Является ли этот результат синтаксического анализатора CYK правильным?
Я пытаюсь изучить алгоритм разбора CYK.
Для этого набора правил грамматики правильны ли получающиеся таблицы для двух данных предложений?
S -> NP VP
VP -> VB NP
NP -> DT NN
PP -> IN NP
NP -> NP PP
NP -> NN
VP -> VP PP
IN -> with
NN -> dog
NN -> cat
VB -> ate
NN -> mouse
DT -> the
['S']
[None, None]
[None, None, 'VP']
['NP', None, None, 'NP']
['DT', 'NN', 'VB', 'DT', 'NN']
['the', 'cat', 'ate', 'the', 'dog']
['S']
['NP', None]
['NP', None, 'VP']
['NP', None, None, 'NP']
[None, None, 'VP', None, None]
[None, None, 'VP', None, None, 'PP']
['NP', None, None, 'NP', None, None, 'NP']
['DT', 'NN', 'VB', 'DT', 'NN', 'IN', 'DT', 'NN']
['the', 'cat', 'ate', 'the', 'dog', 'with', 'the', 'cat']
2 ответа
Вы можете сначала попытаться свести к минимуму свою грамматику, потому что есть некоторые ненужные правила, и, кроме того, именно поэтому not in CNF,
Глядя на это более кратко, у вас None в первом примере вторая строка, второй столбец. Там на самом деле можно иметь S, но так как логика в CYK не может делать дальнейшие оптимизации, такие как NP->NN, Оттуда S -> NP VP для упомянутых None клетка пропадает. Из-за неспособности CYK выполнить это, грамматика должна быть в CNF. Итак, в основном это примерно так, как будто вы пытаетесь применить C-компилятор к программе на C++ (без библиотек C++). И вам повезло даже получить верный результат на вершине.
С учетом вышесказанного я не собираюсь баловаться вторым вашим примером.
Просто чтобы уточнить, грамматика в CNF если у него есть правила только этих двух форм:
S -> AB
A -> a
так явно что-то вроде NP -> NN не в CNF.
Хотя данная грамматика не находится в нормальной форме Хомоски, мы можем легко преобразовать ее в CNF, как показано ниже (например, избавиться от недопустимой продукции
NP -> NNи дополнить грамматику дополнительными правилами):
S -> NP VP
S -> NN VP
VP -> VB NP
VP -> VB NN
NP -> DT NN
PP -> IN NP
PP -> IN NN
NP -> NP PP
NP -> NN PP
VP -> VP PP
IN -> with
NN -> dog
NN -> cat
VB -> ate
NN -> mouse
DT -> the
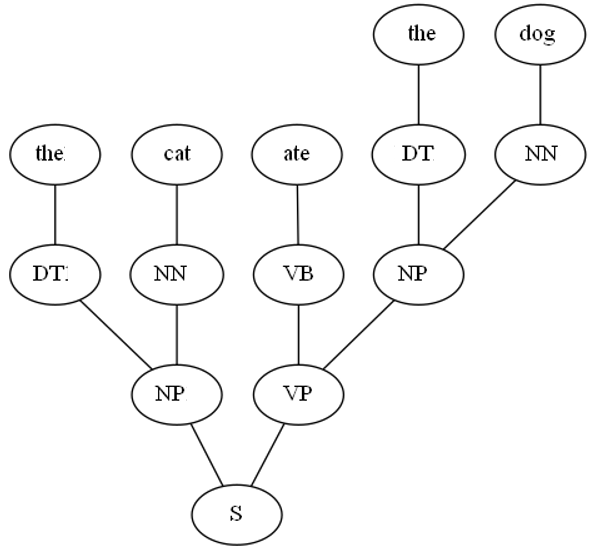
С грамматикой, измененной на приведенную выше, таблица DP с алгоритмом CYK (обратитесь к реализации здесь , хотя она предполагает, что каждый символ в грамматике имеет длину одного символа, но может быть легко расширена) будет похожа на следующую: для первого предложения:

Он будет иметь следующее дерево разбора:
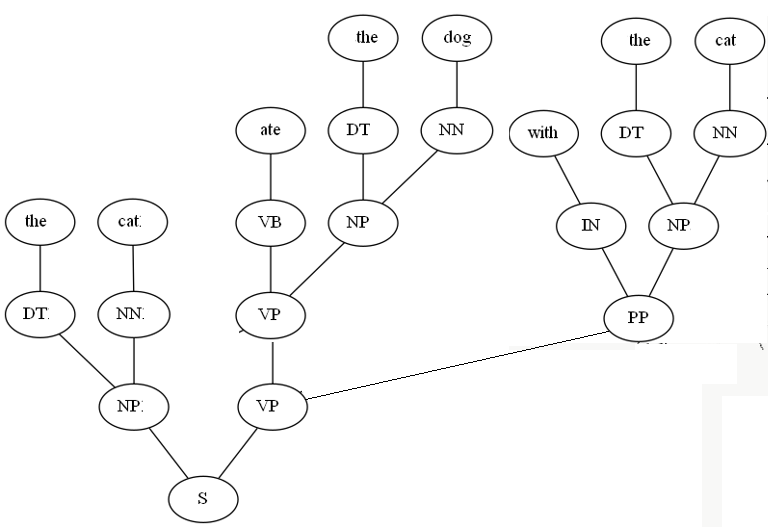
со 2-м предложением следующая анимация показывает сгенерированную таблицу DP,

со следующим деревом разбора: