Определить кодировку строки в C#
Есть ли способ определить кодировку строки в C#?
Скажем, у меня есть строка с именем файла, но я не знаю, закодирована ли она в Unicode UTF-16 или в кодировке системы по умолчанию, как мне узнать?
11 ответов
Проверьте Utf8Checker - это простой класс, который делает именно это в чистом управляемом коде. http://utf8checker.codeplex.com/
Примечание: как уже указывалось, "определение кодировки" имеет смысл только для байтовых потоков. Если у вас есть строка, она уже закодирована кем-то, кто уже знал или угадал кодировку, чтобы получить строку в первую очередь.
Код ниже имеет следующие особенности:
- Обнаружение или попытка обнаружения UTF-7, UTF-8/16/32 (bom, no bom, little & big endian)
- Возвращается к локальной кодовой странице по умолчанию, если не была найдена кодировка Unicode.
- Обнаруживает (с высокой вероятностью) файлы Unicode с отсутствующей спецификацией / подписью
- Ищет charset=xyz и encoding=xyz внутри файла, чтобы определить кодировку.
- Чтобы сохранить обработку, вы можете "попробовать" файл (определенное количество байтов).
- Кодировка и декодированный текстовый файл возвращаются.
- Чисто байтовое решение для эффективности
Как уже говорили другие, ни одно решение не может быть идеальным (и, конечно, нельзя легко отличить различные 8-битные расширенные кодировки ASCII, используемые во всем мире), но мы можем стать "достаточно хорошими", особенно если разработчик также представляет пользователю список альтернативных кодировок, как показано здесь: Какая кодировка наиболее распространена для каждого языка?
Полный список кодировок можно найти с помощью Encoding.GetEncodings();
// Function to detect the encoding for UTF-7, UTF-8/16/32 (bom, no bom, little
// & big endian), and local default codepage, and potentially other codepages.
// 'taster' = number of bytes to check of the file (to save processing). Higher
// value is slower, but more reliable (especially UTF-8 with special characters
// later on may appear to be ASCII initially). If taster = 0, then taster
// becomes the length of the file (for maximum reliability). 'text' is simply
// the string with the discovered encoding applied to the file.
public Encoding detectTextEncoding(string filename, out String text, int taster = 1000)
{
byte[] b = File.ReadAllBytes(filename);
//////////////// First check the low hanging fruit by checking if a
//////////////// BOM/signature exists (sourced from http://www.unicode.org/faq/utf_bom.html#bom4)
if (b.Length >= 4 && b[0] == 0x00 && b[1] == 0x00 && b[2] == 0xFE && b[3] == 0xFF) { text = Encoding.GetEncoding("utf-32BE").GetString(b, 4, b.Length - 4); return Encoding.GetEncoding("utf-32BE"); } // UTF-32, big-endian
else if (b.Length >= 4 && b[0] == 0xFF && b[1] == 0xFE && b[2] == 0x00 && b[3] == 0x00) { text = Encoding.UTF32.GetString(b, 4, b.Length - 4); return Encoding.UTF32; } // UTF-32, little-endian
else if (b.Length >= 2 && b[0] == 0xFE && b[1] == 0xFF) { text = Encoding.BigEndianUnicode.GetString(b, 2, b.Length - 2); return Encoding.BigEndianUnicode; } // UTF-16, big-endian
else if (b.Length >= 2 && b[0] == 0xFF && b[1] == 0xFE) { text = Encoding.Unicode.GetString(b, 2, b.Length - 2); return Encoding.Unicode; } // UTF-16, little-endian
else if (b.Length >= 3 && b[0] == 0xEF && b[1] == 0xBB && b[2] == 0xBF) { text = Encoding.UTF8.GetString(b, 3, b.Length - 3); return Encoding.UTF8; } // UTF-8
else if (b.Length >= 3 && b[0] == 0x2b && b[1] == 0x2f && b[2] == 0x76) { text = Encoding.UTF7.GetString(b,3,b.Length-3); return Encoding.UTF7; } // UTF-7
//////////// If the code reaches here, no BOM/signature was found, so now
//////////// we need to 'taste' the file to see if can manually discover
//////////// the encoding. A high taster value is desired for UTF-8
if (taster == 0 || taster > b.Length) taster = b.Length; // Taster size can't be bigger than the filesize obviously.
