлены. Обратите внимание, что не удалось выполнить чтение (если элемент не существует) и не удалось удалить (если элемент не существует), но все еще потребляет пропускную способность.
Лямбда для снижения пропускной способности
В предыдущем решении мы использовали лямбда-функцию для непрерывного "опроса" таблицы, создавая таким образом данные CloudWatch, которые позволяют использовать функцию автоматического масштабирования DynamoDB. В качестве альтернативы у нас может быть просто лямбда, которая работает регулярно и при необходимости снижает производительность. Когда вы "описываете" таблицу DynamoDB, вы получаете текущую обеспеченную пропускную способность, а также дату и время последнего увеличения и дату / время последнего уменьшения. Таким образом, лямбда может сказать: если выделенные WCU превышают пороговое значение и в последний раз мы имели увеличение пропускной способности более чем полчаса назад (т.е. мы не находимся в середине извлечения), давайте уменьшим пропускную способность прямо вниз.
Учитывая, что это больше кода, чем опция Autoscaling, я не склонен делать это.
DynamoDB не предназначен для такого использования. Он не похож на традиционную базу данных, которую вы можете запрашивать по своему усмотрению, и особенно не подходит для больших наборов данных, таких как тот, который вы запрашиваете.
Для этого типа сценария я фактически использую потоки DyanamoDB, чтобы создать проекцию в корзину S3, а затем выполнить большой экспорт таким образом. Вероятно, это будет даже быстрее, чем экспорт RethinkDB, на который вы ссылаетесь.
Короче говоря, DynamoDb является лучшим хранилищем ключей транзакций для известных запросов.