Экстраполировать значения в Pandas DataFrame
Очень просто интерполировать ячейки NaN в DataFrame Pandas:
In [98]: df
Out[98]:
neg neu pos avg
250 0.508475 0.527027 0.641292 0.558931
500 NaN NaN NaN NaN
1000 0.650000 0.571429 0.653983 0.625137
2000 NaN NaN NaN NaN
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN
[12 rows x 4 columns]
In [99]: df.interpolate(method='nearest', axis=0)
Out[99]:
neg neu pos avg
250 0.508475 0.527027 0.641292 0.558931
500 0.508475 0.527027 0.641292 0.558931
1000 0.650000 0.571429 0.653983 0.625137
2000 0.650000 0.571429 0.653983 0.625137
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN
[12 rows x 4 columns]
Я также хотел бы, чтобы он экстраполировал значения NaN, находящиеся вне области интерполяции, используя данный метод. Как я мог лучше всего это сделать?
4 ответа
Экстраполирующие панды DataFrame s
DataFrame s может быть экстраполирован, однако, в pandas нет простого вызова метода и требуется другая библиотека (например, scipy.optimize).
Экстраполяция
В общем случае экстраполяция требует определенных предположений относительно экстраполируемых данных. Одним из способов является подгонка кривой некоторого общего параметризованного уравнения к данным, чтобы найти значения параметров, которые наилучшим образом описывают существующие данные, которые затем используются для вычисления значений, которые выходят за пределы диапазона этих данных. Сложная и ограничивающая проблема с этим подходом заключается в том, что при выборе параметризованного уравнения необходимо сделать некоторые предположения о тренде. Это может быть найдено методом проб и ошибок с различными уравнениями, чтобы дать желаемый результат, или это иногда может быть выведено из источника данных. Данные, представленные в этом вопросе, на самом деле недостаточно велики для набора данных, чтобы получить хорошо подходящую кривую; однако, это достаточно хорошо для иллюстрации.
Ниже приведен пример экстраполяции DataFrame с полиномом 3- го порядка
f (x) = a x 3 + b x 2 + c x + d (уравнение 1)
Это общая функция (func()) соответствует кривой для каждого столбца, чтобы получить уникальные параметры столбца (например, a, b, c, d). Затем эти параметризованные уравнения используются для экстраполяции данных в каждом столбце для всех индексов с NaN s.
import pandas as pd
from cStringIO import StringIO
from scipy.optimize import curve_fit
df = pd.read_table(StringIO('''
neg neu pos avg
0 NaN NaN NaN NaN
250 0.508475 0.527027 0.641292 0.558931
500 NaN NaN NaN NaN
1000 0.650000 0.571429 0.653983 0.625137
2000 NaN NaN NaN NaN
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN'''), sep='\s+')
# Do the original interpolation
df.interpolate(method='nearest', xis=0, inplace=True)
# Display result
print 'Interpolated data:'
print df
print
# Function to curve fit to the data
def func(x, a, b, c, d):
return a * (x ** 3) + b * (x ** 2) + c * x + d
# Initial parameter guess, just to kick off the optimization
guess = (0.5, 0.5, 0.5, 0.5)
# Create copy of data to remove NaNs for curve fitting
fit_df = df.dropna()
# Place to store function parameters for each column
col_params = {}
# Curve fit each column
for col in fit_df.columns:
# Get x & y
x = fit_df.index.astype(float).values
y = fit_df[col].values
# Curve fit column and get curve parameters
params = curve_fit(func, x, y, guess)
# Store optimized parameters
col_params[col] = params[0]
# Extrapolate each column
for col in df.columns:
# Get the index values for NaNs in the column
x = df[pd.isnull(df[col])].index.astype(float).values
# Extrapolate those points with the fitted function
df[col][x] = func(x, *col_params[col])
# Display result
print 'Extrapolated data:'
print df
print
print 'Data was extrapolated with these column functions:'
for col in col_params:
print 'f_{}(x) = {:0.3e} x^3 + {:0.3e} x^2 + {:0.4f} x + {:0.4f}'.format(col, *col_params[col])
Экстраполируя результаты
Interpolated data:
neg neu pos avg
0 NaN NaN NaN NaN
250 0.508475 0.527027 0.641292 0.558931
500 0.508475 0.527027 0.641292 0.558931
1000 0.650000 0.571429 0.653983 0.625137
2000 0.650000 0.571429 0.653983 0.625137
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN
Extrapolated data:
neg neu pos avg
0 0.411206 0.486983 0.631233 0.509807
250 0.508475 0.527027 0.641292 0.558931
500 0.508475 0.527027 0.641292 0.558931
1000 0.650000 0.571429 0.653983 0.625137
2000 0.650000 0.571429 0.653983 0.625137
3000 0.619718 0.663158 0.665468 0.649448
4000 0.621036 0.969232 0.708464 0.766245
6000 1.197762 2.799529 0.991552 1.662954
8000 3.281869 7.191776 1.702860 4.058855
10000 7.767992 15.272849 3.041316 8.694096
20000 97.540944 150.451269 26.103320 91.365599
30000 381.559069 546.881749 94.683310 341.042883
50000 1979.646859 2686.936912 467.861511 1711.489069
Data was extrapolated with these column functions:
f_neg(x) = 1.864e-11 x^3 + -1.471e-07 x^2 + 0.0003 x + 0.4112
f_neu(x) = 2.348e-11 x^3 + -1.023e-07 x^2 + 0.0002 x + 0.4870
f_avg(x) = 1.542e-11 x^3 + -9.016e-08 x^2 + 0.0002 x + 0.5098
f_pos(x) = 4.144e-12 x^3 + -2.107e-08 x^2 + 0.0000 x + 0.6312
Участок для avg колонка
Без большого набора данных или без знания источника данных этот результат может быть совершенно неверным, но он должен служить примером процесса экстраполяции DataFrame, Предполагаемое уравнение в func() вероятно, придется поиграться, чтобы получить правильную экстраполяцию. Также не предпринимались попытки сделать код эффективным.
