Что такое дифференциальное исполнение?
Я наткнулся на вопрос переполнения стека: как работает дифференциальное выполнение?, который имеет очень длинный и подробный ответ. Все это имело смысл... но когда я закончил, я все еще не знал, что на самом деле представляет собой чертово дифференциальное выполнение. Что это на самом деле?
2 ответа
Перераб. Это моя N-я попытка объяснить это.
Предположим, у вас есть простая детерминированная процедура, которая выполняется многократно, всегда следуя одной и той же последовательности выполнения операторов или вызовов процедур. Вызовы процедуры сами записывают все, что хотят, последовательно в FIFO, и они читают то же количество байтов с другого конца FIFO, например так:**
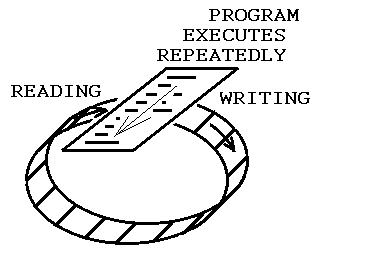
Вызываемые процедуры используют FIFO в качестве памяти, потому что то, что они читают, совпадает с тем, что они написали при предыдущем выполнении. Поэтому, если их аргументы в этот раз отличаются от прошлых, они могут это увидеть и сделать с этой информацией все, что захотят.
Чтобы начать, должно быть начальное выполнение, в котором происходит только запись, а не чтение. Симметрично, должно быть окончательное выполнение, при котором происходит только чтение, а не запись. Таким образом, существует регистр "глобального" режима, содержащий два бита: один для чтения и второй для записи, например:
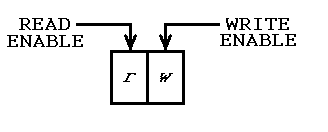
Первоначальное выполнение выполняется в режиме 01, поэтому выполняется только запись. Вызовы процедур могут видеть режим, поэтому они знают, что предыдущей истории нет. Если они хотят создавать объекты, они могут и помещают идентифицирующую информацию в FIFO (нет необходимости хранить в переменных).
Промежуточные исполнения выполняются в режиме 11, поэтому происходит чтение и запись, а вызовы процедур могут обнаруживать изменения данных. Если есть объекты, которые необходимо поддерживать в актуальном состоянии, их идентификационная информация считывается и записывается в FIFO, поэтому к ним можно получить доступ и, при необходимости, изменить.
Окончательное выполнение выполняется в режиме 10, поэтому происходит только чтение. В этом режиме вызовы процедур знают, что они просто очищаются. Если какие-либо объекты поддерживаются, их идентификаторы считываются из FIFO и могут быть удалены.
Но реальные процедуры не всегда следуют той же последовательности. Они содержат заявления IF(и другие способы варьировать то, что они делают). Как это можно сделать?
Ответ - это особый вид оператора IF(и его завершающего оператора ENDIF). Вот как это работает. Он записывает логическое значение своего тестового выражения и читает значение, которое тестовое выражение имело в прошлый раз. Таким образом, он может сказать, изменилось ли тестовое выражение, и принять меры. Требуется временно изменить регистр режима.
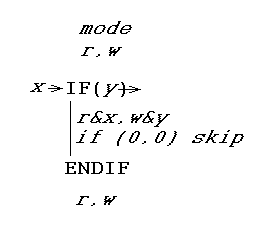
В частности, x - это предыдущее значение тестового выражения, считанное из FIFO (если чтение включено, иначе 0), а y - текущее значение тестового выражения, записанное в FIFO (если запись включена). (На самом деле, если запись не разрешена, тестовое выражение даже не вычисляется, а y равно 0.) Тогда x,y просто ЗАПИСЫВАЕТ регистр режима r, w. Таким образом, если тестовое выражение изменилось с True на False, тело выполняется в режиме только для чтения. И наоборот, если оно изменилось с False на True, тело выполняется в режиме только для записи. Если результат равен 00, код внутри оператора IF..ENDIF пропускается. (Возможно, вы захотите немного подумать о том, охватывает ли это все случаи - да.)
Это может быть неочевидно, но эти операторы IF..ENDIF могут быть произвольно вложены, и их можно распространить на все другие виды условных операторов, таких как ELSE, SWITCH, WHILE, FOR и даже на вызов функций, основанных на указателях. Это также тот случай, когда процедура может быть разделена на подпроцедуры в любой желаемой степени, в том числе рекурсивной, при условии соблюдения режима.
