Можно ли давать подсказки в текстовом формате в google vision api?
Я пытаюсь обнаружить рукописные даты, выделенные на изображениях.
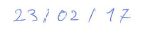
В api cloud vision есть способ дать подсказку о типе?
пример: единственным присутствующим текстом будет dd / mm / yy, d, m и y - цифры
Единственное, что я нашел, это языковые подсказки в документации.
Иногда я получаю результаты, которые включают такие буквы, как O вместо 0,
1 ответ
Нет способа дать подсказку о типе, но вы можете отфильтровать вывод, используя клиентские библиотеки. Я загрузил detect.py а также requirements.txt отсюда и модифицированный detect.py (в def Detect_text, после строки 283):
response = client.text_detection(image=image)
texts = response.text_annotations
#Import regular expressions
import re
print('Date:')
dateStr=texts[0].description
# Test case for letters replacement
#dateStr="Z3 OZ/l7"
#print(dateStr)
dateStr=dateStr.replace("O","0")
dateStr=dateStr.replace("Z","2")
dateStr=dateStr.replace("l","1")
dateList=re.split(' |;|,|/|\n',dateStr)
dd=dateList[0]
mm=dateList[1]
yy=dateList[2]
date=dd+'/'+mm+'/'+yy
print(date)
#for text in texts:
#print('\n"{}"'.format(text.description))
#print('Hello you!')
#vertices = (['({},{})'.format(vertex.x, vertex.y)
# for vertex in text.bounding_poly.vertices])
#print('bounds: {}'.format(','.join(vertices)))
# [END migration_text_detection]
# [END def_detect_text]
Потом я запустил detect.py внутри виртуальной среды с помощью этой командной строки:
python detect_dates.py text qAkiq.png
И я получил это:
23/02/17
Есть несколько букв, которые могут быть ошибочно приняты за числа, поэтому использование str.replace ("буква", "число") должно решить неправильную идентификацию. Я добавил наиболее распространенные случаи для этого примера.