Написание многопоточного цикла вручную - неоптимальная масштабируемость
Я написал это тестовое приложение: оно проходит через итерации от 0 до 9999, для каждого целого числа в диапазоне оно вычисляет некоторую бесполезную, но интенсивную для вычисления функцию. В результате программа выводит сумму значений функции. Чтобы запустить его в нескольких потоках, я использую InterlockedIncrement - если после увеличения номер итерации <10000, то поток обрабатывает эту итерацию, в противном случае он завершается.
Мне интересно, почему он не масштабируется так, как мне бы хотелось. С 5 потоками он работает 8 с 36 с одним потоком. Это дает ~4,5 масштабируемости. Во время моих экспериментов с OpenMP (с немного другими проблемами) я получал гораздо лучшую масштабируемость.
Исходный код показан ниже.
Я использую ОС Windows7 на рабочем столе Phenom II X6. Не знаю, какие другие параметры могут иметь значение.
Не могли бы вы помочь мне объяснить эту неоптимальную масштабируемость? Большое спасибо.
#include <boost/thread.hpp>
#include <boost/shared_ptr.hpp>
#include <boost/make_shared.hpp>
#include <vector>
#include <windows.h>
#include <iostream>
#include <cmath>
using namespace std;
using namespace boost;
struct sThreadData
{
sThreadData() : iterCount(0), value( 0.0 ) {}
unsigned iterCount;
double value;
};
volatile LONG g_globalCounter;
const LONG g_maxIter = 10000;
void ThreadProc( shared_ptr<sThreadData> data )
{
double threadValue = 0.0;
unsigned threadCount = 0;
while( true )
{
LONG iterIndex = InterlockedIncrement( &g_globalCounter );
if( iterIndex >= g_maxIter )
break;
++threadCount;
double value = iterIndex * 0.12345777;
for( unsigned i = 0; i < 100000; ++i )
value = sqrt( value * log(1.0 + value) );
threadValue += value;
}
data->value = threadValue;
data->iterCount = threadCount;
}
int main()
{
const unsigned threadCount = 1;
vector< shared_ptr<sThreadData> > threadData;
for( unsigned i = 0; i < threadCount; ++i )
threadData.push_back( make_shared<sThreadData>() );
g_globalCounter = 0;
DWORD t1 = GetTickCount();
vector< shared_ptr<thread> > threads;
for( unsigned i = 0; i < threadCount; ++i )
threads.push_back( make_shared<thread>( &ThreadProc, threadData[i] ) );
double sum = 0.0;
for( unsigned i = 0; i < threadData.size(); ++i )
{
threads[i]->join();
sum += threadData[i]->value;
}
DWORD t2 = GetTickCount();
cout << "T=" << static_cast<double>(t2 - t1) / 1000.0 << "s\n";
cout << "Sum= " << sum << "\n";
for( unsigned i = 0; i < threadData.size(); ++i )
cout << threadData[i]->iterCount << "\n";
return 0;
}
Редактировать: Прикрепление образца выходных данных этой тестовой программы (1 и 5 потоков):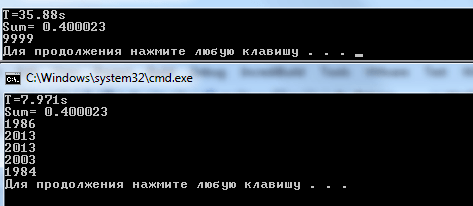
1 ответ
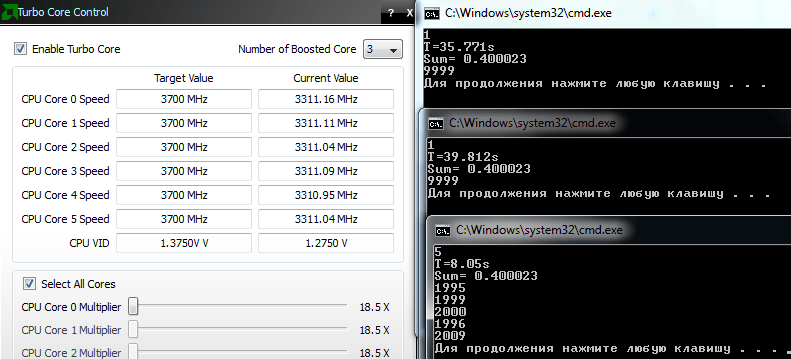
Получившиеся результаты можно объяснить тем, что мой процессор поддерживает технологию AMD Turbo Core.
В режиме Turbo CORE AMD Phenom™ II X6 1090T изменяет частоту с 3,2 ГГц на шести ядрах до 3,6 ГГц на трех ядрах
Таким образом, тактовые частоты не были одинаковыми в однопоточном и многопоточном режимах. Я привык играть с многопоточностью на процессорах, которые не поддерживают TurboCore. Ниже изображение, которое показывает результаты
- Окно утилиты AMD OverDrive (вещь, которая позволяет включать / выключать TurboCore)
- пробег с 1 потоками с включенным TurboCore
- пробег с 1 потоками с выключенным TurboCore
- пробег с 5 нитями
Большое спасибо людям, которые пытались помочь.