(Существует правило, которому необходимо следовать, называемое правилом режима стирания, которое заключается в том, что в режиме 10 не должно выполняться вычисление каких-либо последствий, таких как следование указателю или индексирование массива. Концептуально, причина в том, что режим 10 существует только с целью избавиться от вещей.)
Таким образом, это интересная структура управления, которую можно использовать для обнаружения изменений, обычно изменений данных, и принятия мер в отношении этих изменений.
Он используется в графических пользовательских интерфейсах для поддержания некоторого набора элементов управления или других объектов в соответствии с информацией о состоянии программы. Для этого используются три режима: SHOW(01), UPDATE(11) и ERASE(10). Изначально процедура выполняется в режиме SHOW, в котором создаются элементы управления, и соответствующая им информация заполняет FIFO. Затем выполняется любое количество выполнений в режиме ОБНОВЛЕНИЕ, где элементы управления изменяются по мере необходимости, чтобы оставаться в курсе состояния программы. Наконец, выполняется выполнение в режиме ERASE, при котором элементы управления удаляются из пользовательского интерфейса, а FIFO очищается.
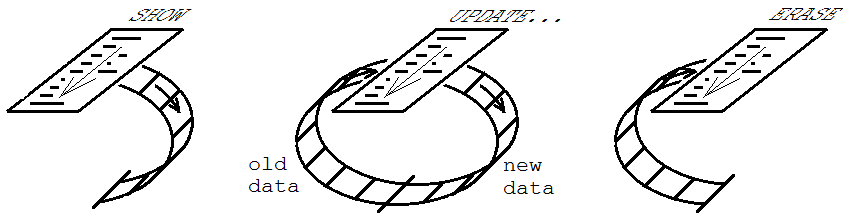
Преимущество этого состоит в том, что после того, как вы написали процедуру для создания всех элементов управления в зависимости от состояния программы, вам не нужно писать что-либо еще, чтобы впоследствии обновлять или очищать ее. Все, что вам не нужно писать, означает меньше возможностей совершать ошибки. (Существует простой способ обработки событий пользовательского ввода без необходимости писать обработчики событий и создавать для них имена. Это объясняется в одном из видео, приведенных ниже.)
С точки зрения управления памятью вам не нужно составлять имена переменных или структуру данных для хранения элементов управления. Он использует только достаточно памяти для видимых в данный момент элементов управления, в то время как потенциально видимые элементы управления могут быть неограниченными. Кроме того, никогда не возникает проблем со сборкой мусора ранее использованных элементов управления - FIFO действует как автоматический сборщик мусора.