// Some text files are encoded in UTF8, but have no BOM/signature. Hence
// the below manually checks for a UTF8 pattern. This code is based off
// the top answer at: https://stackru.com/questions/6555015/check-for-invalid-utf8
// For our purposes, an unnecessarily strict (and terser/slower)
// implementation is shown at: https://stackru.com/questions/1031645/how-to-detect-utf-8-in-plain-c
// For the below, false positives should be exceedingly rare (and would
// be either slightly malformed UTF-8 (which would suit our purposes
// anyway) or 8-bit extended ASCII/UTF-16/32 at a vanishingly long shot).
int i = 0;
bool utf8 = false;
while (i < taster - 4)
{
if (b[i] <= 0x7F) { i += 1; continue; } // If all characters are below 0x80, then it is valid UTF8, but UTF8 is not 'required' (and therefore the text is more desirable to be treated as the default codepage of the computer). Hence, there's no "utf8 = true;" code unlike the next three checks.
if (b[i] >= 0xC2 && b[i] <= 0xDF && b[i + 1] >= 0x80 && b[i + 1] < 0xC0) { i += 2; utf8 = true; continue; }
if (b[i] >= 0xE0 && b[i] <= 0xF0 && b[i + 1] >= 0x80 && b[i + 1] < 0xC0 && b[i + 2] >= 0x80 && b[i + 2] < 0xC0) { i += 3; utf8 = true; continue; }
if (b[i] >= 0xF0 && b[i] <= 0xF4 && b[i + 1] >= 0x80 && b[i + 1] < 0xC0 && b[i + 2] >= 0x80 && b[i + 2] < 0xC0 && b[i + 3] >= 0x80 && b[i + 3] < 0xC0) { i += 4; utf8 = true; continue; }
utf8 = false; break;
}
if (utf8 == true) {
text = Encoding.UTF8.GetString(b);
return Encoding.UTF8;
}
// The next check is a heuristic attempt to detect UTF-16 without a BOM.
// We simply look for zeroes in odd or even byte places, and if a certain
// threshold is reached, the code is 'probably' UF-16.
double threshold = 0.1; // proportion of chars step 2 which must be zeroed to be diagnosed as utf-16. 0.1 = 10%
int count = 0;
for (int n = 0; n < taster; n += 2) if (b[n] == 0) count++;
if (((double)count) / taster > threshold) { text = Encoding.BigEndianUnicode.GetString(b); return Encoding.BigEndianUnicode; }
count = 0;
for (int n = 1; n < taster; n += 2) if (b[n] == 0) count++;
if (((double)count) / taster > threshold) { text = Encoding.Unicode.GetString(b); return Encoding.Unicode; } // (little-endian)
// Finally, a long shot - let's see if we can find "charset=xyz" or
// "encoding=xyz" to identify the encoding:
for (int n = 0; n < taster-9; n++)
{
if (
((b[n + 0] == 'c' || b[n + 0] == 'C') && (b[n + 1] == 'h' || b[n + 1] == 'H') && (b[n + 2] == 'a' || b[n + 2] == 'A') && (b[n + 3] == 'r' || b[n + 3] == 'R') && (b[n + 4] == 's' || b[n + 4] == 'S') && (b[n + 5] == 'e' || b[n + 5] == 'E') && (b[n + 6] == 't' || b[n + 6] == 'T') && (b[n + 7] == '=')) ||
((b[n + 0] == 'e' || b[n + 0] == 'E') && (b[n + 1] == 'n' || b[n + 1] == 'N') && (b[n + 2] == 'c' || b[n + 2] == 'C') && (b[n + 3] == 'o' || b[n + 3] == 'O') && (b[n + 4] == 'd' || b[n + 4] == 'D') && (b[n + 5] == 'i' || b[n + 5] == 'I') && (b[n + 6] == 'n' || b[n + 6] == 'N') && (b[n + 7] == 'g' || b[n + 7] == 'G') && (b[n + 8] == '='))
)
{
if (b[n + 0] == 'c' || b[n + 0] == 'C') n += 8; else n += 9;
if (b[n] == '"' || b[n] == '\'') n++;
int oldn = n;
while (n < taster && (b[n] == '_' || b[n] == '-' || (b[n] >= '0' && b[n] <= '9') || (b[n] >= 'a' && b[n] <= 'z') || (b[n] >= 'A' && b[n] <= 'Z')))
{ n++; }
byte[] nb = new byte[n-oldn];
Array.Copy(b, oldn, nb, 0, n-oldn);
try {
string internalEnc = Encoding.ASCII.GetString(nb);
text = Encoding.GetEncoding(internalEnc).GetString(b);
return Encoding.GetEncoding(internalEnc);
}
catch { break; } // If C# doesn't recognize the name of the encoding, break.
