Значения Q-Learning становятся слишком высокими
Недавно я попытался реализовать базовый алгоритм Q-Learning в Golang. Обратите внимание, что я новичок в Reinforcement Learning и AI в целом, поэтому ошибка вполне может быть моей.
Вот как я реализовал решение для среды m,n,k-game: в каждый момент времени tагент держит последнее состояние-действие (s, a) и приобретенная награда за это; агент выбирает ход a' основан на эпсилон-жадной политике и рассчитывает вознаграждение rзатем приступает к обновлению значения Q(s, a) На время t-1
func (agent *RLAgent) learn(reward float64) {
var mState = marshallState(agent.prevState, agent.id)
var oldVal = agent.values[mState]
agent.values[mState] = oldVal + (agent.LearningRate *
(agent.prevScore + (agent.DiscountFactor * reward) - oldVal))
}
Замечания:
agent.prevStateсохраняет предыдущее состояние сразу после выполнения действия и до того, как среда отреагирует (т.е. после того, как агент сделает свое движение и до того, как другой игрок сделает ход), я использую это вместо кортежа состояния-действия, но я не совсем уверен, это правильный подходagent.prevScoreдержит награду к предыдущему государству-действиюrewardАргумент представляет награду за состояние текущего шага (Qmax)
С agent.LearningRate = 0.2 а также agent.DiscountFactor = 0.8 агенту не удается достичь 100K эпизодов из-за переполнения значения действия состояния. Я использую Голанга float64 (Стандартная переменная с плавающей точкой двойной точности IEEE 754-1985), которая переполняется примерно ±1.80×10^308 и дает ±Infiniti, Это слишком большое значение, я бы сказал!
Вот состояние модели, обученной со скоростью обучения 0.02 и коэффициент дисконтирования 0.08 который прошел через 2M эпизодов (1M игр с собой):
Reinforcement learning model report
Iterations: 2000000
Learned states: 4973
Maximum value: 88781786878142287058992045692178302709335321375413536179603017129368394119653322992958428880260210391115335655910912645569618040471973513955473468092393367618971462560382976.000000
Minimum value: 0.000000
Функция вознаграждения возвращает:
- Агент выиграл: 1
- Агент потерян: -1
- Ничья: 0
- Игра продолжается: 0.5
Но вы можете видеть, что минимальное значение равно нулю, а максимальное значение слишком велико.
Возможно, стоит упомянуть, что с более простым методом обучения, который я нашел в скрипте Python, он работает отлично и чувствует себя на самом деле более умным! Когда я играю с ним, большую часть времени получается ничья (она даже выигрывает, если я играю небрежно), тогда как со стандартным методом Q-Learning я даже не могу позволить ему выиграть!
agent.values[mState] = oldVal + (agent.LearningRate * (reward - agent.prevScore))
Любые идеи о том, как это исправить? Является ли такое значение действия состояния нормальным в Q-Learning?!
Обновление: после прочтения ответа Пабло и небольшого, но важного изменения, которое Ник предоставил на этот вопрос, я понял, что проблема prevScore содержащий значение Q предыдущего шага (равно oldVal) вместо вознаграждения за предыдущий шаг (в данном примере -1, 0, 0,5 или 1).
После этого изменения агент теперь ведет себя нормально, а после 2М эпизодов состояние модели выглядит следующим образом:
Reinforcement learning model report
Iterations: 2000000
Learned states: 5477
Maximum value: 1.090465
Minimum value: -0.554718
и из 5 игр с агентом у меня было 2 победы (агент не узнал, что у меня два камня подряд) и 3 ничьи.
2 ответа
Если я хорошо понял, в вашем правиле обновления Q-Learning вы используете текущее вознаграждение и предыдущее вознаграждение. Тем не менее, правило Q-обучения использует только одну награду (x государства и u это действия): 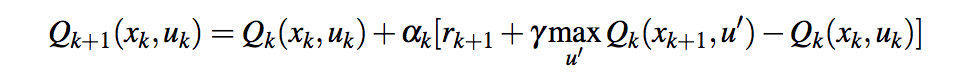
С другой стороны, вы предполагаете, что текущая награда такая же, как Qmax значение, которое не соответствует действительности. Так что, вероятно, вы неправильно понимаете алгоритм Q-обучения.
Функция вознаграждения, вероятно, является проблемой. Методы обучения подкреплению пытаются максимизировать ожидаемое общее вознаграждение; он получает положительное вознаграждение за каждый временной шаг в игре, поэтому оптимальная политика - играть как можно дольше! Значения q, которые определяют функцию значения (ожидаемое суммарное вознаграждение за выполнение действия в состоянии с оптимальным поведением), растут, потому что правильное ожидание не ограничено. Чтобы стимулировать выигрыш, вы должны получать отрицательное вознаграждение за каждый шаг (вроде как сказать агенту поторопиться и выиграть).
См. 3.2 Цели и награды в обучении подкреплению: Введение для более глубокого понимания цели и определения сигналов вознаграждения. Проблема, с которой вы сталкиваетесь, - это упражнение 3.5 в книге.