Какое неверное предсказание ветвления обнаруживает целевой буфер ветвления?
В настоящее время я смотрю на различные части конвейера ЦП, которые могут обнаружить ошибочные прогнозы отрасли. Я нашел это:
- Целевой буфер ветвления (BPU CLEAR)
- Калькулятор адреса филиала (BA CLEAR)
- Блок выполнения прыжка (не уверен в названии сигнала здесь??)
Я знаю, что обнаруживают 2 и 3, но я не понимаю, какое неверное предсказание обнаружено в BTB. BAC определяет, где BTB ошибочно предсказал ветвление для команды без ветвления, где BTB не удалось обнаружить ветвление или BTB неверно предсказал целевой адрес для команды RET x86. Исполнительный блок оценивает ветвь и определяет, была ли она правильной.
Какой тип неправильного прогноза обнаружен в целевом буфере филиала? Что именно выявляется здесь как неверное предсказание?
Единственная подсказка, которую я смог найти, была в том 3 в Руководствах для разработчиков Intel (два счетчика событий BPU CLEAR внизу):

BPU предсказал занятую ветвь после того, как неправильно предположил, что она не была взята.
Кажется, это подразумевает, что предсказание делается не "синхронно", а скорее "асинхронно", следовательно, "после неверного предположения"??
ОБНОВИТЬ:
Росс, это схема ветви процессора из оригинального патента Intel (как это для "чтения"?):

Я не вижу "Отдел предсказания ветвлений"? Было бы разумно, чтобы кто-то, прочитав эту статью, предположил, что "BPU" - это ленивый способ группировки BTB-цепей, BTB-кеша, BAC и RSB??
Таким образом, мой вопрос остается открытым, какой компонент вызывает сигнал BPU CLEAR?
2 ответа
Это хороший вопрос! Я думаю, что путаница, которую это вызывает, вызвана странными схемами именования Intel, которые часто перегружают стандартные термины в академических кругах. Я постараюсь как ответить на ваш вопрос, так и устранить недоразумение, которое я вижу в комментариях.
Прежде всего. Я согласен, что в стандартной терминологии информатики целевой буфер ветвления не является синонимом предиктора ветвления. Однако в терминологии Intel "Целевой буфер ветвления" (BTB) [в столицах] является чем-то конкретным и содержит как предиктор, так и кэш целевого буфера ветвления (BTBC), который представляет собой просто таблицу инструкций ветвления и их целей по полученному результату. Этот BTBC - это то, что большинство людей понимают как целевой буфер ветвления [нижний регистр]. Так что же такое Калькулятор адресов филиалов (BAC) и зачем он нам нужен, если у нас есть BTB?
Итак, вы понимаете, что современные процессоры разбиты на конвейеры с несколькими этапами. Является ли это простым конвейерным процессором или вышестоящим суперскларным процессором, первые этапы обычно извлекаются, а затем декодируются. На этапе выборки у нас есть только адрес текущей инструкции, содержащейся в счетчике программ (ПК). Мы используем ПК для загрузки байтов из памяти и отправки их на стадию декодирования. В большинстве случаев мы увеличиваем ПК, чтобы загрузить последующую инструкцию (и), но в других случаях мы обрабатываем инструкцию потока управления, которая может полностью изменить содержимое ПК.
Цель BTB состоит в том, чтобы угадать, указывает ли адрес в ПК на инструкцию перехода, и если да, каким должен быть следующий адрес в ПК? Это нормально, мы можем использовать предиктор для условных переходов и BTBC для следующего адреса. Если прогноз был верным, это здорово! Если прогноз был неверным, что тогда? Если BTB - единственная единица, которую мы имеем, тогда нам придется ждать, пока ветвь не достигнет стадии выпуска / выполнения конвейера. Мы должны были бы промыть трубопровод и начать заново. Но не каждая ситуация должна быть решена так поздно. Это где калькулятор адреса филиала (BAC) входит.
BTB используется на этапе выборки конвейера, но BAC находится на этапе декодирования. После того, как инструкция, которую мы извлекли, декодируется, у нас фактически появляется намного больше информации, которая может быть полезна Первая новая информация, которую мы знаем: "Является ли инструкция, которую я получил, ветвью?" На этапе извлечения мы понятия не имеем, а BTB может только догадываться, но на этапе декодирования мы это точно знаем. Возможно, что BTB предсказывает переход, когда на самом деле инструкция не является переходом; в этом случае BAC остановит блок выборки, исправит BTB и возобновит выборку правильно.