}
}
// If all else fails, the encoding is probably (though certainly not
// definitely) the user's local codepage! One might present to the user a
// list of alternative encodings as shown here: https://stackru.com/questions/8509339/what-is-the-most-common-encoding-of-each-language
// A full list can be found using Encoding.GetEncodings();
text = Encoding.Default.GetString(b);
return Encoding.Default;
}
Это зависит от того, откуда взялась строка. Строка.NET - это Юникод (UTF-16). Единственный способ, которым это может отличаться, если вы, скажем, считываете данные из базы данных в байтовый массив.
Эта статья CodeProject может быть интересна: Определить кодировку для входящего и исходящего текста
Строки Джона Скита в C# и.NET - отличное объяснение строк.NET.
Я знаю, что это немного поздно - но чтобы быть ясно:
Строка на самом деле не имеет кодировки... в.NET строка представляет собой набор объектов char. По сути, если это строка, она уже была декодирована.
Однако, если вы читаете содержимое файла, состоящего из байтов, и хотите преобразовать его в строку, необходимо использовать кодировку файла.
.NET включает в себя классы кодирования и декодирования для: ASCII, UTF7, UTF8, UTF32 и других.
Большинство из этих кодировок содержат определенные метки порядка байтов, которые можно использовать, чтобы отличить, какой тип кодировки использовался.
Класс.NET System.IO.StreamReader способен определять кодировку, используемую в потоке, читая эти метки порядка байтов;
Вот пример:
/// <summary>
/// return the detected encoding and the contents of the file.
/// </summary>
/// <param name="fileName"></param>
/// <param name="contents"></param>
/// <returns></returns>
public static Encoding DetectEncoding(String fileName, out String contents)
{
// open the file with the stream-reader:
using (StreamReader reader = new StreamReader(fileName, true))
{
// read the contents of the file into a string
contents = reader.ReadToEnd();
// return the encoding.
return reader.CurrentEncoding;
}
}
Другой вариант, очень поздно, извините:
http://www.architectshack.com/TextFileEncodingDetector.ashx
Этот небольшой C#-only-класс использует BOMS, если он присутствует, пытается автоматически определить возможные кодировки Unicode в противном случае и отступает, если ни одна из кодировок Unicode невозможна или вероятна.
Похоже, что UTF8Checker, на который ссылаются выше, делает что-то похожее, но я думаю, что это немного шире по объему - вместо UTF8, он также проверяет другие возможные кодировки Unicode (UTF-16 LE или BE), в которых может отсутствовать спецификация.
Надеюсь, это поможет кому-то!
Пакет Nuget https://www.nuget.org/packages/SimpleHelpers.FileEncoding/ объединяет порт C# универсального детектора кодировки Mozilla в простой и простой API:
var encoding = FileEncoding.DetectFileEncoding(txtFile);
Мое решение состоит в том, чтобы использовать встроенные компоненты с некоторыми запасными вариантами.
