Чтение и запись в MYSQL в AWS Glue
введите описание изображения здесь. Я могу подключиться к MYSQL во время выполнения моего кода Pyspark локально в блокноте juypter, но тот же код я получаю сообщение об ошибке связи в AWS Glue при выполнении кода. Я добавил MySQL jar в файлы jar, необходимые при создании задания в AWS Glue.
Чтение с MYSQL
dataframe_mysql = sqlContext.read.format ("jdbc"). option ("url", "jdbc: mysql: // localhost / read").option ("драйвер", "com.mysql.jdbc.Driver").option("dbtable", "student").option("user", "root").option("password", "root").load()
Запись в MYSQL
df = sc.parallelize ([[25, 'Prem'],
[20, 'Kate'],
[20, 'Kate'],
[40, 'Cheng']]).toDF(["Depy_id","Dept_name"])
df.write.format ('JDBC'). Варианты (
url='jdbc:mysql://localhost/test',
driver='com.mysql.jdbc.Driver',
dbtable='dept',
user='root',
password='root').mode('overwrite').save()
2 ответа
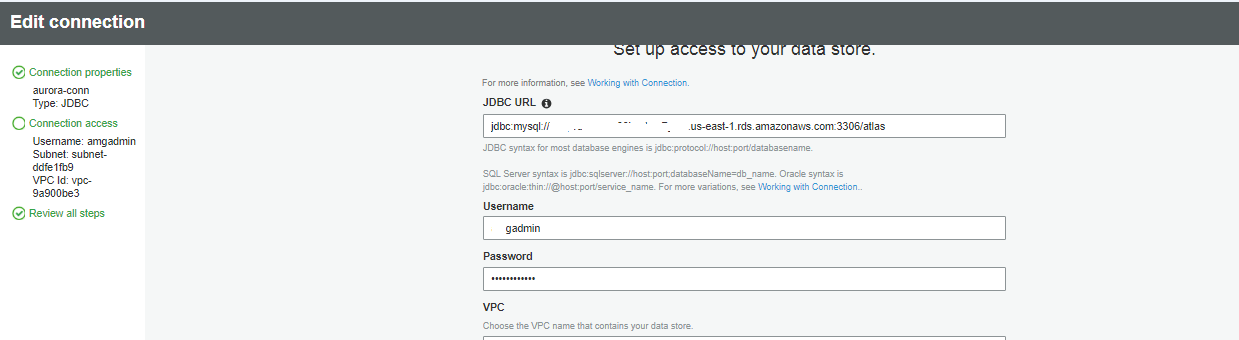
Да , это правда, я могу подключить его, как указано выше, просто добавив подключение к работе, а также изменив локальный хост на соответствующий
Обратите внимание, что вы должны предоставить действительный URL базы данных, а не localhost. Я полагаю, что ваш ноутбук Jupyter был запущен локально на ноутбуке, в той же локальной среде, где работает и MySQL.
AWS Glue работает в среде AWS и за сценой запускает количество экземпляров EC2 в зависимости от конфигурации DPU. Если ваш URL-адрес настроен как LOCALHOST, то экземпляр EC2, на котором выполняется код pyspark, будет искать базу данных mysql на том же узле.
Убедитесь, что у вас есть действительный общедоступный IP-адрес для базы данных mysql, и попробуйте настроить соединение в AWS Glue, как это предложено bdcloud, и повторите попытку. Если вы не хотите создавать соединение, вы можете жестко закодировать параметры соединения в коде и повторить попытку. Если вы не можете получить публичный IP-адрес для установленной базы данных mysql, возможно, вы можете попробовать настроить RDS Mysql на AWS и использовать его для тестирования.
Пример кода:
conn = mysql.connector.connect(host=url, user=uname, password=pwd, database=dbase)
cur = conn.cursor()
insertQry = "INSERT INTO emp (id, emp_name, dept, designation, address1, city, state, active_start_date, is_active) SELECT (SELECT coalesce(MAX(ID),0) + 1 FROM atlas.emp) id, tmp.emp_name, tmp.dept, tmp.designation, tmp.address1, tmp.city, tmp.state, tmp.active_start_date, tmp.is_active from EMP_STG tmp ON DUPLICATE KEY UPDATE dept=tmp.dept, designation=tmp.designation, address1=tmp.address1, city=tmp.city, state=tmp.state, active_start_date=tmp.active_start_date, is_active =tmp.is_active ;"
n = cur.execute(insertQry)
print (" CURSOR status :", n)
См. Раздел "Клеевые соединения AWS":