Solrcloud и обработчик импорта данных
Я планирую обновить Solr с одного экземпляра до облачного. В настоящее время у меня есть 5 ядер, и каждое настроено с обработчиком импорта данных. Я развернул веб-приложение вместе с solr.war внутри папки tomcat, которая будет периодически запускать полный импорт и дельта-импорт в соответствии с потребностями моего проекта.
Теперь я планирую создать 2 осколка для этого приложения, сохраняя половину моих 5-ядерных данных в каждом осколке. Я не понимаю, как DIH будет работать в SolrCloud?
- Это нормально, если я начну полное индексирование с обоих шардов?
- Или мне нужно сделать полную индексацию только из одного шарда?
Архитектура будет выглядеть ниже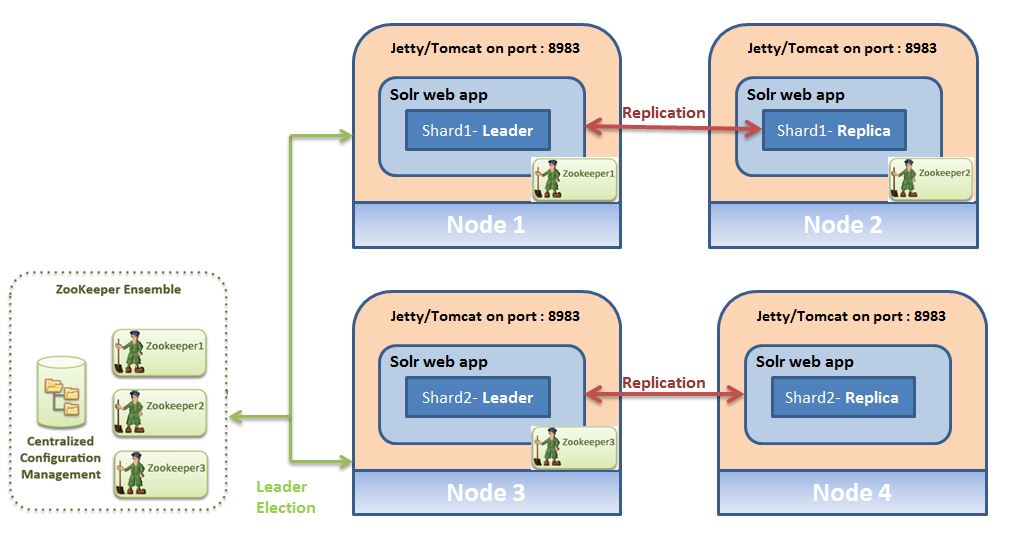
2 ответа
После долгих поисков и поисков я наконец решил использовать DIH следующим образом. Пожалуйста, дайте мне знать ваши комментарии, если вы чувствуете, что будут проблемы с этой архитектурой.
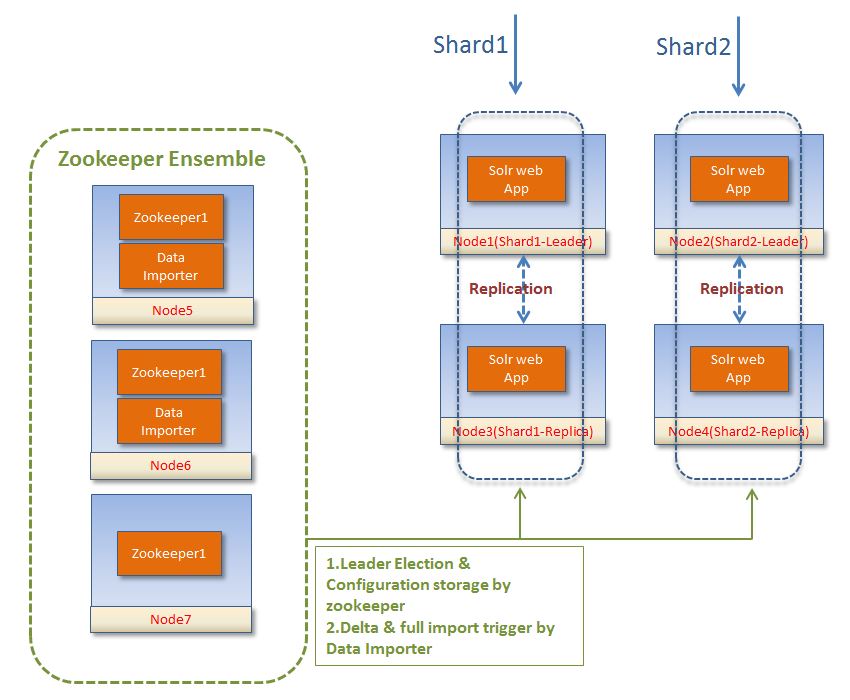
Все зависит от того, как вы создаете свое облачное решение: с использованием составного идентификатора или неявной маршрутизации. Использование составной маршрутизации идентификаторов поможет распределить документы по всем доступным осколкам. Вы можете начать импорт с любого облачного узла Solr. В итоге облачная среда будет содержать импортированные индексы документов, распределенные по всем шардам. Если вы используете неявную маршрутизацию, вы можете контролировать, где хранить индекс каждого документа. Вам не нужно использовать DIH. В качестве альтернативы вы можете написать небольшое приложение, которое использует клиент Solr для заполнения индекса, что дает вам больше контроля.