С точки зрения производительности, когда он создает, удаляет или изменяет элементы управления, он в любом случае тратит время. Когда он просто обновляет элементы управления, а изменений нет, циклы, необходимые для чтения, записи и сравнения, являются микроскопическими по сравнению с изменением элементов управления.
Другое соображение производительности и правильности, относительно систем, которые обновляют отображение в ответ на события, состоит в том, что такая система требует, чтобы на каждое событие отвечали, а не дважды, в противном случае отображение будет неправильным, даже если некоторые последовательности событий могут быть самопроизвольными. отмена. При дифференциальном выполнении проходы обновления могут выполняться так часто или так редко, как требуется, и отображение всегда корректно в конце прохода.
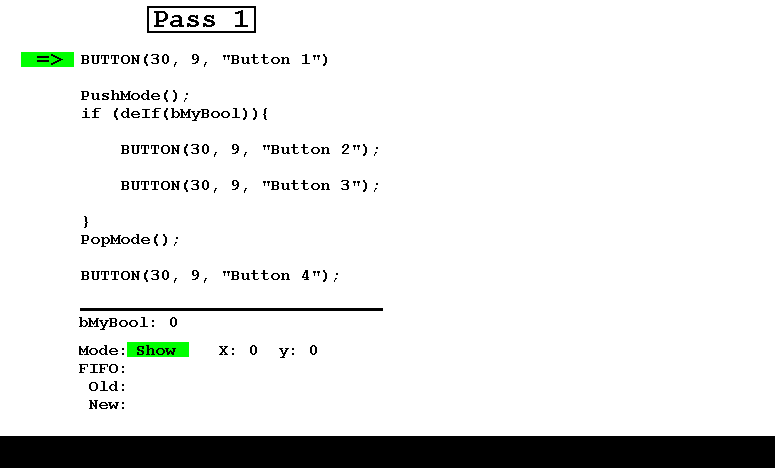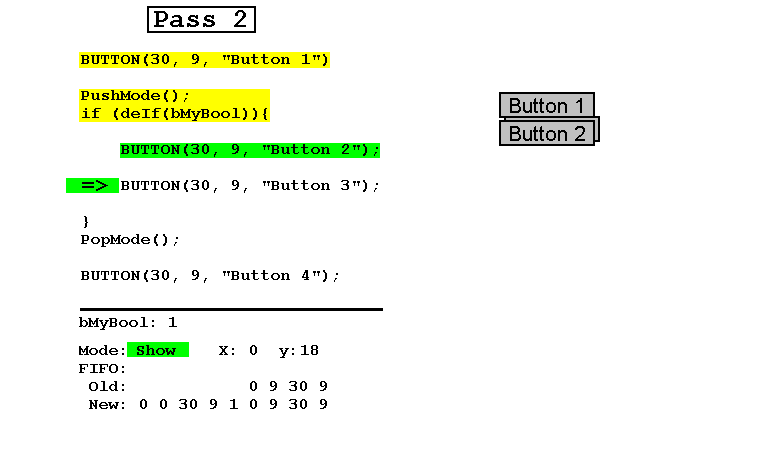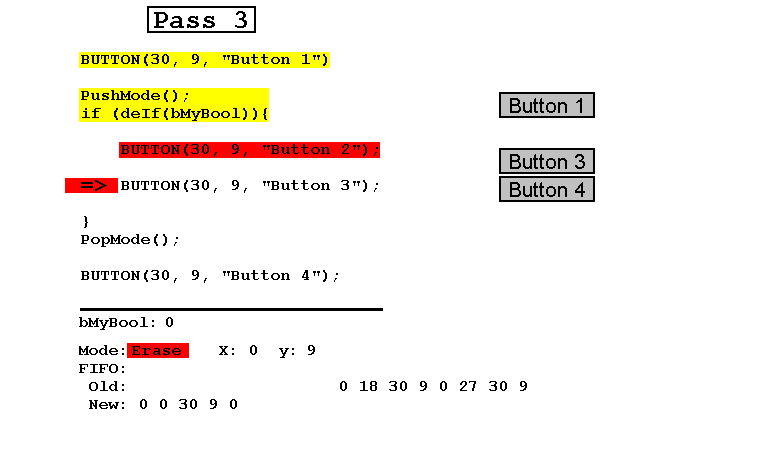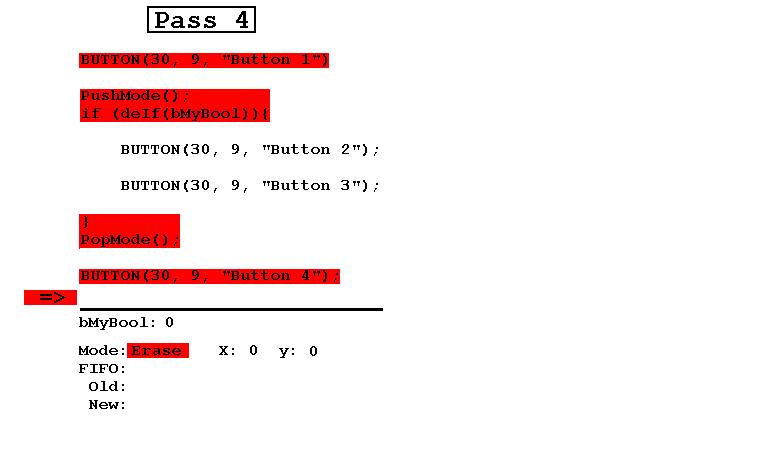
Вот чрезвычайно сокращенный пример, где есть 4 кнопки, из которых кнопки 2 и 3 являются условными для логической переменной.
- На первом проходе в режиме Show логическое значение false, поэтому отображаются только кнопки 1 и 4.
- Затем для логического значения устанавливается значение true, и этап 2 выполняется в режиме обновления, в котором создаются кнопки 2 и 3, а кнопка 4 перемещается, давая тот же результат, как если бы логическое значение было истинным при первом проходе.
- Затем логическое значение устанавливается в "ложь" и выполняется этап 3 в режиме обновления, в результате чего кнопки 2 и 3 удаляются, а кнопка 4 возвращается на прежнее место.
- Наконец, проход 4 выполняется в режиме стирания, в результате чего все исчезает.
(В этом примере изменения отменяются в обратном порядке, как они были сделаны, но в этом нет необходимости. Изменения могут быть внесены и отменены в любом порядке.)
Обратите внимание, что в любое время FIFO, состоящий из соединенных вместе Старого и Нового, содержит в точности параметры видимых кнопок плюс логическое значение.
