Что вызывает события производительности DTLB_LOAD_MISSES.WALK_*?
Рассмотрим следующий цикл:
.loop:
add rsi, STRIDE
mov eax, dword [rsi]
dec ebp
jg .loop
где STRIDE некоторое неотрицательное целое число и rsi содержит указатель на буфер, определенный в bss раздел. Этот цикл является единственным циклом в коде. То есть он не инициализируется и не затрагивается до цикла. В Linux все виртуальные страницы 4K буфера будут отображаться по требованию на одну и ту же физическую страницу.
Я запустил этот код для всех возможных шагов в диапазоне 0-8192. Измеренное количество мелких и главных сбоев страницы составляет ровно 1 и 0, соответственно, на страницу, к которой осуществляется доступ. Я также измерил все следующие показатели производительности на Haswell для всех успехов в этом диапазоне.
DTLB_LOAD_MISSES.MISS_CAUSES_A_WALK: промахи на всех уровнях TLB, которые вызывают просмотр страниц любого размера.
DTLB_LOAD_MISSES.WALK_COMPLETED_4K: завершенные обходы страниц из-за пропусков загрузки по требованию, которые вызывали обходы страниц 4K на любых уровнях TLB.
DTLB_LOAD_MISSES.WALK_COMPLETED_2M_4M: завершенные обходы страниц из-за пропусков загрузки по требованию, которые вызывали обходы страниц 2M/4M на любых уровнях TLB.
DTLB_LOAD_MISSES.WALK_COMPLETED_1G: Отсутствие загрузки на всех уровнях TLB вызывает завершение просмотра страницы. (1G).
DTLB_LOAD_MISSES.WALK_COMPLETED: завершенные обходы страниц в любом TLB любого размера страницы из-за пропусков загрузки по требованию
Два счетчика для огромных страниц равны нулю для всех шагов. Другие три счетчика интересны, как показано на следующем графике.
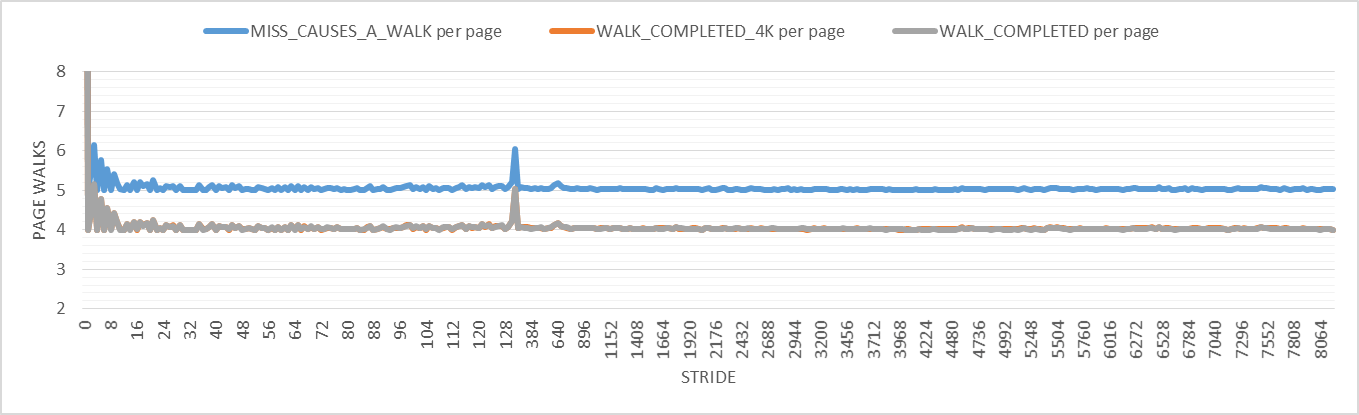
Для большинства шагов, MISS_CAUSES_A_WALK событие происходит 5 раз на страницу, к которой обращаются и WALK_COMPLETED_4K а также WALK_COMPLETED каждое событие происходит 4 раза на страницу, к которой обращаются. Это означает, что все пройденные страницы предназначены для страниц 4K. Тем не менее, есть пятая страница, которая не завершена. Почему столько страниц просматривается на странице? Что вызывает эти прогулки по страницам? Возможно, когда при просмотре страницы происходит сбой страницы, после обработки ошибки будет еще один просмотр страницы, так что это может быть засчитано как два завершенных просмотра страницы. Но как получилось, что 4 пройденных просмотра страницы и один явно отмененный переход? Обратите внимание, что на Haswell есть один обходчик страниц (по сравнению с двумя на Skylake).
Я понимаю, что есть средство предварительной выборки TLB, которое, по-видимому, способно выполнить предварительную выборку только на следующей странице, как обсуждалось в этой теме. Кроме того, в соответствии с этим потоком, прогулки с предварительной загрузкой, по-видимому, не считаются MISS_CAUSES_A_WALK или же WALK_COMPLETED_4K События.
