MDP & Reinforcement Learning - Сравнение сходимости алгоритмов VI, PI и QLearning
Я реализовал алгоритмы VI (Value Iteration), PI (Policy Iteration) и QLearning с использованием Python. После сравнения результатов я кое-что заметил. Алгоритмы VI и PI сходятся к одним и тем же утилитам и политикам. С одинаковыми параметрами алгоритм QLearning сходится к разным утилитам, но с одинаковыми политиками с алгоритмами VI и PI. Это что-то нормальное? Я прочитал много статей и книг о MDP и RL, но не смог найти ничего, что сообщало бы, должны ли утилиты алгоритмов VI-PI сходиться к тем же утилитам с QLearning или нет.
Следующая информация о моем мире сетки и результатах.
МОЙ СЕТКИЙ МИР
- Состояния => {s0, s1,..., s10}
- Действия => {a0, a1, a2, a3} где: a0 = вверх, a1 = вправо, a2 = вниз, a3 = слева для всех состояний
- Есть 4 состояния терминала, которые имеют награды +1, +1, -10, +10.
- Начальное состояние s6
- Вероятность перехода действия равна P, и (1 - p) / 2 для перехода влево или вправо от этого действия. (Например: если P = 0,8, когда агент пытается подняться вверх, агент с вероятностью 80% поднимется вверх, а агент с вероятностью 10% уйдет вправо и на 10% влево.)
РЕЗУЛЬТАТЫ
- Результаты алгоритма VI и PI с вознаграждением = -0,02, коэффициент дисконтирования = 0,8, вероятность = 0,8
- VI сходится после 50 итераций, PI сходится после 3 итераций
- Результаты алгоритма QLearning: вознаграждение = -0,02, коэффициент дисконтирования = 0,8, коэффициент обучения = 0,1, эпсилон (для исследования) = 0,1
- Результирующими утилитами на изображении результатов QLearning являются максимальные пары Q(s, a) каждого состояния.
qLearning_1million_10million_iterations_results.png
Кроме того, я также заметил, что когда QLearning выполняет 1 миллион итераций, состояния, которые находятся на одинаковом расстоянии от вознагражденного терминала +10, имеют те же утилиты. Похоже, что агенту все равно, будет ли он получать вознаграждение по пути, который близок к терминалу -10, или нет, в то время как агент заботится об этом на алгоритмах VI и PI. Это потому, что в QLearning мы не знаем вероятности перехода среды?
1 ответ
Если пространство состояний и действий конечно, как в вашей задаче, Q-learning алгоритм должен сходиться асимптотически к оптимальной полезности (иначе, Q-функция), когда число переходов приближается к бесконечности и при следующих условиях:
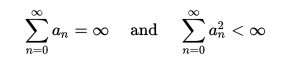 ,
,
где n это количество переходов и a это скорость обучения. Эти условия требуют обновления вашей скорости обучения в процессе обучения. Типичным выбором может быть использование a_n = 1/n, Однако на практике график скорости обучения может потребовать некоторой настройки в зависимости от проблемы.
С другой стороны, еще одно условие сходимости заключается в бесконечном обновлении всех пар состояние-действие (в асимметричном смысле). Этого можно достичь, просто поддерживая скорость разведки больше нуля.
Итак, в вашем случае вам нужно уменьшить скорость обучения.