Много-много оптимизация отношений
Я работаю над системой, в которой у меня есть таблица для хранения компетенций студентов по языкам, для управления которой мы создали следующую архитектуру: 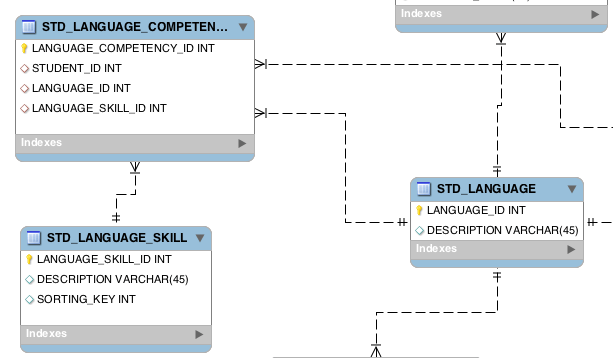
таблица STD_LANGUAGE_COMPETENCIES представляет ассоциативный объект. из многих во многие отношения между таблицей STD_LANGUAGE (французский, английский, арабский...) и STD_LANGUAGE_SKILL (чтение, речь, письмо, обучение) проблема заключается в том, что STD_LANGUAGE и STD_LANGUAGE_SKILL не обновляются обычным пользователем системы (студентом) они добавляются системным администратором, и когда я пытаюсь получить языковые компетенции для учащегося, архитектура обязывает меня выполнить объединение на двух столах, чтобы получить название языка и название навыка. есть ли в любом случае оптимизировать эту схему.
2 ответа
Если языковые навыки, например: "чтение", "написание", "разговор" и т. Д., Без совмещения имен, без ограничения времени для навыков и клиентских модулей управления, вы можете поместить описание непосредственно в таблицу STD_LANGUAGE_COMPETENCE, и удалите ограничения внешнего ключа, в то время как вы сохраняете таблицу навыков для комбинированных элементов для назначения или поиска (по тексту).
Таким образом, вы можете избежать объединения..
Если у вас есть отношения один ко многим или многие ко многим. Вы не можете избежать объединения, чтобы следовать структуре нормализации в SQL.