R - нечеткое объединение только для ближайшего целого числа
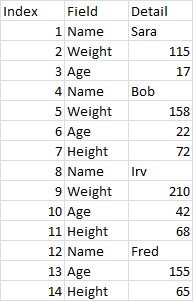
Предположим, у меня есть этот набор данных для начала, в этой глупой компоновке:
originalDF <- data.frame(
Index = 1:14,
Field = c("Name", "Weight", "Age", "Name", "Weight", "Age", "Height", "Name", "Weight", "Age", "Height", "Name", "Age", "Height"),
Value = c("Sara", "115", "17", "Bob", "158", "22", "72", "Irv", "210", "42", "68", "Fred", "155", "65")
)
Я хочу, чтобы это выглядело так:
По сути, я хочу сопоставить строки "Вес", "Возраст" и "Рост" со строкой "Имя" над ним. Разделить данные легко с помощью dplyr:
namesDF <- originalDF %>%
filter(Field == "Name")
detailsDF <- originalDF %>%
filter(!Field == "Name")
Отсюда использование индекса (номер строки) кажется наилучшим способом, то есть сопоставление каждой строки в detailsDF с записью в namesDF у которого есть самый близкий Индекс, не переходя. Я использовал fuzzyjoin пакет и присоединился к ним с
fuzzy_left_join(detailsDF, namesDF, by = "Index", match_fun = list(`>`))
Этот вид работ, но он также объединяет каждую строку в detailsDF с КАЖДОЙ строкой в namesDF с меньшим индексным номером:
Я нашел решение, использующее расстояние до следующего индекса и таким образом отфильтровывая лишние строки, но я хочу избежать этого; фактический исходный файл будет содержать более 200 тыс. строк, а временный результирующий кадр данных с дополнительными строками будет слишком большим, чтобы поместиться в память. Я могу здесь что-нибудь сделать? Спасибо!
3 ответа
Я рекомендую подходить к нему по-другому, отслеживая самое последнее значение "Имя" в каждой точке. fill() из пакета tidyr полезно для этого.
library(dplyr)
library(tidyr)
originalDF %>%
mutate(Name = ifelse(Field == "Name", as.character(Value), NA)) %>%
fill(Name) %>%
filter(Field != "Name")
Выход:
Index Field Value Name
1 2 Weight 115 Sara
2 3 Age 17 Sara
3 5 Weight 158 Bob
4 6 Age 22 Bob
5 7 Height 72 Bob
6 9 Weight 210 Irv
7 10 Age 42 Irv
8 11 Height 68 Irv
9 13 Age 155 Fred
10 14 Height 65 Fred
Однако, если вы хотите использовать подход fuzzyjoin, вы можете достичь этого с group_by() а также slice() на ваш результат, где вы берете последний ряд для каждого значения Index.x,
fuzzy_left_join(detailsDF, namesDF, by = "Index", match_fun = list(`>`)) %>%
group_by(Index.x) %>%
slice(n()) %>%
ungroup()
Выход:
# A tibble: 10 x 6
Index.x Field.x Value.x Index.y Field.y Value.y
<int> <fct> <fct> <int> <fct> <fct>
1 2 Weight 115 1 Name Sara
2 3 Age 17 1 Name Sara
3 5 Weight 158 4 Name Bob
4 6 Age 22 4 Name Bob
5 7 Height 72 4 Name Bob
6 9 Weight 210 8 Name Irv
7 10 Age 42 8 Name Irv
8 11 Height 68 8 Name Irv
9 13 Age 155 12 Name Fred
10 14 Height 65 12 Name Fred
Ты можешь использовать
x = which(originalDF$Field == "Name")
originalDF$Name = rep(originalDF$Value[x], times = diff(c(x, NROW(originalDF)+1)))
NewDF = originalDF[originalDF$Field != 'Name', c(4,2,3)]
# Name Field Value
# 2 Sara Weight 115
# 3 Sara Age 17
# 5 Bob Weight 158
# 6 Bob Age 22
# 7 Bob Height 72
# 9 Irv Weight 210
# 10 Irv Age 42
# 11 Irv Height 68
# 13 Fred Age 155
# 14 Fred Height 65
Вы можете сгруппировать по cumsum(Field == "Name"), С dplyr...
library(dplyr)
originalDF %>%
group_by(Name = Value[Field == "Name"][cumsum(Field == "Name")]) %>%
slice(-1) %>% select(c("Name", "Field", "Value"))
# A tibble: 10 x 3
# Groups: Name [4]
Name Field Value
<fct> <fct> <fct>
1 Bob Weight 158
2 Bob Age 22
3 Bob Height 72
4 Fred Age 155
5 Fred Height 65
6 Irv Weight 210
7 Irv Age 42
8 Irv Height 68
9 Sara Weight 115
10 Sara Age 17
С data.table...
library(data.table)
data.table(originalDF)[,
.SD[-1],
by=.(Name = Value[Field == "Name"][cumsum(Field == "Name")]), .SDcols=c("Field", "Value")]