Смысл этого в том, чтобы показать, как можно использовать одну процедуру "рисования" без изменений для произвольного автоматического инкрементного обновления и удаления. Я надеюсь, что ясно, что это работает для произвольной глубины вызовов подпрограммы и произвольной вложенности условий, включая switch, while а также for циклы, вызов функций, основанных на указателях, и т. д. Если мне нужно это объяснить, тогда я открыт к потчам, чтобы сделать объяснение слишком сложным.
Наконец, здесь есть несколько грубых, но коротких видео.
** Технически, они должны прочитать то же количество байтов, которое они написали в прошлый раз. Так, например, они могли бы написать строку, которой предшествует число символов, и это нормально.
ДОБАВЛЕНО: Мне потребовалось много времени, чтобы убедиться, что это всегда будет работать. Я наконец доказал это. Он основан на свойстве Sync, что примерно означает, что в любой точке программы число байтов, записанных на предыдущем проходе, равно числу, считанному на последующем проходе. Идея доказательства заключается в том, чтобы сделать это индукцией по длине программы. Самым сложным для доказательства является случай раздела программы, состоящего из s 1, за которым следует IF(тест) s 2 ENDIF, где s 1 и s 2 - подразделы программы, каждый из которых удовлетворяет свойству Sync. Делать это только в тексте просто глаз, но здесь я попытался изобразить это: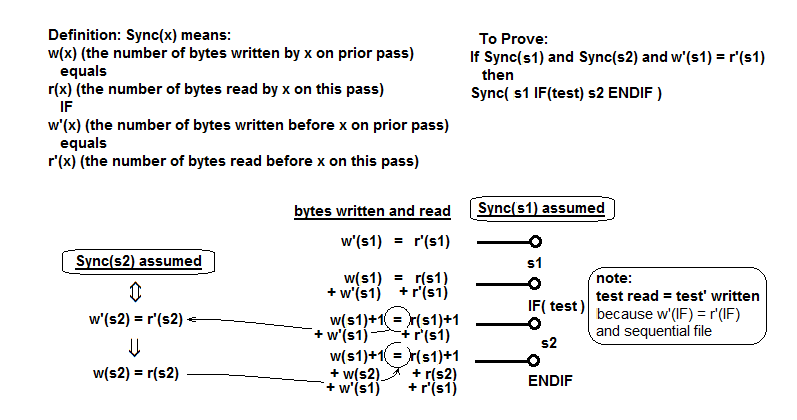
Он определяет свойство Sync и показывает количество байтов, записанных и прочитанных в каждой точке кода, и показывает, что они равны. Ключевые моменты состоят в том, что 1) значение тестового выражения (0 или 1), считанное на текущем проходе, должно равняться значению, записанному на предыдущем проходе, и 2) условие Sync(s2) удовлетворяется. Это удовлетворяет свойству Sync для объединенной программы.
Я прочитал все, что смог найти, посмотрел видео и попробую описать основные принципы.
обзор
Это основанный на DSL шаблон проектирования для реализации пользовательских интерфейсов и, возможно, других ориентированных на состояние подсистем чистым и эффективным способом. Основное внимание уделяется проблеме изменения конфигурации графического интерфейса в соответствии с текущим состоянием программы, где это состояние включает в себя состояние самих графических элементов графического интерфейса, например, пользователь выбирает вкладки, переключатели и элементы меню, а виджеты появляются / исчезают произвольно сложными способами.
Описание
Шаблон предполагает:
- Глобальная коллекция C объектов, которая нуждается в периодическом обновлении.
- Семейство типов для тех объектов, где экземпляры имеют параметры.
- Набор операций на C:
- Add AP - Поместить новый объект A в C с параметрами P.
- Modify AP - Изменить параметры объекта A в C на P.
- Удалить A - Удалить объект A из C.
- Обновление C состоит из последовательности таких операций для преобразования C в заданную целевую коллекцию, скажем, C'.
- Учитывая текущую коллекцию C и цель C', цель состоит в том, чтобы найти обновление с минимальными затратами. Каждая операция имеет стоимость единицы.
- Набор возможных коллекций описан на доменно-специфическом языке (DSL), который имеет следующие команды:
- Создать AH - создать экземпляр некоторого объекта A, используя дополнительные подсказки H, и добавить его в глобальное состояние. (Обратите внимание, что здесь нет параметров.)
- If B To T Else F - Условно выполнить последовательность команд T или F на основе булевой функции B, которая может зависеть от чего-либо в работающей программе.
Во всех примерах
- Глобальное состояние - это экран или окно с графическим интерфейсом.
