Работа наследования в Дженкинс рабочих мест
Как вы справляетесь с отображением заданий Jenkins в процессе сборки и можете ли вы создавать каскадные конфигурации на основе наследования?
Для каждой конкретной сборки у меня будет как минимум три задания (стандартная непрерывная интеграция / ночная проверка, сканирование безопасности, покрытие), а затем несколько последующих заданий тестирования интеграции. Плагин среза конфигурации обрабатывает некоторые аспекты кросс-заданий, но каждое задание по-прежнему в значительной степени является отдельным объектом, не связанным с другими заданиями в своей группе.
Я недавно видел QuickBuild, и у него есть наследование заданий, где родительские задания могут определять стандартную группу шагов, а его дочерние элементы могут переопределять и специализироваться. С Дженкинсом у меня есть копии рабочих мест, и это нормально, пока мне не нужно что-то менять. С QuickBuild отношения между рабочими местами позволяют мне распространять свои изменения без особых усилий.
Я пытался выяснить, как справиться с этим в Дженкинс. Я мог бы использовать параметризованный плагин триггера сборки, чтобы задания могли вызывать других и переопределять аспекты. Затем я собираю данные от вызываемых заданий до вызывающего абонента. Я подозреваю, что столкнусь с рядом проблем, где есть аспекты, которые я не могу переопределить, которые заставят меня реализовать функциональность Jenkins в моем собственном сценарии, что сделает Jenkins менее полезным.
Как вы справляетесь со сложностями в работе по сборке в Дженкинс? Вы слышали о каких-либо серьезных проблемах с QuickBuild?
4 ответа
Я хотел бы указать вам на выпуск плагина, который моя команда разработала и только недавно опубликовала под открытым исходным кодом. Он реализует полное "Наследование между заданиями".
Здесь для дальнейших ссылок, которые могут помочь вам:
Плагин EZ Templates позволяет использовать любую вакансию в качестве шаблона для других вакансий. Это действительно круто. Все, что вам нужно, это установить базовое задание в качестве шаблона:
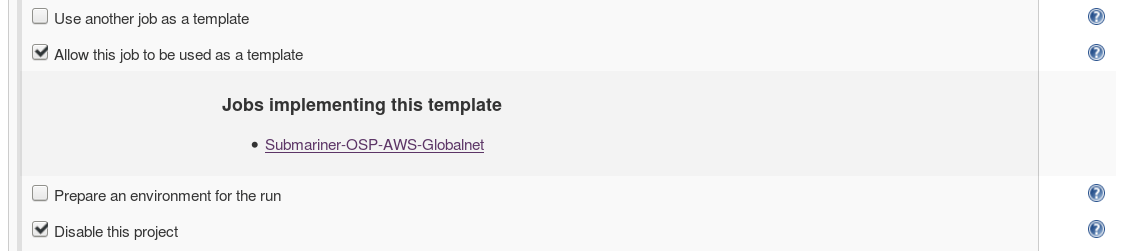
* Обычно вы также отключаете базовое задание (например, "абстрактный класс").
Затем создайте новое задание, настройте его на использование базового шаблона задания и сохраните: 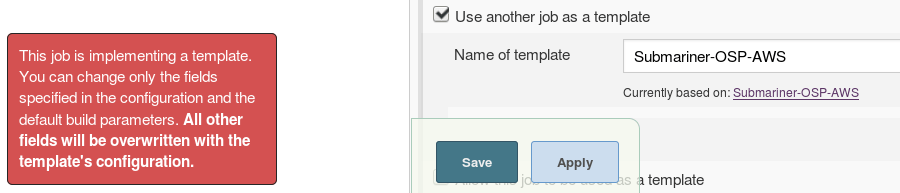
Теперь отредактируйте новое задание - оно будет включать все! (и вы можете переопределить существующие конфигурации).
Примечание. Существует еще один плагин Template Project для шаблонов конфигурации, но он не обновлялся недавно (последняя фиксация в 2016 году).