А как насчет филиалов, как unconditional relative а также call? Они могут быть проверены на этапе декодирования. BAC проверит BTB, посмотрит, есть ли записи в BTBC и установит предиктор, чтобы всегда предсказать принятый За conditional В ответвлениях BAC не может подтвердить, были ли они приняты / еще не приняты, но он может, по крайней мере, проверить предсказанный адрес и исправить BTB в случае неправильного предсказания адреса. Иногда BTB вообще не идентифицирует / не предсказывает ветку. BAC необходимо исправить это и дать BTB новую информацию об этой инструкции. Поскольку BAC не имеет своего собственного условного предиктора, он использует простой механизм (обратные ответвления принимаются, прямые ответвления не принимаются).
Кто-то должен будет подтвердить мое понимание этих аппаратных счетчиков, но я считаю, что они означают следующее:
BACLEAR.CLEARувеличивается, когда BTB в fetch делает плохую работу, а BAC в декодере может это исправить.BPU_CLEARS.EARLYувеличивается, когда fetch решает (неправильно) загрузить следующую инструкцию до того, как BTB прогнозирует, что она должна фактически загружаться из взятого пути. Это связано с тем, что BTB требуется несколько циклов, а выборка использует это время для умозрительной загрузки последовательного блока инструкций. Это может быть связано с тем, что Intel использует два BTB, один быстрее, а другой медленнее, но точнее. Требуется больше циклов, чтобы получить лучший прогноз.
Это объясняет, почему штраф за обнаружение неправильного прогноза в BTB составляет 2/3 цикла, тогда как обнаружение неправильного прогноза в BAC составляет 8 циклов.
Факт
BPU_CLEARS.EARLYОписание показывает, что это событие происходит, когда BPU предсказывает, корректируя предположение, подразумевая, что во внешнем интерфейсе есть 3 этапа. Предполагать, прогнозировать и рассчитывать.
В нем также говорится, что это происходит, когда BPU предполагает, что он не был взят, а затем прогнозирует, что он был принят, а не наоборот. Это означает, что всегда предполагается, что его не принимают. Вероятно, это указывает на промах L1 BTB.
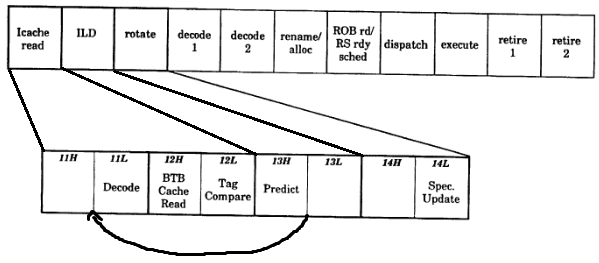
Вот конвейер P6. Используя это в качестве примера, ранняя очистка происходит в 3-м цикле (13), когда делается прогноз (и считываются цель и тип записи, и поэтому безусловные цели перехода теперь известны, а также условные и их прогнозы), используется первая предсказанная взятая цель перехода в наборе для 16-байтового блока. На этом этапе 2 этапа конвейера до него уже были заполнены выборками и началом поиска из следующих последовательных 16-байтовых блоков, что означает, что они должны быть сброшены, если есть какое-либо прогнозирование (в противном случае это не нужно be, поскольку следующий последовательный 16-байтовый блок уже начинает искать на этапе pipestage перед ним), оставляя 2-тактный промежуток или пузырь. Поиск в кеше выполняется одновременно с поиском BTB,Таким образом, необходимо очистить как BTB, так и кеш-параллельные 2 pipestages, тогда как 3-й этап не нужно очищать из кеша или BTB, потому что IP-адрес находится на подтвержденном пути и IP-адрес, который в настоящее время просматривается для следующий. Фактически, в этом дизайне P6 есть только один цикл для этого раннего сброса, потому что новый IP-адрес может быть отправлен на первый этап для повторного декодирования набора по высокому фронту тактового сигнала, в то время как эти другие этапы очищаются.
Если это правда, каждая взятая ветка вызовет раннее очищение. Похоже, это поддерживается https://gist.github.com/mattgodbolt/4e2cbb1c9aa97e0c5478 https://github.com/mattgodbolt/agner/blob/master/tests/branch.py , где BaClrEly равно 0 для всех невнимаемых Branch и 900k инструкций вызывают раннее очищение 100k, что соответствует 1 из 9 инструкций, являющихся взятой ветвью.
