R ergm - указание эффекта соответствия узла для двух атрибутов
В настоящее время я работаю над данными социальной сети с R ergm пакет. Я хочу оценить условную вероятность того, что связь является гомофильной по двум различным переменным, но в зависимости от того, как я определяю модель, результаты немного отличаются.
В первом случае я поставил два nodematch слагаемые в моей модели, по одному на каждую переменную, которая меня интересует, и я нахожу условное логарифмическое нечетко-гомофильную связь, суммируя 3 коэффициента моей модели ("краевые" слагаемые и два nodematch термины).
Во втором случае я прямо указываю только один nodematch срок, для связи гомофильной по обеим переменным.
И результаты, которые я получаю, хотя и близки, по-прежнему различны, в то время как в обоих случаях я должен получить лог-нечетную связь, возникающую между людьми, разделяющими оба эти атрибута.
Вот пример из данных Сэмпсона:
# Load the data :
library(statnet)
data(sampson)
#First model: I specify two nodematch terms, one for 'cloisterville' and one for 'group'.
m1 <- ergm(samplike ~ edges + nodematch('cloisterville') + nodematch('group'))
#Second model: this time, I have only one term asking for a `nodematch` on both terms at the same time.
m2 <- ergm(samplike ~ edges + nodematch(c('cloisterville','group')))
#Here is the output of both models:
summary(m1)
summary(m2)
Таким образом, согласно первой модели, условный лог-нечет гомофильной связи по обеим переменным должен быть:
-2.250 + 0.586 + 2.389
0,725
Тем не менее, согласно второй модели, лог-нечет этой же дважды гомофильной связи должен быть:
-1,856 + 2,659
0,803
Соответствующие вероятности 0,6737071 и 0,6906158
Знаете ли вы, почему результаты отличаются в обоих случаях, в то время как это должно дать одинаковую условную вероятность того же вида связи?
Спасибо большое за вашу помощь,
С уважением
Timothee
1 ответ
Мы не должны ожидать одинаковых результатов, поскольку модели оценивают две разные вещи. По сути, модель 1 оценивает гомофилию на cloisterville или на group в то время как модель 2 оценивает гомофилию на обоих cloisterville а также group,
Чтобы быть более точным, первая модель тестирует гомофилию на group Чистая тенденция к гомофилии на cloisterville, и наоборот. Вторая модель рассматривает, есть ли тенденция к гомофилии по обоим признакам одновременно. Формируют ли монахи связи внутри групп и исходя из своего расположения в монастырях?
См примечание в ?ergm.terms за nodematch:
(Когда дано несколько имен, статистика учитывает только те, по которым совпадают все названные атрибуты.)
Это легко увидеть визуально:
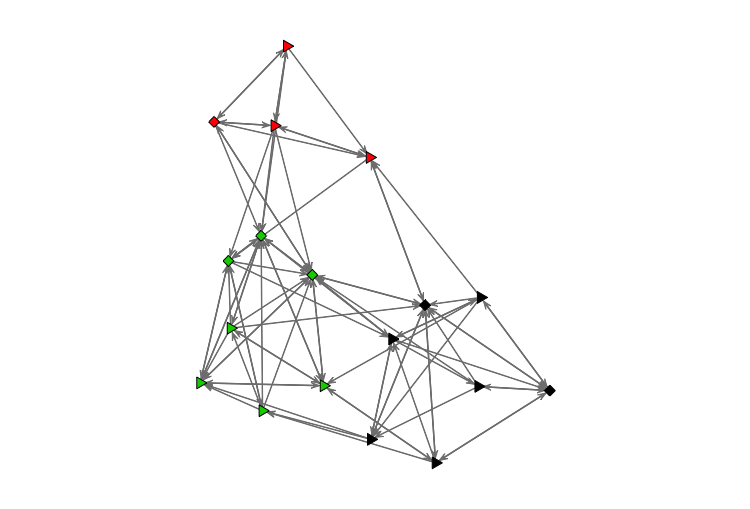
Цвета группы. Квадраты означает cloisterville==TRUE и треугольники означает cloisterville==FALSE, Семестр nodematch(c('cloisterville','group')) считает только те края, где цвета и формы совпадают!