Неэффективная схема доступа к памяти и нерегулярный доступ
Я пытаюсь оптимизировать эту функцию:
bool interpolate(const Mat &im, float ofsx, float ofsy, float a11, float a12, float a21, float a22, Mat &res)
{
bool ret = false;
// input size (-1 for the safe bilinear interpolation)
const int width = im.cols-1;
const int height = im.rows-1;
// output size
const int halfWidth = res.cols >> 1;
const int halfHeight = res.rows >> 1;
float *out = res.ptr<float>(0);
const float *imptr = im.ptr<float>(0);
for (int j=-halfHeight; j<=halfHeight; ++j)
{
const float rx = ofsx + j * a12;
const float ry = ofsy + j * a22;
#pragma omp simd
for(int i=-halfWidth; i<=halfWidth; ++i, out++)
{
float wx = rx + i * a11;
float wy = ry + i * a21;
const int x = (int) floor(wx);
const int y = (int) floor(wy);
if (x >= 0 && y >= 0 && x < width && y < height)
{
// compute weights
wx -= x; wy -= y;
int rowOffset = y*im.cols;
int rowOffset1 = (y+1)*im.cols;
// bilinear interpolation
*out =
(1.0f - wy) *
((1.0f - wx) *
imptr[rowOffset+x] +
wx *
imptr[rowOffset+x+1]) +
( wy) *
((1.0f - wx) *
imptr[rowOffset1+x] +
wx *
imptr[rowOffset1+x+1]);
} else {
*out = 0;
ret = true; // touching boundary of the input
}
}
}
return ret;
}
Я использую Intel Advisor, чтобы оптимизировать его, и хотя внутренний for уже векторизовано, советник Intel обнаружил неэффективные шаблоны доступа к памяти:
- 60% доступа к единице / нулевой шаг
- 40% нерегулярного / случайного доступа
В частности, существует четыре режима доступа (нерегулярный) в следующих трех инструкциях:
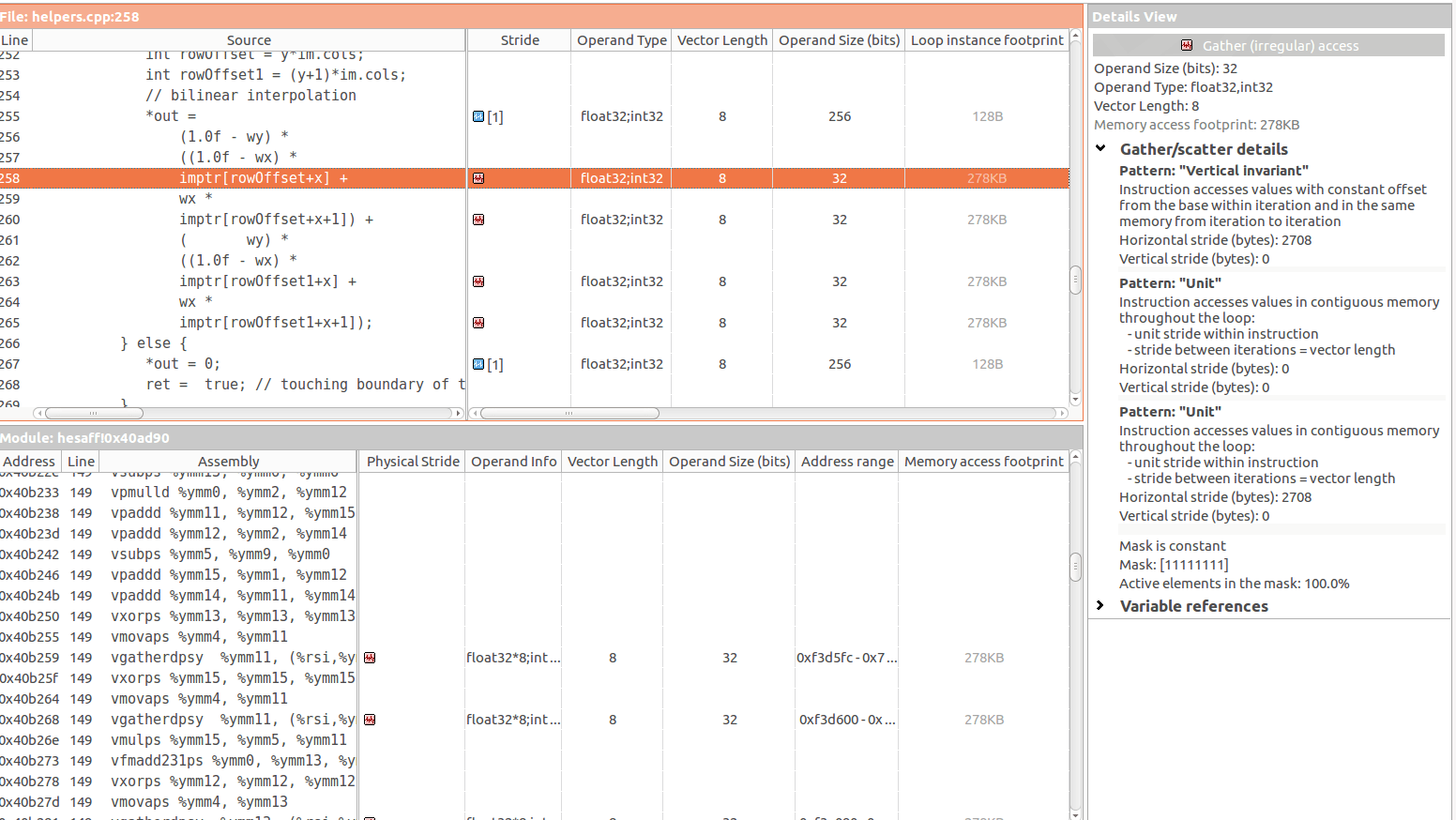
Проблема с доступом из моего понимания возникает, когда доступный элемент имеет тип a[b], где b непредсказуемо. Это похоже на случай с imptr[rowOffset+x]где оба rowOffset а также x непредсказуемы.
В то же время я вижу это Vertical Invariant что должно произойти (опять же, насколько я понимаю), когда к элементам обращаются с постоянным смещением. Но на самом деле я не вижу, где это постоянное смещение
Итак, у меня есть 3 вопроса:
- Правильно ли я понял проблему группового доступа?
- Как насчет вертикального инвариантного доступа? Я менее уверен в этом.
- Наконец, как я могу улучшить / решить доступ к памяти здесь?
Составлено с icpc 2017 обновление 3 со следующими флагами:
INTEL_OPT=-O3 -ipo -simd -xCORE-AVX2 -parallel -qopenmp -fargument-noalias -ansi-alias -no-prec-div -fp-model fast=2 -fma -align -finline-functions
INTEL_PROFILE=-g -qopt-report=5 -Bdynamic -shared-intel -debug inline-debug-info -qopenmp-link dynamic -parallel-source-info=2 -ldl
0 ответов
Векторизация (SIMD-изация) вашего кода не делает автоматически ваш шаблон доступа лучше (или хуже). Чтобы максимизировать производительность векторизованного кода, вы должны попытаться использовать шаблон доступа к памяти с единичным шагом (также называемый непрерывным, линейным, шагом-1) в вашем коде. Или, по крайней мере, "предсказуемый" обычный шаг -N, где N в идеале должно быть умеренно низким.
Не вводя такой регулярности - вы сохраняете операции LOAD/STORE в памяти частично последовательными (непараллельными) на уровне инструкций. Таким образом, каждый раз, когда вы хотите выполнить "параллельное" сложение / умножение и т. Д., Вам необходимо выполнить "сбор" "непараллельных" исходных элементов данных.
В вашем случае кажется, что есть обычный шаг-N (логически) - это видно как из фрагмента кода, так и из вывода Advisor MAP (на правой боковой панели). Вертикальный инвариант - означает, что вы иногда получаете доступ к одной и той же области памяти между итерациями. Единичный шаг означает, что в другом случае у вас есть логически непрерывный доступ к памяти.
Однако структура кода сложна: у вас есть оператор if в теле цикла, у вас есть сложные условия и преобразования с плавающей запятой в целые числа (простые, но все же).
Поэтому компилятор должен использовать наиболее общий и наиболее неэффективный метод (собирает) "на всякий случай", и в результате ваш физический, фактический шаблон доступа к памяти (из генерации кода компилятора) нерегулярный "СОБИРАЙТЕ", но логически ваш шаблон доступа является регулярным (инвариантный или единичный шаг).
Решение может быть не очень простым, но я бы попробовал следующее:
- Если алгоритм позволяет это - подумайте об исключении if-оператора. Иногда этого можно добиться, разбив цикл на несколько.
- Попробуйте использовать индукционные переменные с плавающей запятой, пол и т. Д. Попробуйте сделать их целыми числами и используйте "каноническую" форму ( for (i) array [super-simple-expression(i)] = something)
- Попробуйте использовать линейное предложение pragma simd, чтобы сообщить компилятору, что где-то действительно присутствует unit-шаг