Точечные диаграммы с массивами строк в matplotlib
Кажется, это должно быть легко, но я не могу понять это. У меня есть фрейм данных Pandas, и я хотел бы сделать трехмерную диаграмму рассеяния с 3 столбцами. Столбцы X и Y не являются числовыми, это строки, но я не понимаю, как это должно быть проблемой.
X= myDataFrame.columnX.values #string
Y= myDataFrame.columnY.values #string
Z= myDataFrame.columnY.values #float
fig = pl.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X, Y, np.log10(Z), s=20, c='b')
pl.show()
разве нет простого способа сделать это? Благодарю.
3 ответа
You could use np.unique(..., return_inverse=True) to get representative ints for each string. Например,
In [117]: uniques, X = np.unique(['foo', 'baz', 'bar', 'foo', 'baz', 'bar'], return_inverse=True)
In [118]: X
Out[118]: array([2, 1, 0, 2, 1, 0])
Обратите внимание, что X имеет тип int32, как np.unique can handle at most 2**31 unique strings.
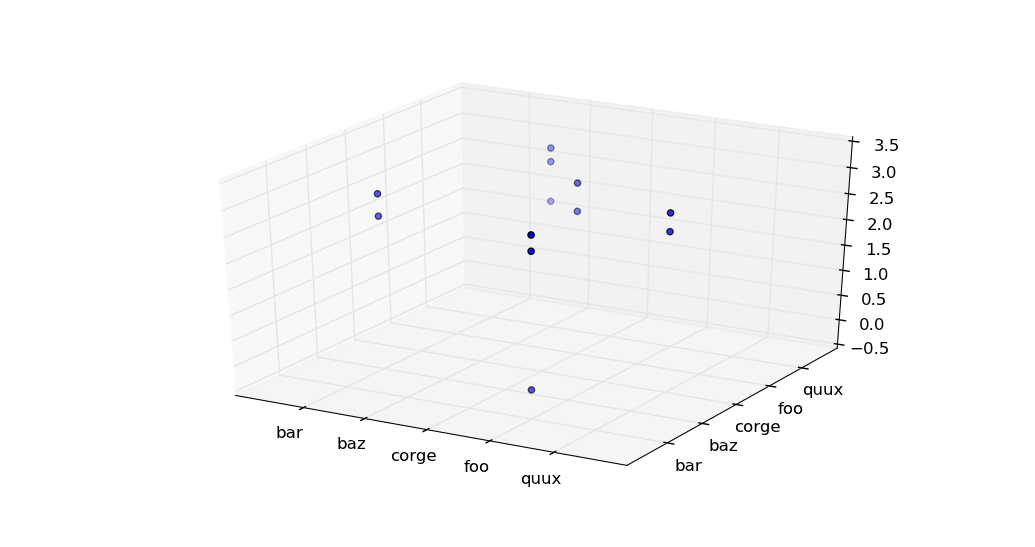
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import mpl_toolkits.mplot3d.axes3d as axes3d
N = 12
arr = np.arange(N*2).reshape(N,2)
words = np.array(['foo', 'bar', 'baz', 'quux', 'corge'])
df = pd.DataFrame(words[arr % 5], columns=list('XY'))
df['Z'] = np.linspace(1, 1000, N)
Z = np.log10(df['Z'])
Xuniques, X = np.unique(df['X'], return_inverse=True)
Yuniques, Y = np.unique(df['Y'], return_inverse=True)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1, projection='3d')
ax.scatter(X, Y, Z, s=20, c='b')
ax.set(xticks=range(len(Xuniques)), xticklabels=Xuniques,
yticks=range(len(Yuniques)), yticklabels=Yuniques)
plt.show()
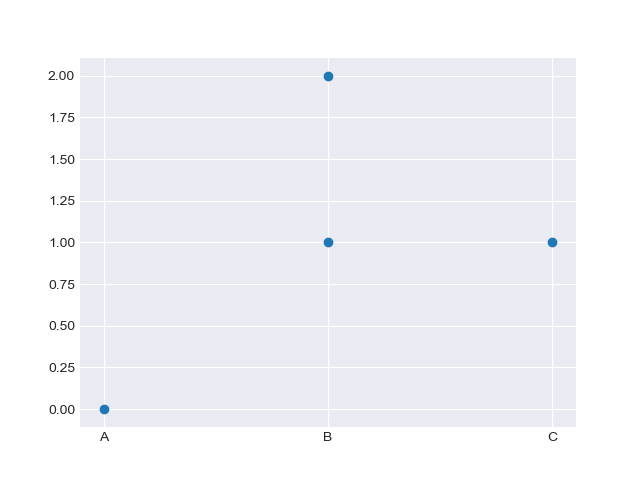
Scatter делает это автоматически сейчас:
plt.scatter(['A', 'A', 'B', 'B'], [0, 1, 0, 1])
Попробуйте преобразовать символы в числа для черчения, а затем снова используйте символы для меток оси.
Использование хэша
Вы могли бы использовать hash функция для конвертации;
from mpl_toolkits.mplot3d import Axes3D
xlab = myDataFrame.columnX.values
ylab = myDataFrame.columnY.values
X =[hash(l) for l in xlab]
Y =[hash(l) for l in xlab]
Z= myDataFrame.columnY.values #float
fig = figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X, Y, np.log10(Z), s=20, c='b')
ax.set_xticks(X)
ax.set_xticklabels(xlab)
ax.set_yticks(Y)
ax.set_yticklabels(ylab)
show()
Как указал M4rtini в комментариях, неясно, каким должен быть интервал / масштабирование строковых координат; hash функция может дать неожиданные расстояния.
Невырожденный равномерный интервал
Если вы хотите, чтобы точки были равномерно распределены, вам пришлось бы использовать другое преобразование. Например, вы могли бы использовать
X =[i for i in range(len(xlab))]
хотя это приведет к тому, что каждая точка будет иметь уникальную x-позицию, даже если метка будет одинаковой, а точки x и y будут коррелированы, если вы используете один и тот же подход для Y,
Вырожденный равномерный интервал
Третий вариант - сначала получить уникальных членов xlab (используя, например, set) и затем сопоставить каждый xlab с положением, используя уникальный набор для сопоставления; например
xmap = dict((sn, i)for i,sn in enumerate(set(xlab)))
X = [xmap[l] for l in xlab]