Циклы, knitr и xtable в rmarkdown для создания уникальных таблиц в нескольких отчетах
Я пересматриваю свой вопрос полностью. Я понял, что это было долго, и моя точка зрения терялась.
Вот что мне нужно сделать:
Создавайте автоматические отчеты для школ, которые содержат таблицы, в которых сравниваются их данные с округом, в котором находится школа, а также со всем штатом. Состояние - это весь набор данных.
Вот что я понимаю:
Как создать автоматизированный цикл, который просматривает данные и создает уникальный отчет в формате PDF для каждой школы. Этот пост был очень полезен при настройке структуры для генерации отчетов.
Вот что мне нужно помочь с:
Мне нужна таблица, содержащая следующие столбцы: Школа, Район, Штат. Мне также нужен первый столбец таблицы, в котором должна быть строка: Размер выборки, Среднее, Стандартное отклонение.
Я пытаюсь создать это в контексте цикла for, потому что мне нужна уникальная таблица в каждом уникальном PDF-файле, который создается. Если есть лучший подход, я хотел бы услышать об этом.
В любом случае, вот воспроизводимый пример, который я проверял. Я не продвинулся далеко в создании стола.
Любая помощь будет принята с благодарностью.
driver.r:
# Create dataset
set.seed(500)
School <- rep(seq(1:20), 2)
District <- rep(c(rep("East", 10), rep("West", 10)), 2)
Score <- rnorm(40, 100, 15)
Student.ID <- sample(1:1000,8,replace=T)
school.data <- data.frame(School, District, Score, Student.ID)
#prepare for multicore processing
require(parallel)
# generate the rmd files, one for each school in df
library(knitr)
mclapply(unique(school.data$School), function(x)
knit("F:/sample-auto/auto.Rmd",
output=paste('report_', x, '.Rmd', sep="")))
# generate PDFs from the rmd files, one for each school in df
mclapply(unique(school.data$School), function(x)
rmarkdown::render(paste0("F:/sample-auto/", paste0('report_', x, '.Rmd'))))
auto.Rmd:
---
title: "Automated Report Generation for Data"
author: "ME"
date: "February 5, 2015"
output:
pdf_document:
toc: true
number_sections: true
---
```{r, echo=FALSE}
library(xtable)
library(plyr)
df <- data.frame(school.data)
subgroup <- df[school.data$School == x,]
```
# Start of attempt
```{r results='asis', echo=FALSE}
for(school in unique(subgroup$School))
{
subgroup2 <- subgroup[subgroup$School == school,]
savename <- paste(x, school)
df2<- mean(subgroup2$Score, na.rm=TRUE)
df2 <- data.frame(df2)
print(xtable(df2))
}
```
Я также попытался заменить цикл на:
```{r results='asis', echo=FALSE}
df2 <- ddply(school.data, .(School), summarise, n = length(School), mean =
mean(Score), sd = sd(Score))
print(xtable(df2))
```
Это дает мне то, чего я не хочу, так как все школы получают данные по каждой школе, а не только по своей школе.
1 ответ
Если вы используете цикл для подмножества данных перед их передачей в файл.rmd, вам на самом деле не нужны plyr или ddply, чтобы выполнить разделение / применение / объединение для вас. Поскольку у вас много наблюдений, это может быть заметно накладными расходами.
Также, если вы создаете подгруппы перед запуском.rmd, вам также не нужен цикл внутри файла. Вам просто нужно сделать фрейм данных с нужной вам статистикой и использовать xtable
---
title: "Automated Report Generation for Data"
author: "ME"
date: "February 5, 2015"
output:
pdf_document:
toc: true
number_sections: true
---
```{r, echo=FALSE}
library(xtable)
library(plyr)
# Create dataset
set.seed(500)
School <- rep(seq(1:20), 2)
District <- rep(c(rep("East", 10), rep("West", 10)), 2)
Score <- rnorm(40, 100, 15)
Student.ID <- sample(1:1000,8,replace=T)
school.data <- data.frame(School, District, Score, Student.ID)
x <- unique(school.data$School)[1]
subgroup <- school.data[school.data$School == x, ]
```
# Start of attempt
```{r results='asis', echo=FALSE}
options(xtable.comment = FALSE)
## for one school, it is redundant to split based on school but works
## likewise, it is redundant to have a loop here to split based on school
## if you have already used a loop to create the subgroup data
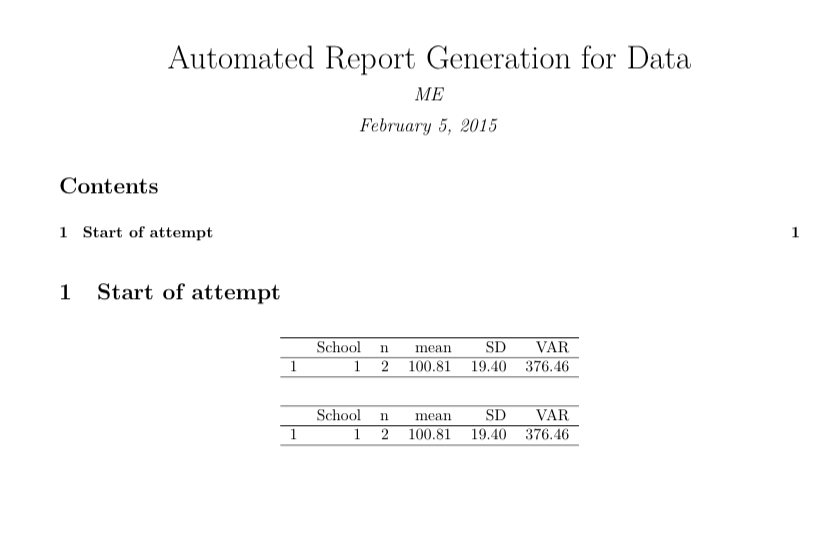
res <- ddply(subgroup, .(School), summarise,
n = length(School),
mean = mean(Score),
SD = sd(Score),
VAR = var(Score))
xtable(res)
## if you pass in the entire data frame you will get all schools
## then you can subset the one you want
res <- ddply(school.data, .(School), summarise,
n = length(School),
mean = mean(Score),
SD = sd(Score),
VAR = var(Score))
xtable(res[res$School %in% x, ])
```