Такая конвейерная обработка более выгодна, чем ожидание прогноза перед началом поиска следующего IP-адреса. Это будет означать поиск через каждый второй цикл. Это дало бы пропускную способность прогнозов в 16 байт каждые 2 цикла, то есть 8B/c. В конвейерном сценарии P6 пропускная способность составляет 16 байт за цикл при правильном предположении и 8 Байт / c при неправильном предположении. Очевидно быстрее. Если мы предположим, что 2/3 предположений верны для 1 из 9 инструкций, являющихся взятой ветвью для 4 инструкций на блок, это дает пропускную способность 16 Б на ((1 * 0,666) + 2 * 0,333)) = 1,332 цикла вместо 16 Б. за 2 цикла.
Поздний ясный (
BPU_CLEARS.LATE), похоже, происходит в ILD. На диаграмме выше поиск в кэше занимает всего 2 цикла. В более поздних процессорах это, по-видимому, занимает 4 цикла. Это позволяет вставить еще один L2 BTB и выполнить поиск в нем. «Обход MRU» и «конфликты MRU» могут просто означать, что в MRU BTB произошел пропуск, или это также может означать, что прогноз в L2 отличается от прогноза в L1, если он использует другой алгоритм прогнозирования и файл истории. BPU предоставит битовую маску для всех прогнозов для текущих 16 байтов в буфере ILD, а также маску для сделанных прогнозов и первую взятую цель перехода в этих байтах., это биты предсказания после процесса обращения к BTB L1 и L2 параллельно с конвейером выборки. Эти биты предсказания известны на этапе вместе с ILD и помещаются рядом с буфером ILD, как только они становятся известны вместе с битовыми масками, сгенерированными ILD для начальных и конечных байтов инструкции, эти битовые маски сдвигаются в ILD по мере того, как они выравнивается по границе следующей инструкции). Любые конфликты BTB L2 известны после завершения поиска и до того, как BPU отправит эти биты в ILD (конфликты не обнаруживаются никаким действием самого ILD). Если есть конфликт (в частности, что более ранняя ветвь в 16-байтовом блоке теперь предсказывается или эта первая ветвь в блоке больше не предсказывается),конвейер переадресовывается, и он создает только 3 цикла (что означает, что поиск L2 завершается в следующем цикле и выполняется параллельно с поиском L1 BTB). Пузырь с 3 циклами исходит от ILD на этапе 5, повторно управляя конвейером на нижнем крае этапа 1 и этапов 2, 3 и 4 промывки (что соответствует указанным задержкам L1i в 4 цикла, поскольку поиск L1i происходит на этапах 1. –4 за попадание + попадание ITLB). Как только предсказание сделано, BTB обновляют спекулятивные локальные биты BHR записей с помощью сделанного предсказания.поскольку поиск L1i происходит на этапах 1–4 для попадания + попадание ITLB). Как только предсказание сделано, BTB обновляют спекулятивные локальные биты BHR записей с помощью сделанного предсказания.поскольку поиск L1i происходит на этапах 1–4 для попадания + попадание ITLB). Как только предсказание сделано, BTB обновляют спекулятивные локальные биты BHR записей с помощью сделанного предсказания.
Набор BTB содержит 4 способа для максимум 4 ветвей на 16 байтов (где все пути в наборе помечаются одним и тем же тегом, указывающим на этот конкретный выровненный блок из 16 байтов). У каждого пути есть смещение, указывающее 4 младших бита адреса, следовательно, позиция байта в пределах 16 байтов. Каждая запись также имеет спекулятивный бит, действительный бит, биты pLRU, спекулятивную локальную BHR, реальную локальную BHR, и каждый способ использует установленный BPT (PHT) в качестве второго уровня прогнозирования. Это может быть связано с GHR / спекулятивным GHR.
Я не уверен, почему Haswell и Ivy Bridge имеют такие значения для раннего и позднего клиров, но эти события (0xe8) исчезают, начиная с SnB , что совпадает с тем, когда BTB был объединен в единую структуру ... может быть, это фиктивные значения? Я также не уверен, почему у Nehalem есть пузырь с 2 циклами для ранней очистки, поскольку дизайн L1 Nehalem BTB, похоже, не сильно отличается от P6 BTB, оба 512 входов с 4 способами на набор. Вероятно, это связано с тем, что он был разбит на большее количество этапов из-за более высоких тактовых частот и, следовательно, большей задержки кэша L1i.