Я выбрал стратегию из ответа на другой похожий вопрос по stackru, но не могу найти его сейчас.
Сначала проверяется спецификация, используя встроенную логику в StreamReader. Если спецификация есть, кодировка будет отличаться от Encoding.Defaultи мы должны доверять этому результату.
Если нет, он проверяет, является ли последовательность байтов действительной последовательностью UTF-8. если это так, он будет угадывать UTF-8 в качестве кодировки, а если нет, то снова будет получена кодировка ASCII по умолчанию.
static Encoding getEncoding(string path) {
var stream = new FileStream(path, FileMode.Open);
var reader = new StreamReader(stream, Encoding.Default, true);
reader.Read();
if (reader.CurrentEncoding != Encoding.Default) {
reader.Close();
return reader.CurrentEncoding;
}
stream.Position = 0;
reader = new StreamReader(stream, new UTF8Encoding(false, true));
try {
reader.ReadToEnd();
reader.Close();
return Encoding.UTF8;
}
catch (Exception) {
reader.Close();
return Encoding.Default;
}
}
Примечание: это был эксперимент, чтобы увидеть, как внутренне работает кодировка UTF-8. Решение, предлагаемое vilicvane, чтобы использовать UTF8Encoding Объект, который инициализируется, чтобы выдать исключение при неудачном декодировании, намного проще и в основном делает то же самое.
Я написал этот фрагмент кода, чтобы различать UTF-8 и Windows-1252. Однако его не следует использовать для гигантских текстовых файлов, поскольку он загружает все данные в память и сканирует их полностью. Я использовал его для файлов субтитров.srt, просто чтобы иметь возможность сохранить их обратно в кодировке, в которой они были загружены.
Кодировка, передаваемая функции как ref, должна быть 8-битной резервной кодировкой, которую следует использовать в случае, если файл обнаружен как недействительный UTF-8; как правило, в системах Windows это будет Windows-1252. Это не делает ничего необычного, как проверка действительных диапазонов ascii, и не обнаруживает UTF-16 даже по метке порядка байтов.
Теорию побитового обнаружения можно найти здесь: https://ianthehenry.com/2015/1/17/decoding-utf-8/
По сути, битовый диапазон первого байта определяет, сколько после него является частью объекта UTF-8. Эти байты после него всегда находятся в одном и том же диапазоне битов.
/// <summary>
/// Detects whether the encoding of the data is valid UTF-8 or ascii. If detection fails, the text is decoded using the given fallback encoding.
/// Bit-wise mechanism for detecting valid UTF-8 based on https://ianthehenry.com/2015/1/17/decoding-utf-8/
/// Note that pure ascii detection should not be trusted: it might mean the file is meant to be UTF-8 or Windows-1252 but simply contains no special characters.
/// </summary>
/// <param name="docBytes">The bytes of the text document.</param>
/// <param name="encoding">The default encoding to use as fallback if the text is detected not to be pure ascii or UTF-8 compliant. This ref parameter is changed to the detected encoding, or Windows-1252 if the given encoding parameter is null and the text is not valid UTF-8.</param>
/// <returns>The contents of the read file</returns>
public static String ReadFileAndGetEncoding(Byte[] docBytes, ref Encoding encoding)
{
if (encoding == null)
encoding = Encoding.GetEncoding(1252);
// BOM detection is not added in this example. Add it yourself if you feel like it. Should set the "encoding" param and return the decoded string.