У меня была почти такая же проблема. У нас есть набор заданий, которые должны быть запущены для нашей магистрали, а также как минимум две ветви. Ветви представляют наши версии, и каждые несколько месяцев создается новая ветка. Создание новых рабочих мест вручную для этого не является решением, поэтому я проверил некоторые возможности.
Одна возможность - использовать плагин шаблона. Это позволяет вам создать иерархию рабочих мест. Он обеспечивает наследование для строителей, издателей и настроек SCM. Может работать для некоторых, для меня этого было недостаточно.
Вторым, что я проверил, был Ant Script для клонирования заданий и его брат Bash Script. Это действительно здорово. Идея состоит в том, чтобы заставить скрипт создать новое задание, скопировать все настройки из задания шаблона, вносить изменения по мере необходимости. Поскольку это сценарий, он очень гибкий, и с этим можно многое сделать. Единственным недостатком является то, что это не приведет к реальной иерархии, поэтому изменения в шаблонном задании не отразятся на уже клонированных заданиях, а только на заданиях, которые будут созданы в будущем.
Если посмотреть на недостатки и достоинства этих двух решений, комбинация обоих может работать лучше всего. Вы создаете шаблонный проект с некоторыми основными настройками, которые будут действительны для всех заданий, а затем используете сценарий bash или ant для создания заданий в зависимости от этого шаблона.
Надеюсь, это поможет.
Меня спросили, каким было наше окончательное решение проблемы... После многих месяцев борьбы с нашей системой закупок мы потратили около 4000 долларов США на Quickbuild. Примерно через 2-3 месяца у нас была система шаблонной сборки, и мы были очень довольны ею. До того, как я покинул компанию, в системе было несколько групп продуктов, и мы также автоматизировали процесс выпуска.
Quickbuild был отличным продуктом. Это должно быть в классе за 40 000 $, но это оценено намного меньше. Хотя я уверен, что Дженкинс мог бы сделать это, это было бы чем-то вроде клочья, тогда как Quickbuild включил эту функциональность. Я реализовывал сложные способы поведения над продуктами раньше (например, отслеживание слияния в SVN 1.0) и сожалел об этом. Quickbuild был по разумной цене и обеспечил прочную основу для наших систем сборки и тестирования.
В настоящее время я работаю в фирме, использующей Bamboo, и надеюсь, что ее новая функциональная ветка обеспечит большую часть возможностей Quickbuild.
Учитывая, что цель - СУХАЯ (не повторяйтесь), я сейчас предпочитаю этот подход:
- Используйте Дженкинс совместно библиотеку с блоком Дженкинс трубопровода для поддержки TDD
- Используйте образы докеров, используя Groovy/python или любой другой язык, который вам нравится, для выполнения сложных действий, требующих apis и т. Д.
- Сохраняйте фактический конвейер заданий очень спартанским (в основном, только для получения параметров сборки и передачи их функциям в общей библиотеке, которые могут использовать образы докеров для выполнения работы.
Это действительно хорошо работает и устраняет проблемы СУХОЙ при сложных заданиях сборки.
Пример кода Docker для общего конвейера - vars / releasePipeline.groovy
/**
* Run image
* @param closure to run within image
* @return result from execution
*/
def runRelengPipelineEphemeralDocker(closure) {
def result
artifactory.withArtifactoryEnvAuth {
docker.withRegistry("https://${getDockerRegistry()}", 'docker-creds-id') {
docker.image(getReleasePipelineImage()).inside {
result = closure()
}
}
}
return result
}
Пример использования
библиотека 'my-shared-jenkins-library'
releasePipeline.runRelengPipelineEphemeralDocker {
println "Running ${pythonScript}"
def command = "${pythonInterpreter} -u ${pythonScript} --cluster=${options.clusterName}"
sh command
}
Мы используем quickbuild, и кажется, что он отлично работает для большинства вещей. Я даже смог использовать их API для написания пользовательских плагинов. Одной из областей, где не хватает быстрой сборки, является интеграция с гидролокатором. У команды гидролокатора есть плагин Jenkins, а не плагин для быстрой сборки.