Как получить важность функции в xgboost?
Я использую xgboost для построения модели и пытаюсь выяснить важность каждой функции, используя get_fscore(), но это возвращает {}
и мой код поезда:
dtrain = xgb.DMatrix(X, label=Y)
watchlist = [(dtrain, 'train')]
param = {'max_depth': 6, 'learning_rate': 0.03}
num_round = 200
bst = xgb.train(param, dtrain, num_round, watchlist)
Так есть ли ошибка в моем поезде? Как получить важность функции в xgboost?
13 ответов
В вашем коде вы можете получить важность для каждой функции в форме dict:
bst.get_score(importance_type='gain')
>>{'ftr_col1': 77.21064539577829,
'ftr_col2': 10.28690566363971,
'ftr_col3': 24.225014841466294,
'ftr_col4': 11.234086283060112}
Объяснение: Метод get_score () API train () определен следующим образом:
get_score (fmap = '', priority_type = 'weight')
- fmap (str (необязательно)) - имя файла карты объектов.
- importance_type
- 'weight' - количество раз, которое функция используется для разделения данных по всем деревьям.
- 'усиление' - среднее усиление по всем разделениям, в которых используется функция.
- 'cover' - среднее покрытие по всем разделениям, в которых используется функция.
- 'total_gain' - общее усиление по всем разделениям, в которых используется функция.
- 'total_cover' - общее покрытие по всем разделениям, в которых используется функция.
https://xgboost.readthedocs.io/en/latest/python/python_api.html
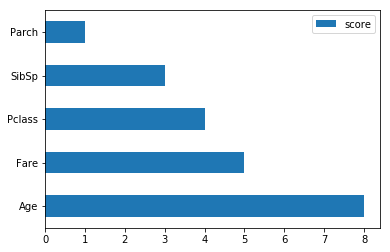
Получить таблицу, содержащую оценки и имена объектов, а затем построить его.
feature_important = model.get_score(importance_type='weight')
keys = list(feature_important.keys())
values = list(feature_important.values())
data = pd.DataFrame(data=values, index=keys, columns=["score"]).sort_values(by = "score", ascending=False)
data.plot(kind='barh')
Например:
Используя sklearn API и XGBoost 0.81:
clf.get_booster().get_score(importance_type="gain")
или же
regr.get_booster().get_score(importance_type="gain")
Сначала соберите модель из XGboost
from xgboost import XGBClassifier, plot_importance
model = XGBClassifier()
model.fit(train, label)
это приведет к массиву. Таким образом, мы можем отсортировать по убыванию
sorted_idx = np.argsort(model.feature_importances_)[::-1]
Затем пришло время распечатать все отсортированные значения и названия столбцов вместе в виде списков (я предполагаю, что данные загружены с помощью Pandas)
for index in sorted_idx:
print([train.columns[index], model.feature_importances_[index]])
Кроме того, мы можем построить график с помощью встроенной функции XGboost.
plot_importance(model, max_num_features = 15)
pyplot.show()
использование max_num_features в plot_importance ограничить количество функций, если вы хотите.
Согласно этому сообщению, существует 3 разных способа узнать важность функции от Xgboost:
- использовать встроенную важность функции,
- использовать важность на основе перестановок,
- используйте важность на основе формы.
Важность встроенной функции
Пример кода:
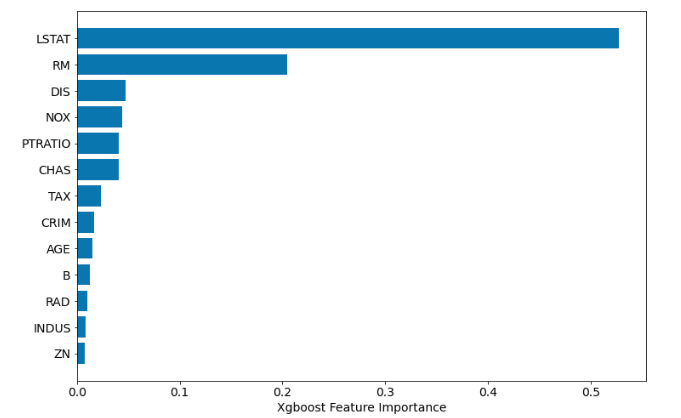
xgb = XGBRegressor(n_estimators=100)
xgb.fit(X_train, y_train)
sorted_idx = xgb.feature_importances_.argsort()
plt.barh(boston.feature_names[sorted_idx], xgb.feature_importances_[sorted_idx])
plt.xlabel("Xgboost Feature Importance")
Помните, какой тип важности функции вы используете. Есть несколько типов важности, см. Документацию. Вscikit-learn вроде API Xgboost возвращается gain важность пока get_fscore возвращается weight тип.