BACLEAR - это когда битовая маска в IQ, предоставленном в BAC, указывает, что BPU не смог сделать прогноз (это не относится к косвенному), а статическое прогнозирование в IQ обнаруживает условный переход, соответствующий байт которого указывается битовой маской. в IQ, что прогноз не был сделан (что означает, что прогноз не был принят по умолчанию) и случайно статически прогнозирует его как взятое вместо этого и изменяет префикс, что приведет к тому, что BAC обнаружит, что неправильный путь был выбран (это известно как IQ форсирует BACLEAR, как теперь происходит в BAC:
BACLEAR_FORCE_IQ). BAC в декодерах также гарантирует, что относительные ветви и прямые ветви имеют правильное предсказание цели ветвления после вычисления абсолютного адреса из самой инструкции и сравнения его с ним, если нет, выдается BACLEAR. Для относительных переходов статическое прогнозирование в BAC использует знаковый бит смещения перехода для статического прогнозирования выполненного / невыполненного, если прогноз не был сделан, но также отменяет все прогнозы возврата, которые были приняты, если BTB не поддерживает типы возвращаемых записей (это не на P6 и не делает прогнозов, вместо этого BAC использует механизм RSB BPU, и это первая точка в конвейере, где подтверждается инструкция возврата) и отменяет все косвенные предсказания ветвления регистров, принятые на P6 (потому что нет IBTB), поскольку он использует статистику, согласно которой выполняется больше ветвей, чем нет.BAC вычисляет и вставляет абсолютную цель из относительной цели в uop и вставляет дельту IP в uop и вставляет пропуск IP (NLIP) в BIT BPU и маркирует uop записью BIT, а косвенное целевое предсказание вставляется в моп вместо известной цели, если цель не известна. Эти поля в uop используются распределителем для распределения в RS/ROB позже. BAC также информирует BTB о любых ложных предсказаниях (инструкциях без ветвления), которые требуют освобождения своих записей от BTB. В декодерах инструкции ветвления обнаруживаются на ранней стадии логики (когда префиксы декодируются и инструкция проверяется, чтобы увидеть, может ли она быть декодирована декодером), и доступ к BAC осуществляется параллельно с остальными. BAC, вставляющий известную или иным образом предсказанную цель в uop, известен как преобразование auop в дуоп. Прогноз кодируется в код операции uop.
BAC, вероятно, дает команду BTB спекулятивно обновить свой BTB для IP-адреса обнаруженной инструкции перехода. Если цель теперь известна, и для нее не было сделано никаких прогнозов (то есть ее не было в кеше) - это все еще спекулятивно, поскольку, хотя цель ветвления известна наверняка, она все еще может быть на спекулятивном пути, поэтому помечены спекулятивным битом - теперь это немедленно обеспечит раннее управление, особенно для безусловных ветвей, которые сейчас входят в конвейер, но также и для условных, с пустой историей, поэтому прогноз не будет выполняться в следующий раз, вместо того, чтобы ждать до выхода из эксплуатации).