//String file = DetectByBOM(docBytes, ref encoding);
//if (file != null)
// return file;
Boolean isPureAscii = true;
Boolean isUtf8Valid = true;
for (Int32 i = 0; i < docBytes.Length; i++)
{
Int32 skip = TestUtf8(docBytes, i);
if (skip != 0)
{
if (isPureAscii)
isPureAscii = false;
if (skip < 0)
isUtf8Valid = false;
else
i += skip;
}
// if already detected that it's not valid utf8, there's no sense in going on.
if (!isUtf8Valid)
break;
}
if (isPureAscii)
encoding = new ASCIIEncoding(); // pure 7-bit ascii.
else if (isUtf8Valid)
encoding = new UTF8Encoding(false);
// else, retain given fallback encoding.
return encoding.GetString(docBytes);
}
/// <summary>
/// Tests if the bytes following the given offset are UTF-8 valid, and returns
/// the extra amount of bytes to skip ahead to do the next read if it is
/// (meaning, detecting a single-byte ascii character would return 0).
/// If the text is not UTF-8 valid it returns -1.
/// </summary>
/// <param name="binFile">Byte array to test</param>
/// <param name="offset">Offset in the byte array to test.</param>
/// <returns>The amount of extra bytes to skip ahead for the next read, or -1 if the byte sequence wasn't valid UTF-8</returns>
public static Int32 TestUtf8(Byte[] binFile, Int32 offset)
{
Byte current = binFile[offset];
if ((current & 0x80) == 0)
return 0; // valid 7-bit ascii. Added length is 0 bytes.
else
{
Int32 len = binFile.Length;
Int32 fullmask = 0xC0;
Int32 testmask = 0;
for (Int32 addedlength = 1; addedlength < 6; addedlength++)
{
// This code adds shifted bits to get the desired full mask.
// If the full mask is [111]0 0000, then test mask will be [110]0 0000. Since this is
// effectively always the previous step in the iteration I just store it each time.
testmask = fullmask;
fullmask += (0x40 >> addedlength);
// Test bit mask for this level
if ((current & fullmask) == testmask)
{
// End of file. Might be cut off, but either way, deemed invalid.
if (offset + addedlength >= len)
return -1;
else
{
// Lookahead. Pattern of any following bytes is always 10xxxxxx
for (Int32 i = 1; i <= addedlength; i++)
{
// If it does not match the pattern for an added byte, it is deemed invalid.
if ((binFile[offset + i] & 0xC0) != 0x80)
return -1;
}
return addedlength;
}
}
}
// Value is greater than the start of a 6-byte utf8 sequence. Deemed invalid.
return -1;
}
}
Мой, наконец, работающий подход состоит в том, чтобы попробовать потенциальных кандидатов ожидаемых кодировок, обнаружив недопустимые символы в строках, созданных из массива байтов с помощью кодировок. Если я не сталкиваюсь с недопустимыми символами, я полагаю, что проверенная кодировка отлично работает для проверенных данных.
Для меня, имея только латинские и немецкие специальные символы, чтобы определить правильную кодировку для массива байтов, я пытаюсь обнаружить недопустимые символы в строке с помощью этого метода:
/// <summary>
/// detect invalid characters in string, use to detect improper encoding
/// </summary>
/// <param name="s"></param>
/// <returns></returns>
public static bool DetectInvalidChars(string s)
{
const string specialChars = "\r\n\t .,;:-_!\"'?()[]{}&%$§=*+~#@|<>äöüÄÖÜß/\\^€";
return s.Any(ch => !(
specialChars.Contains(ch) ||
(ch >= '0' && ch <= '9') ||
(ch >= 'a' && ch <= 'z') ||
(ch >= 'A' && ch <= 'Z')));
}
(Примечание: если у вас есть другие языки на основе латиницы, вы можете адаптировать константную строку specialChars в коде)
Затем я использую его так (я ожидаю только кодировку UTF-8 или кодировку по умолчанию):
// determine encoding by detecting invalid characters in string
var invoiceXmlText = Encoding.UTF8.GetString(invoiceXmlBytes); // try utf-8 first
if (StringFuncs.DetectInvalidChars(invoiceXmlText))
invoiceXmlText = Encoding.Default.GetString(invoiceXmlBytes); // fallback to default
Я нашел новую библиотеку на GitHub: https://github.com/CharsetDetector/UTF-unknown
Сборка детектора кодировки на C# - .NET Core 2-3, .NET standard 1-2 и.NET 4+
это также порт Mozilla Universal Charset Detector, основанный на других репозиториях.
https://github.com/CharsetDetector/UTF-unknown имеют класс с именемCharsetDetector.