- Объекты являются виджетами пользовательского интерфейса. Типы: кнопка, выпадающий список, текстовое поле,...
- Параметры управляют внешним видом и поведением виджета.
- Каждое обновление состоит из добавления, удаления и изменения (например, перемещения) любого количества виджетов в графическом интерфейсе.
- Команды Create создают виджеты: кнопки, выпадающие списки,...
- Булевы функции зависят от основного состояния программы, включая состояние самих элементов управления GUI. Таким образом, изменение элемента управления может повлиять на экран.
Недостающие ссылки
Изобретатель никогда не заявляет об этом явно, но ключевая идея состоит в том, что мы запускаем интерпретатор DSL над программой, которая представляет все возможные целевые коллекции (экраны) каждый раз, когда мы ожидаем, что любая комбинация значений Булевой функции B изменилась. Интерпретатор выполняет грязную работу по приведению коллекции (экрана) в соответствие с новыми значениями B, выпуская последовательность операций Add, Delete и Modify.
Есть последнее скрытое предположение: интерпретатор DSL включает в себя некоторый алгоритм, который может предоставлять параметры для операций добавления и изменения на основе истории созданий, выполненных до сих пор во время его текущего выполнения. В контексте GUI это алгоритм компоновки, а подсказки Create являются подсказками компоновки.
Изюминка
Сила этого метода заключается в том, как сложность заключена в интерпретаторе DSL. Глупый интерпретатор будет начинаться с удаления всех объектов (виджетов) в коллекции (экрана), а затем добавления нового для каждой команды Create в том виде, в котором он их видит, проходя через программу DSL. Изменение никогда не произойдет.
Дифференциальное исполнение - это просто более разумная стратегия для переводчика. Это сводится к ведению сериализованной записи последнего исполнения переводчика. Это имеет смысл, потому что запись захватывает то, что в настоящее время на экране. Во время текущего запуска интерпретатор консультируется с записью, чтобы принять решение о том, как вызвать целевую коллекцию (конфигурация виджета) с операциями, имеющими наименьшую стоимость. Это сводится к тому, что мы никогда не удаляем объект (виджет), а добавляем его снова позже по цене 2. DE всегда будет вместо этого модифицировать, что будет стоить 1. Если нам случится запустить интерпретатор в каком-то случае, когда значения B не изменились, алгоритм DE вообще не будет генерировать никаких операций: записанный поток уже представляет цель.
Когда интерпретатор выполняет команды, он также настраивает запись для своего следующего запуска.
Аналогичный алгоритм
Алгоритм имеет тот же вид, что и минимальное расстояние редактирования (MED). Однако DE - более простая проблема, чем MED, потому что в сериализованных строках исполнения DE нет "повторяющихся символов", как в MED. Это означает, что мы можем найти оптимальное решение с простым онлайн-жадным алгоритмом, а не с динамическим программированием. Это то, что делает алгоритм изобретателя.
Сильные стороны
Я полагаю, что это хороший шаблон для реализации систем со многими сложными формами, в которых требуется полный контроль над размещением виджетов с помощью собственного алгоритма компоновки и / или логики "если еще" того, что видимое, глубоко вложено. Если в глубине логики формы есть K гнезд "if elses" N, то есть K*2^N различных макетов, чтобы получить право. Традиционные системы проектирования форм (по крайней мере, те, которые я использовал) совсем не поддерживают большие значения K, N. Вы склоняетесь к большому количеству похожих макетов и специальной логике, чтобы выбрать их, которые уродливы и сложны в обслуживании. Этот шаблон DSL кажется способом избежать всего этого. В системах с достаточным количеством форм, чтобы компенсировать стоимость интерпретатора DSL, он даже будет дешевле при первоначальной реализации. Разделение интересов также является сильной стороной. Программы DSL абстрагируют содержание форм, в то время как интерпретатор является стратегией компоновки, действуя на основе подсказок DSL. Правильно подобрать дизайн DSL и подсказки макета кажется серьезной и интересной проблемой.
Сомнительный...
Я не уверен, что отказ от удаления / добавления пар в пользу Modify стоит всех проблем в современных системах. Изобретатель, похоже, больше всего гордится этой оптимизацией, но более важной идеей является лаконичный DSL с условными обозначениями для представления форм со сложностью компоновки, выделенной в интерпретаторе DSL.
резюмировать
До сих пор изобретатель фокусировался на глубоких деталях того, как переводчик принимает свои решения. Это сбивает с толку, потому что это направлено на деревья, в то время как лес представляет больший интерес. Это описание леса.