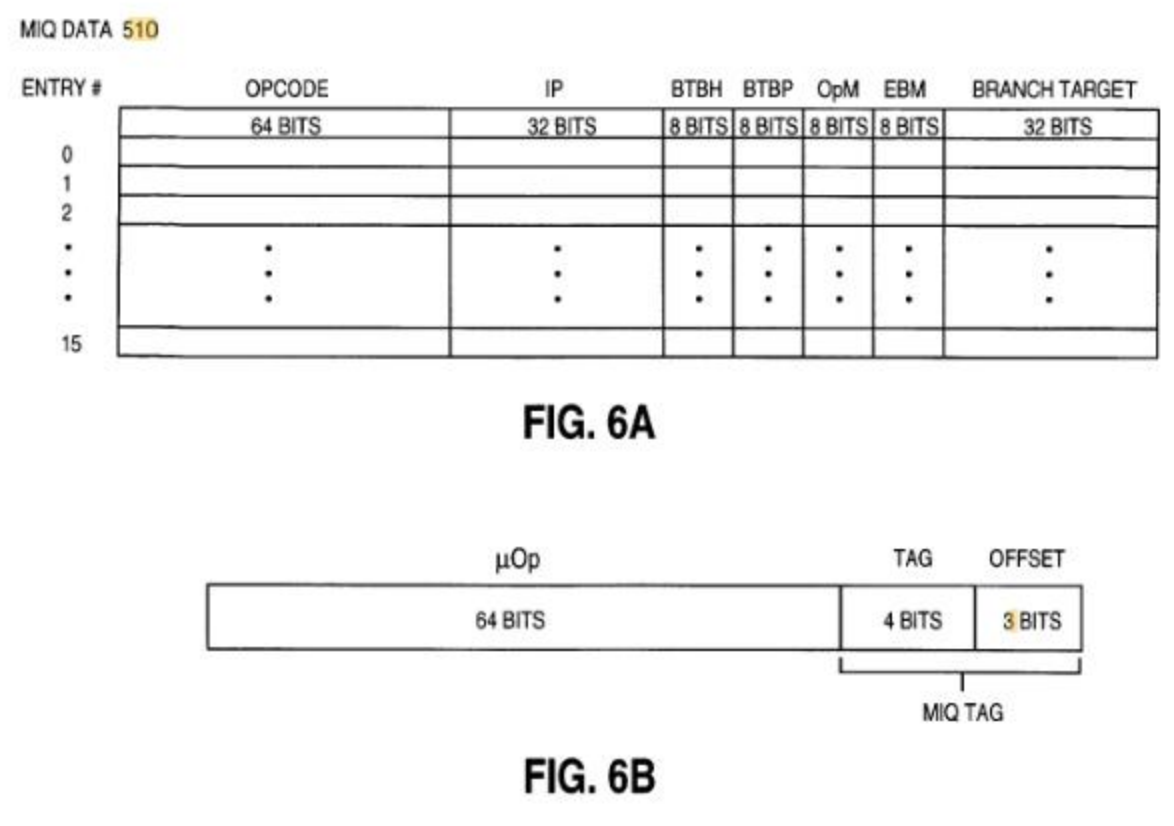
IQвыше содержит поле битовой маски для направлений предсказания ветвления (BTBP) и предсказаний ветвлений сделано / не предсказано (BTBH) (чтобы различать, какие из 0 не приняты, в отличие от того, что предсказание не сделано) для каждого из 8 байтов команд в IQ строка, а также цель инструкции ветвления, то есть может быть только одна ветвь на строку IQ, и она завершает строку. Эти биты предсказания и целевые предсказания вставляются BPU в ILD. IQ представляет собой непрерывный блок байтов команд, а ILD заполняет 8 битовых масок, которые идентифицируют первый байт кода операции (OpM) и байт конца команды (EBM) каждой макрокоманды, поскольку она завершает циклические байты в IQ. Промежутки между этими маркерами являются неявно префиксными байтами для следующей инструкции. Я'Я считаю, что IQ спроектирован таким образом, что мопы, которые он выдает в IDQ / ROB, редко опережают IQ, так что указатель заголовка в IQ начинает перезаписывать макрокоманды, все еще помеченные в IDQ, ожидающие распределения, и когда это происходит, задержка, поэтому теги IDQ относятся к IQ, к которому имеет доступ распределитель. Я думаю, что ROB также использует этот тег uop. IQ на SnB, если 16 байт * 40 записей содержат 40 макросов в худшем случае, 320 в среднем случае, 640 в лучшем случае. Количество мопов, производимых этими производителями, будет намного больше, поэтому они редко будут опережать их, и когда это произойдет, я думаю, он остановится при декодировании до тех пор, пока не исчезнут другие инструкции. Конечный указатель содержит тег, недавно выделенный ILD, указатель заголовка содержит следующую инструкцию макроинструкции, ожидающую выхода,а указатель чтения - это текущий тег, который будет использоваться декодерами (который перемещается к указателю хвоста). Хотя это становится трудным теперь, когда некоторые, если не большинство uop в пути поступают из кэша uop, начиная с SnB. IQ может быть разрешено опередить серверную часть в том случае, если мопы не помечены записями IQ (а поля в IQ вместо этого вставляются в мопы напрямую), и это будет обнаружено, и конвейер будет просто восстановлен от начало.и это будет обнаружено, и конвейер будет повторно обработан с самого начала.и это будет обнаружено, и конвейер будет повторно обработан с самого начала.
Когда распределитель выделяет физический адресат (Pdst) для микрооперации ветвления в ROB, он предоставляет BPU номер записи Pdst. BPU вставляет это в правильную запись BIT, назначенную BAC (которая, вероятно, помечена для uop). Распределитель также извлекает поля из uop и распределяет данные в RS без BIT, как показано ниже.