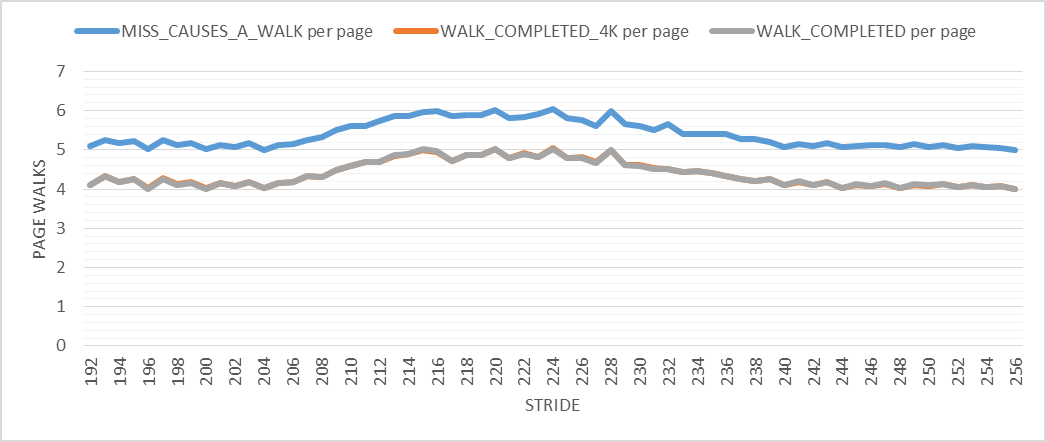
Также, как показано на графике выше, есть специальный шаблон для маленьких шагов. Кроме того, вокруг шага 220 есть очень странный паттерн (шип). Мне удалось воспроизвести эти паттерны много раз. Следующий график увеличивает этот странный паттерн, чтобы вы могли его ясно видеть. В чем причина этих моделей?
Я также экспериментировал со следующими конфигурациями:
- Передача виртуальных страниц по некоторому шаблону перед выполнением цикла. Я пробовал 4 шаблона: (1) фиксация виртуальных страниц поочередно, начиная с первой виртуальной страницы буфера, (2) фиксация виртуальных страниц поочередно, начиная со второй виртуальной страницы буфера, (3) фиксация первой половины буфер и (4) фиксация всех страниц.
- призвание
mlockall, - Отключение аппаратных предварительных загрузчиков L1 и L2
- Использование инструкции предварительной выборки вместо загрузки по требованию.
Я пришел к следующим выводам:
- Когда при просмотре страницы происходит сбой страницы из-за нагрузки по требованию,
DTLB_LOAD_MISSES.MISS_CAUSES_A_WALKсобытие происходит, но неDTLB_LOAD_MISSES.WALK_COMPLETED_4K, Когда при просмотре страницы происходит сбой страницы из-за программной предварительной выборки,DTLB_LOAD_MISSES.MISS_CAUSES_A_WALKсобытие иDTLB_LOAD_MISSES.WALK_COMPLETED_4Kсобытие происходит. Конечно, в случае предварительной выборки, сбой страницы не вызывается. - Аппаратные средства предварительной выборки влияют на события обхода страницы, но трудно увидеть какой-либо шаблон.
- Количество событий просмотра страниц, кажется, зависит от скорости загрузки нагрузки. В частности, для всех конфигураций шаги в диапазоне 128-256 приводят к наибольшему количеству событий. Это очень странно. Что такого особенного в этом диапазоне?
- Даже для простого случая, когда все страницы фиксируются перед циклом (ноль сбоев), все же есть некоторая нетривиальная (хотя и несущественная, около 1 обхода за промах TLB) подсчет событий по разным шагам. Напротив, когда все страницы неисправны, также есть небольшая разница, но количество очень различается (см. Первый график). Я не уверен, сможем ли мы сделать из этого вывод, что средство предварительной загрузки следующей страницы не влияет на события просмотра страниц.
mlockallне оказывает существенного влияния на количество событий.DTLB_LOAD_MISSES.MISS_CAUSES_A_WALKкажется, всегда больше, чемDTLB_LOAD_MISSES.WALK_COMPLETED_4K,- Сумма всех
PAGE_WALKER_LOADS.*количество событий всегда больше, чем количество просмотров страниц. Мне не понятно, как они связаны. - Так как я не знаю, как интерпретировать количество пройденных страниц, трудно интерпретировать
DTLB_LOAD_MISSES.WALK_DURATION, Но, похоже, что обход страницы занимает не менее 14 циклов. Кроме этого, я не вижу закономерностей в отношенииPAGE_WALKER_LOADS.*,
@BeeOnRope предложил разместить LFENCE в цикле и разверните его ноль или более раз, чтобы лучше понять влияние спекулятивного, не по порядку выполнения на количество событий. Следующие графики показывают результаты. Каждая строка представляет определенный шаг загрузки, когда цикл развернут 0-63 раза (1-64 пары команд добавления / загрузки в одной итерации). Ось Y нормализована для каждой страницы. Количество страниц, к которым осуществляется доступ, совпадает с количеством незначительных сбоев страниц.