CharsetDetector содержит некоторые методы обнаружения статической кодировки:
CharsetDetector.DetectFromFile()CharsetDetector.DetectFromStream()CharsetDetector.DetectFromBytes()
обнаруженный результат в классе DetectionResult имеет атрибут Detected который является экземпляром класса DetectionDetail с атрибутами ниже:
EncodingNameEncodingConfidence
ниже приведен пример использования:
// Program.cs
using System;
using System.Text;
using UtfUnknown;
namespace ConsoleExample
{
public class Program
{
public static void Main(string[] args)
{
string filename = @"E:\new-file.txt";
DetectDemo(filename);
}
/// <summary>
/// Command line example: detect the encoding of the given file.
/// </summary>
/// <param name="filename">a filename</param>
public static void DetectDemo(string filename)
{
// Detect from File
DetectionResult result = CharsetDetector.DetectFromFile(filename);
// Get the best Detection
DetectionDetail resultDetected = result.Detected;
// detected result may be null.
if (resultDetected != null)
{
// Get the alias of the found encoding
string encodingName = resultDetected.EncodingName;
// Get the System.Text.Encoding of the found encoding (can be null if not available)
Encoding encoding = resultDetected.Encoding;
// Get the confidence of the found encoding (between 0 and 1)
float confidence = resultDetected.Confidence;
if (encoding != null)
{
Console.WriteLine($"Detection completed: {filename}");
Console.WriteLine($"EncodingWebName: {encoding.WebName}{Environment.NewLine}Confidence: {confidence}");
}
else
{
Console.WriteLine($"Detection completed: {filename}");
Console.WriteLine($"(Encoding is null){Environment.NewLine}EncodingName: {encodingName}{Environment.NewLine}Confidence: {confidence}");
}
}
else
{
Console.WriteLine($"Detection failed: {filename}");
}
}
}
}
пример скриншота результата:
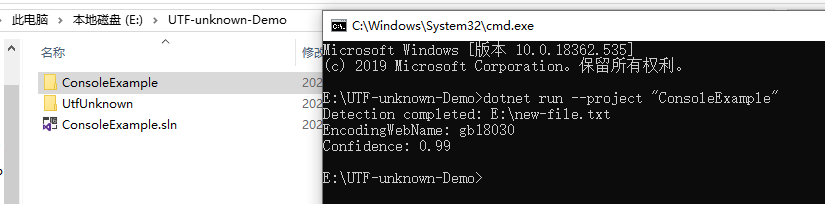
Как уже упоминалось, a в С# всегда кодируется как UTF-16LE (
System.Text.Encoding.Unicode).
Читая между строк, я считаю, что вас на самом деле беспокоит, совместимы ли ваши символы с какой-либо другой известной кодировкой (т.е. будут ли они «подходить» для этой другой кодовой страницы?).
В этом случае наиболее правильным решением, которое я нашел, является попытка преобразования и проверка изменения строки . Если персонаж в вашем
stringне "вписывается" в целевую кодировку, кодировщик заменит ее на какой-нибудь контрольный символ, который будет соответствовать (например, '?' является обычным).
// using System.Text;
// And if you're using the "System.Text.Encoding.CodePages" NuGet package, you
// need to call this once or GetEncoding will raise a NotSupportedException:
// Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
var srcEnc = Encoding.Unicode;
var dstEnc = Encoding.GetEncoding(1252); // 1252 Requires use of the "System.Text.Encoding.CodePages" NuGet package.
string srcText = "Some text you want to check";
string dstText = dstEnc.GetString(Encoding.Convert(srcEnc, dstEnc, srcEnc.GetBytes(srcText)));
// if (srcText == dstText) the srcText "fits" (it's compatible).
// else the srcText doesn't "fit" (it's not compatible)