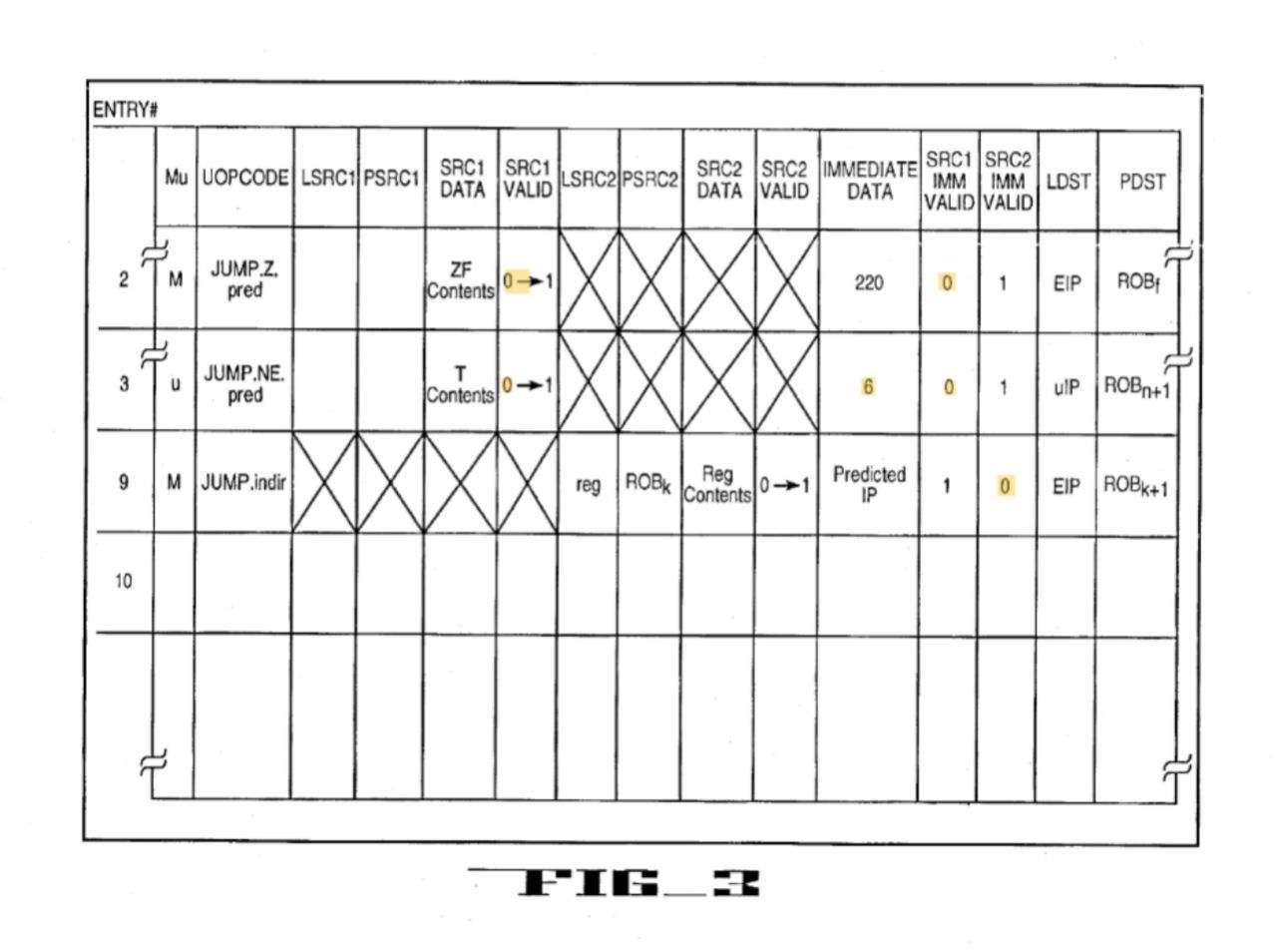
RS содержит поле, которое указывает, является ли инструкция uop MSROM или обычным uop, которое заполняет распределитель. Распределитель также вставляет подтвержденную абсолютную цель или предсказанную абсолютную цель в непосредственные данные и в качестве источника переименовывает регистр флагов ( или просто бит флага), а в случае косвенного перехода существует также переименованный регистр, который содержит адрес как еще один источник. Pdst в схеме PRF будет записью ROB, которая в качестве Pdst будет регистром исключения макро-RIP или микро-IP. JEU записывает цель или провал в этот регистр (может и не понадобиться, если прогноз верен).