Обновить:
Если ваш индекс не числовой, как DatetimeIndex Посмотрите этот ответ о том, как их экстраполировать.
import pandas as pd
try:
# for Python2
from cStringIO import StringIO
except ImportError:
# for Python3
from io import StringIO
df = pd.read_table(StringIO('''
neg neu pos avg
0 NaN NaN NaN NaN
250 0.508475 0.527027 0.641292 0.558931
999 NaN NaN NaN NaN
1000 0.650000 0.571429 0.653983 0.625137
2000 NaN NaN NaN NaN
3000 0.619718 0.663158 0.665468 0.649448
4000 NaN NaN NaN NaN
6000 NaN NaN NaN NaN
8000 NaN NaN NaN NaN
10000 NaN NaN NaN NaN
20000 NaN NaN NaN NaN
30000 NaN NaN NaN NaN
50000 NaN NaN NaN NaN'''), sep='\s+')
print(df.interpolate(method='nearest', axis=0).ffill().bfill())
доходность
neg neu pos avg
0 0.508475 0.527027 0.641292 0.558931
250 0.508475 0.527027 0.641292 0.558931
999 0.650000 0.571429 0.653983 0.625137
1000 0.650000 0.571429 0.653983 0.625137
2000 0.650000 0.571429 0.653983 0.625137
3000 0.619718 0.663158 0.665468 0.649448
4000 0.619718 0.663158 0.665468 0.649448
6000 0.619718 0.663158 0.665468 0.649448
8000 0.619718 0.663158 0.665468 0.649448
10000 0.619718 0.663158 0.665468 0.649448
20000 0.619718 0.663158 0.665468 0.649448
30000 0.619718 0.663158 0.665468 0.649448
50000 0.619718 0.663158 0.665468 0.649448
Примечание: я изменил ваш df немного, чтобы показать, как интерполировать с nearest отличается от делать df.fillna, (См. Строку с индексом 999.)
Я также добавил строку NaN с индексом 0, чтобы показать, что bfill() также может быть необходимо.
У меня была та же проблема, но я не мог найти ничего простого и полезного (без определения новых функций), характерного для панд. Однако я обнаружил, что InterpolatedUnivariateSpline (из scipy) очень полезен для экстраполяции. Это может дать вам гибкость в изменении заказов, а не постоянное.
Это связанный пример:
import matplotlib.pyplot as plt
from scipy.interpolate import InterpolatedUnivariateSpline
x = np.linspace(-3, 3, 50)
y = np.exp(-x**2) + 0.1 * np.random.randn(50)
spl = InterpolatedUnivariateSpline(x, y)
plt.plot(x, y, 'ro', ms=5)
xs = np.linspace(-3, 3, 1000)
plt.plot(xs, spl(xs), 'g', lw=3, alpha=0.7)
plt.show()
Возможный ответ только с пустым импортом! Я думаю, что также обращаюсь к DatetimeIndex.
Моя дата:
time mystery_var
0 0 NaN
1 105 36.7089
2 294 46.3768
3 385 59.2105
4 567 15.0794
5 791 NaN
6 917 NaN
7 1092 NaN
8 1281 106.1069
9 1393 102.0833
10 1512 167.0000
Изначально время было датой с точностью до дня и преобразовано с использованием
np.timedelta64(1, "D").
# --using variable "v" in case you want to iterate over multiple--
v = "mystery_var"
group_dates = g.loc[g[v].notna()].time
all_group_dates = g.time
# we subtract the first date in our series
gd = group_dates - all_group_dates.iloc[0]
ogd = all_group_dates - all_group_dates.iloc[0]
# because we subtracted the first date in our series
# this places all measurements at their true x-value
xp = np.linspace(ogd.iloc[0], ogd.iloc[-1], 100)
entries = g.loc[g[v].notna()][v]
# --fitting the model--
# a line
z = np.polyfit(gd, entries, 1)
p = np.poly1d(z)
Что мы сделали:
plt.scatter(gd, entries)
plt.plot(xp, p(xp))
plt.xlim(-500, 1750)
plt.ylim(-50, 200)
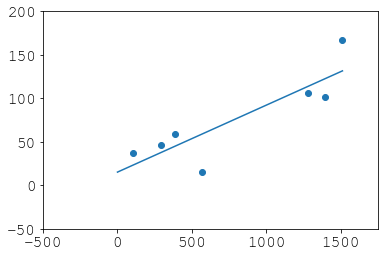
Восстановление:
# didnt haves
dh = (ogd)[g[v].isna()]
# now haves
nh = pd.Series(p(dh), index=dh.index, name=v)
new_g = pd.concat([pd.concat([entries, nh]), all_group_dates], axis=1).sort_index()
new_g["new"] = 0
new_g.loc[dh.index, "new"] = 1
Результат:
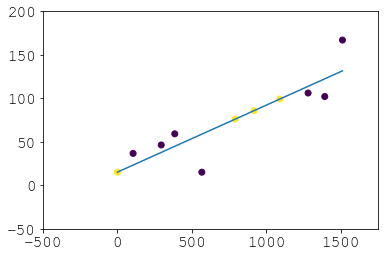
И там вы избегаете обратной засыпки, которая на самом деле не является экстраполяцией и, вероятно, вообще нежелательна. Так что это альтернатива, если
scipy.optimizeвас пугает и вы не обижаетесь на вложенные
pd.concatс. Если вы хотите экстраполировать даты, которых нет в вашей серии, просто поиграйте с linspace и/или затем выполните
p(new_times):