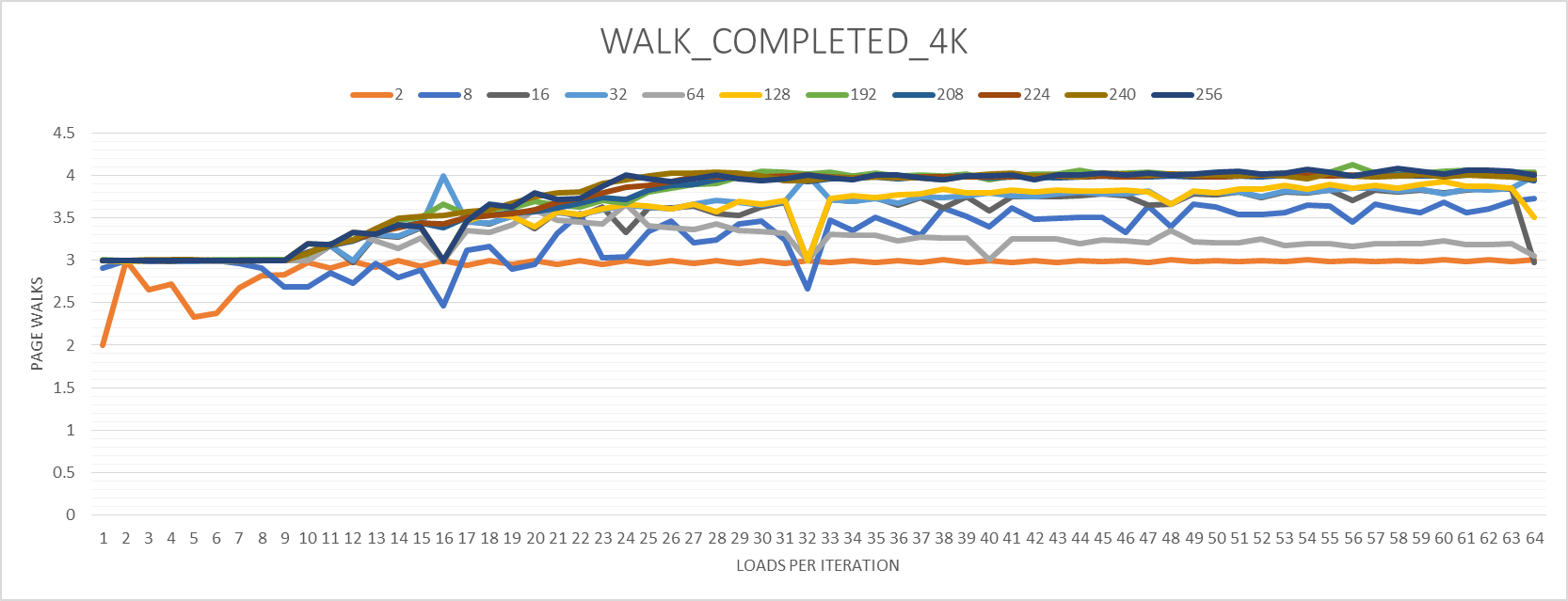

Я также запускаю эксперименты без LFENCE но с разной степенью раскатки. Я не сделал графики для них, но я рассмотрю основные различия ниже.
Мы можем сделать следующие выводы:
- Когда шаг загрузки составляет менее 128 байт,
MISS_CAUSES_A_WALKа такжеWALK_COMPLETED_4Kдемонстрируют более высокую вариацию по разным степеням раскатывания. Большие шаги имеют плавные изгибы, гдеMISS_CAUSES_A_WALKсходится к 3 или 5 иWALK_COMPLETED_4Kсходится к 3 или 4. LFENCEтолько, кажется, имеет значение, когда степень развертывания точно равна нулю (то есть, есть одна загрузка на итерацию). БезLFENCEрезультаты (как обсуждалось выше) 5MISS_CAUSES_A_WALKи 4WALK_COMPLETED_4KСобытия на странице. СLFENCE, они оба становятся 3 на страницу. Для больших степеней развертывания число событий в среднем постепенно увеличивается. Когда степень развертывания составляет, по меньшей мере, 1 (то есть, по меньшей мере, две загрузки на итерацию),LFENCEпо сути не имеет значения. Это означает, что два новых графика графиков выше для случая безLFENCEкроме случаев, когда на одну итерацию приходится одна загрузка. Кстати, странный всплеск возникает только тогда, когда степень разворачивания равна нулю и нетLFENCE,- В общем, развертывание петли уменьшает количество запускаемых и завершенных прогулок, особенно когда степень развертывания мала, независимо от того, каков шаг нагрузки. Без развертывания,
LFENCEможет быть использован, чтобы получить тот же эффект. При развертывании нет необходимости использоватьLFENCE, В любом случае время выполнения сLFENCEнамного выше. Таким образом, использование его для сокращения просмотров страниц значительно снизит производительность, а не улучшит ее.