Когда станция резервирования отправляет микрооперацию ветвления в модуль выполнения перехода, расположенный в целочисленном исполнительном модуле, станция резервирования сообщает BTB о записи Pdst для соответствующей микрооперации ветвления. В ответ BTB получает доступ к соответствующей записи для инструкции ветвления в BIT, и падение через IP (NLIP) считывается, уменьшается на дельту IP в RS и декодируется, чтобы указать на набор, который будет обновлено / выделено.
Результат переименованного источника Pdst регистра флагов для определения того, взято ли ветвление или нет, затем сравнивается с предсказанием в коде операции в планировщике, и, кроме того, если ветвление является косвенным, предсказанная цель в BIT сравнивается с адрес в исходном Pdst (который был рассчитан и стал доступным в RS до того, как он был запланирован и отправлен), и теперь известно, был ли сделан правильный прогноз и верна ли цель.
JEU передает код исключения в ROB и очищает конвейер (JEClear - который очищает весь конвейер перед этапом выделения, а также останавливает распределитель) и перенаправляет следующую логику IP в начале конвейера, используя сквозной ( в BIT) / целевой IP-адрес (а также микросеквенсор, если это неверное предсказание микробранша; RIP, направленный на начало конвейера, будет одинаковым на протяжении всей процедуры MSROM). Спекулятивные записи удаляются, а истинные BHR копируются в спекулятивные BHR. В случае, если в схеме PRF присутствует BOB, BOB делает снимки состояния RAT для каждой инструкции ветвления и при ошибочном прогнозе.JEU откатывает состояние RAT к этому моментальному снимку, и распределитель может немедленно приступить к работе (что особенно полезно для неправильного прогнозирования микробранч, поскольку он находится ближе к распределителю, поэтому пузырь не будет так хорошо скрыт конвейером), вместо того, чтобы останавливать распределитель и необходимость дождаться выхода из эксплуатации, чтобы стало известно состояние вывода RAT, и использовать его для восстановления RAT, а затем очистить ROB (ROClear, который удаляет распределитель). С помощью BOB распределитель может начать выдавать новые инструкции, в то время как устаревшие мопы продолжают выполняться, а когда ветвь готова к удалению, ROClear очищает только мопы между удаленным ошибочным предсказанием и новыми мопами. Если это муп MSROM, потому что он мог быть завершен, начало конвейера все равно нужно снова перенаправить на муп MSROM,но на этот раз он начнется с перенаправленного микропроцессора (это случай со встроенными инструкциями (и он может воспроизвести его из IQ). Если в исключении MSROM происходит неверное предсказание, то нет необходимости повторно направлять конвейер, просто перенаправляет его напрямую, потому что он взял на себя проблему IDQ до конца процедуры - проблема, возможно, уже закончилась для встроенных проблем.
ROClear в ответ на вектор исключения ветвления в ROB фактически происходит на втором этапе вывода из эксплуатации RET2 (который на самом деле является 3-м или 3-м этапом типичного конвейера вывода из эксплуатации), когда мопы выводятся на пенсию. Макрокоманда удаляется, а исключения только запускаются, а RIP макрокоманды обновляется (с новой целью или увеличением на дельту IP в ROB) только тогда, когда маркер UOP EOM (конец макрокоманды) удаляется, даже если в него записывает не EOM инструкция, он не записывается в RRF сразу же, в отличие от других регистров - в любом случае, uop перехода, вероятно, будет последним uop в типичной макроинструкции перехода, обрабатываемой декодерами. Если это микроответ в процедуре MSROM, он не будет обновлять BTB; он обновляет uIP при выходе из эксплуатации, а RIP не обновляется до конца процедуры.