Важность на основе перестановок
perm_importance = permutation_importance(xgb, X_test, y_test)
sorted_idx = perm_importance.importances_mean.argsort()
plt.barh(boston.feature_names[sorted_idx], perm_importance.importances_mean[sorted_idx])
plt.xlabel("Permutation Importance")
Это мой предпочтительный способ вычислить важность. Однако он может выйти из строя в случае сильно коллинеарных функций, поэтому будьте осторожны! Он используетpermutation_importance из scikit-learn.
Важность на основе SHAP
explainer = shap.TreeExplainer(xgb)
shap_values = explainer.shap_values(X_test)
shap.summary_plot(shap_values, X_test, plot_type="bar")
Чтобы использовать приведенный выше код, вам необходимо иметь shap пакет установлен.
Я проводил анализ примера на данных Бостона (регрессия цен на жилье из scikit-learn). Ниже 3 важности функции:
Встроенная важность
Важность на основе перестановок
Важность SHAP
Все графики для одной модели! Как видите, есть разница в результатах. Я предпочитаю важность на основе перестановок, потому что у меня есть четкое представление о том, какая функция влияет на производительность модели (если нет высокой коллинеарности).
Для важности функции Попробуйте это:
Классификация:
pd.DataFrame(bst.get_fscore().items(), columns=['feature','importance']).sort_values('importance', ascending=False)
Регресс:
xgb.plot_importance(bst)
Для тех, кто сталкивается с этой проблемой при использовании xgb.XGBRegressor() Обходной путь, который я использую, чтобы сохранить данные в pandas.DataFrame() или же numpy.array() и не конвертировать данные в dmatrix(), Кроме того, я должен был убедиться, что gamma параметр не указан для XGBRegressor.
fit = alg.fit(dtrain[ft_cols].values, dtrain['y'].values)
ft_weights = pd.DataFrame(fit.feature_importances_, columns=['weights'], index=ft_cols)
После примерки регрессора fit.feature_importances_ возвращает массив весов, который, как я полагаю, находится в том же порядке, что и столбцы объектов в кадре данных pandas.
Моя текущая настройка - Ubuntu 16.04, Anaconda distro, python 3.6, xgboost 0.6 и sklearn 18.1.
Я не знаю, как получить значения, конечно, но есть хороший способ показать важность функций:
model = xgb.train(params, d_train, 1000, watchlist)
fig, ax = plt.subplots(figsize=(12,18))
xgb.plot_importance(model, max_num_features=50, height=0.8, ax=ax)
plt.show()
Попробуй это
fscore = clf.best_estimator_.booster().get_fscore()
Если вы используете XGBRegressor, попробуйте: model.get_booster().get_score().
Это возвращает результаты, которые вы можете непосредственно визуализировать через plot_importance команда
Ничего из вышеперечисленного у меня не сработало, это был тот код, который я выбрал для сортировки функций по важности.
from collections import Counter
Counter({k: v for k, v in sorted(model.get_fscore().items(), key=lambda item: item[1], reverse = True)}).most_common
просто замените модель названием вашей модели, и все будет там. Конечно, я делаю одно и то же дважды, нет необходимости заказывать диктант перед переходом к счетчику, но я полагаю, что не помешает оставить его там на случай, если кто-то ненавидит счетчики.
print(model.feature_importances_)
plt.bar(range(len(model.feature_importances_)), model.feature_importances_)
см. ссылку на публикацию kaggle для получения информации о важности функций различных типов с использованием XGBoost https://www.kaggle.com/discussion/237792