Если во время выполнения макроса MSROM возникает общее непредсказуемое исключение (то есть, для которого требуется обработчик), то после обработки микропрограмма, вызвавшая исключение, восстанавливается обработчиком в регистре uIP (в случае, если это передается в обработчик при его вызове), а также текущий RIP макрокоманды, которая инициировала исключение, и когда обработка исключения заканчивается, выборка команды возобновляется на этом RIP+uIP: макрокоманда повторно загружается и повторяется в MSROM , который начинается с переданного ему uIP. Запись RRF (или обновление RAT вывода на пенсию в схеме PRF) для предыдущих мопов в сложной макрокоманде, не относящейся к MSROM, может произойти в цикле до того, как моп EOM удалится, что означает, что перезапуск может произойти и на определенном мупе внутри макроса как макрос MSROM, где MS направляет сложный кеш декодера / uop для выдачи последних uop (uIP - это значение от 0 до 3, которое, я думаю, ROB устанавливает в 0 для каждого EOM и увеличивается для каждой удаленной микропрограммы, так что не-MSROM могут быть адресованы сложные инструкции - для встроенных процедур MSROM он излучает uop, который сообщает ROB его собственный uIP) (архитектурный регистр RIP, который обновляется дельтой IP только тогда, когда uop EOM удаляется, все еще указывает на текущий макрос из-за того, что UOP EOM не удалось выйти из эксплуатации), что происходит только для исключений, но не для аппаратных прерываний, которые не могут прерывать процедуры MSROM или промежуточное удаление сложных инструкций (программные прерывания аналогичны и запускаются в EOM - обработчик прерывания MSROM выполняет макропереход в RIP обработчика программных прерываний после его завершения).
Чтение BTB и сравнение тегов происходит в RET1, в то время как блок ветвления записывает обратно результаты, а в RET2 теги в наборе сравниваются, и, если есть совпадение, вычисляется новая история BHR, если есть промах, запись должна быть размещена на этом IP-адресе с этой целью. Только после того, как uop удаляется по порядку, результат помещается в реальную историю, и алгоритм прогнозирования ветвлений используется для обновления таблицы шаблонов, где требуется обновление. Если ветвь требует выделения, политика замещения используется для определения средств выделения ветви. Если есть попадание, цель уже будет правильной для всех прямых и относительных ветвей, поэтому ее не нужно сравнивать в случае отсутствия IBTB. Спекулятивный бит теперь удаляется из записи, если он присутствует. Наконец, в следующем циклеветвь записывается в кэш BTB логикой управления записью BTB. Таблица шаблонов также обновляется при необходимости.
На Sandy Bridge выровненный фрагмент размером 32 байт сканируется BPU вместо 16 байт (таким образом, сканируются 2 соседних набора; все, кажется, предполагает, что каждый четырехканальный набор по-прежнему покрывает максимум 16 смежных байтов на SnB). В том же цикле он отправляется в кеш L1i и кеш uop. Если обнаружена взятая ветвь, конвейер направляется к ней, и новый фрагмент 32B сканируется от переадресованного IP-адреса до конца окна 32B, в котором он находится. Если нет взятой ветки, в следующем цикле он сканирует 2 смежных набора, начиная с границы 32B. Я бы подумал, что он сопровождает каждое предыдущее окно 32B с окном предсказания, как только предсказание приходит, так что блок выборки не извлекает избыточные 16-байтовые блоки, но также так, чтобы он правильно извлекал выровненные с первой макроинструкцией при повторном управлении конвейером при ошибочно спрогнозированная ветвь,или в случае выборки из-за попадания в кеш uop.
Если бы у P6 был кеш uop, конвейер выглядел бы примерно так:
- 1H: выберите IP
- 1L: декодирование набора BTB + декодирование набора кеша ( физический / виртуальный индекс) + поиск ITLB + декодирование набора кеша uop
- 2H: чтение из кеша + чтение BTB + чтение из кеша uop
- 2L: сравнение тегов кеша + сравнение тегов BTB + сравнение тегов uop; при попадании в кеш uop, остановка до тех пор, пока кеш uop не сработает, затем конвейер декодирования устаревшего канала синхронизации
- 3H: предсказать, если принято, промыть 3H,2L,2H,1L
- 3L, если принято, начать 1L с новым IP для декодирования нового набора и продолжить с текущего 16-байтового блока, для которого инструкция перехода находится в 4L
Я бы рискнул предположить, что кеш uop также перенаправляет BPU на макротаргет, когда встречается взятая uop ветвления (что будет одновременно с поздним сбросом, и косвенное прогнозирование цели может использоваться так же, как вычисленные цели in the uops), но до этого времени последовательные этапы поиска упаковываются в конвейер. Обычный поиск BTB/IBTB в настоящее время все еще продолжается, и он использует эти прогнозы, и ему требуется только прогноз цели от IBTB, потому что все цели были правильно рассчитаны. Вероятно, он игнорирует прогнозы на фиктивных ветвях и прогнозирует не все непредсказания, в противном случае косвенные цели и прогнозы T/NT вставляются в BIT или сам uop. Я бы предположил, что кеш uop создает записи BIT и обновляет прогнозы в BTB,чтобы гарантировать, что uop cache и MITE (legacy decode) uops обновляют историю в правильном последовательном порядке.